




 本文介绍了分布式系统中采用多级缓存的策略,包括Nginx本地缓存、分布式缓存(如Redis)和Tomcat本地缓存,分别解决了缓存热点、减少回源率及缓存失效风暴等问题。
本文介绍了分布式系统中采用多级缓存的策略,包括Nginx本地缓存、分布式缓存(如Redis)和Tomcat本地缓存,分别解决了缓存热点、减少回源率及缓存失效风暴等问题。
基本概念
所谓分布式多级缓存,就是指在整个系统的不同层级进行数据的缓存,以提升系统的访问速度。通常情况下,分布式系统的访问流程如下所示:
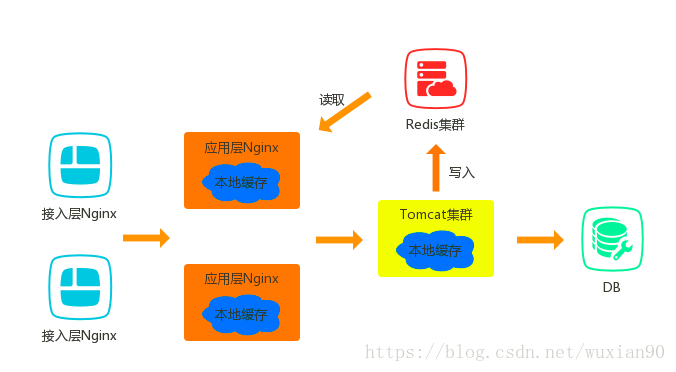
- 接入层Nginx将请求负载均衡到应用层Nginx,常用的负载均衡算法是轮询/一致性哈希。轮询可以是请求更加的平均,一致性哈希可以提升应用层Nginx的缓存命中率。
- 应用层Nginx首先访问Local Cache(Lua Shared Dict、Nginx Proxy Cache等),如果Local Cache命中,则直接返回。Nginx本地缓存应对热点问题非常有效。
- 如果Local Cache未命中,则会读取分布式缓存(如Redis)。如果命中,则返回结果,并写入应用层Nginx本地缓存。
- 如果分布式缓存未命中,则会回源到Tomcat集群。
- 此时首先读取Tomcat本地缓存,若有则返回,并异步的写入Redis集群。若无则回源到DB中去查询,然后再写入到Redis中。这里面需要注意的一点是,Tomcat的Local Cache可以有效的缓解缓存失效风暴的问题。详情请见:《分布式缓存击穿》
上述缓存主要分为了三大类:应用层Nginx本地缓存、分布式缓存、Tomcat应用服务器Local Cache。并且每一层都是用来解决不同的问题:应用层Nginx用来解决缓存热点问题;分布式缓存用来减少回源率;Tomcat本地缓存用于解决缓存失效风暴的问题。
缓存数据的方式
是否过期
不过期缓存
通常情况下我们使用缓存都会设置一个过期时间,但在某些场景下我们需要设置不过期的缓存。这个时候通常情况下是在事务结束后去写入缓存的,此时需要注意的是不要同步的去写入缓存,以免阻塞主流程。对于这种常驻缓存的数据,一定要合理的管理,一般情况下可以定期的全量更新缓存。
对于长尾缓存(缓存相对集中,但是有可能两会很大的),如以时间为维度的数据(订单/流水等),可以考虑使用LRU Cache,来使不常用的数据剔除缓存。
过期缓存
对于过期缓存,我们通常的用法是”懒加载”的方式。数据变更的时候去删除缓存,当读取数据时,缓存中没有,回源DB之后再写入缓存。这里面需要根据业务场景去设置一个合理的超时时间,对于比较热点的数据,可以根据使用场景让缓存有一定的延迟,在用户的忍受范围之内就行了(如商品库存/火车票库存等)。
细粒度缓存
对于一个电商系统,一个商品可能拆分成基础属性,图片列表、上下架、规格参数等。当商品信息变更时,此时就需要控制缓存的粒度了,尽量小成本的去更新缓存。如商品上下架,就只更新上下架维度的缓存即可。
大Value缓存
当使用Redis缓存时,应尽量避免使用大Value存储,这样会拖慢读取的速度。可以考虑的是:将其拆分为更小维度的数据,然后再组合返回前端。
热点缓存
对于热点缓存,通常情况下需要设置多级缓存,尽量避免数据通过网络去获取。当分布式缓存挂掉时,此时还需要考虑到”缓存击穿”的问题,此时可以使用白名单/布隆过滤器来作为缓存的最后一道防线。
参考:《亿级流量网站架构核心技术》
链接:http://moguhu.com/article/detail?articleId=99

















 486
486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









