




 本文介绍如何使用Python进行视频爬取,包括非VIP和VIP视频的抓取方法,利用抓包工具分析视频链接,以及使用ffmpeg进行视频片段的提取和合并。
本文介绍如何使用Python进行视频爬取,包括非VIP和VIP视频的抓取方法,利用抓包工具分析视频链接,以及使用ffmpeg进行视频片段的提取和合并。
视频的爬取----以视频《毒战》为例
前言
这是学习python以来第一次进行电影的爬取,有啥问题希望各位大佬提点。
运行平台: Windows
Python版本: Python3.7
IDE: sublime
准备工作
抓包
使用Google Chrome打开腾讯视频,打开一个非vip视频进行播放;然后F12打开开发者工具。
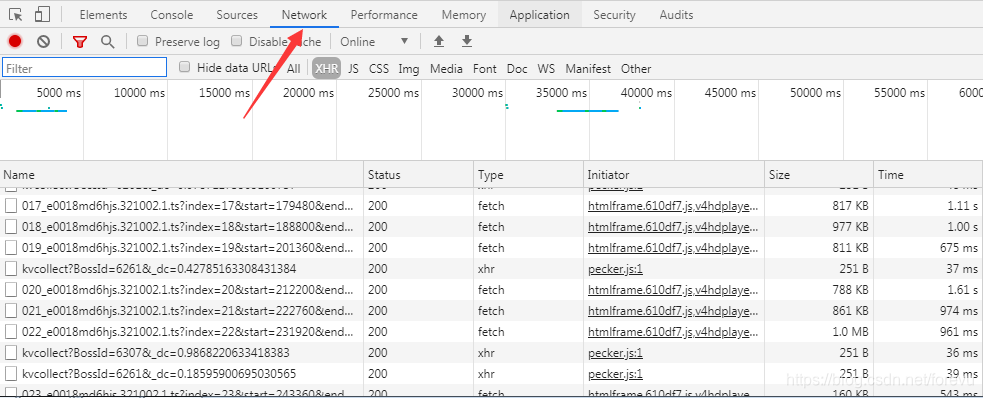
显示抓到的包,然后对抓到的包进行分析,找出视频播放的连接地址。
提取到有用的连接进行分析
https://apd-472a622e8fb43dcde14951c8eef3f74c.v.smtcdns.com/moviets.tc.qq.com/A8qV-K1xmGxXGEeY74oEpzGSylnqGeX5CK15kPPax-wg/uwMROfz2r5zAoaQXGdGnC2df644E7D3uP8M8pmtgwsRK9nEL/4TdNhK13pRGYXYTupQA0ccx_aHSV1lm6ZaY-HDUYhXWYXLcWJbloHiLA7V5nCJjAI2or26kqMM3ZritXlKuj6BKIew9ziIYmeh6cmRpODtRciLM3AV7jL47_7Oil8_kgGoE5FA_j0qKdxyni09IpfGm-v7YuyKIZZBiWifbdq-8/021_e0018md6hjs.321002.1.ts
https://apd-472a622e8fb43dcde14951c8eef3f74c.v.smtcdns.com/moviets.tc.qq.com/A8qV-K1xmGxXGEeY74oEpzGSylnqGeX5CK15kPPax-wg/uwMROfz2r5zAoaQXGdGnC2df644E7D3uP8M8pmtgwsRK9nEL/4TdNhK13pRGYXYTupQA0ccx_aHSV1lm6ZaY-HDUYhXWYXLcWJbloHiLA7V5nCJjAI2or26kqMM3ZritXlKuj6BKIew9ziIYmeh6cmRpODtRciLM3AV7jL47_7Oil8_kgGoE5FA_j0qKdxyni09IpfGm-v7YuyKIZZBiWifbdq-8/0608_e0018md6hjs.321002.20.ts
这是提取的开始的一小段视频连接地址和结束片段的视频连接地址;通过分析可以发现:只有后缀名前面的数字发生了变化,不妨假设改变该数字的大小,可以得到其中的部分片段视频。
通过实验,改变后缀前面的数值大小,可以得到其中视频片段。
程序
import requests
import os
# 判断是否存在该视频文件,不存在创建
if not os.path.exists('毒战.mp4'):
os.makedirs('毒战.mp4')
# 对视频片段进行分片段存储
for i in range(1,21):
url = f'https://apd-472a622e8fb43dcde14951c8eef3f74c.v.smtcdns.com/moviets.tc.qq.com/A8qV-K1xmGxXGEeY74oEpzGSylnqGeX5CK15kPPax-wg/uwMROfz2r5zAoaQXGdGnC2df644E7D3uP8M8pmtgwsRK9nEL/4TdNhK13pRGYXYTupQA0ccx_aHSV1lm6ZaY-HDUYhXWYXLcWJbloHiLA7V5nCJjAI2or26kqMM3ZritXlKuj6BKIew9ziIYmeh6cmRpODtRciLM3AV7jL47_7Oil8_kgGoE5FA_j0qKdxyni09IpfGm-v7YuyKIZZBiWifbdq-8/021_e0018md6hjs.321002.{i}.ts'
response = requests.get(url,headers=headers)
# 视频文件为二进制
with open('毒战.mp4','ab') as fp:
fp.write(response.content)
print(f'完成{i},正在进行{i+1}')
上面几行代码,实现一个视频的爬取。
vip视频的爬取
vip视频的爬取,借助了视频解析器对vip视频进行解析;
然后通过视频解析器获取到存放音视频的.m3u8文件的网址链接。
终端通过提供的音视频文件链接进行下载
解析网站的url=https://jx.618.com/?url='视频网址’
import requests
import re
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'
}
# 解析网站
analysis_url = 'https://jx.618g.com/?url='
# 视频网址
# vedio_url = 'https://v.youku.com/v_show/id_XMjkzNzY0NzkyOA==.html' # 速度与激情8
vedio_url = 'https://v.youku.com/v_show/id_XMjkzNzY0Mjg0OA==.html' # 速度与激情7
# 解析网址
url = analysis_url + vedio_url
# 请求
response = requests.get(url,headers=headers)
text = response.text
# 正则匹配
## 存放音视频文件的网址链接
pattern1 = re.compile(r'url=(.*?)"></iframe>')
## 视频的名字
pattern2 = re.compile(r'<title>(.*?)</title>')
res = pattern1.findall(text)[0]
title = pattern2.findall(text)[0]
# 最终使用终端进行存储的字符串
# 通过ffmpeg对m3u8文件进行音视频的提取
m3u8 = f'ffmpeg -i {res} -c copy {title}.mp4'
print(m3u8)
# 'ffmpeg -i https://sina.com-h-sina.com/20180728/1491_c02546bf/index.m3u8 -c copy 速度与激情7.mp4'
ffmpeg的安装
- 先进行文件的下载,下载符合自己电脑的版本;
- 将文件解压在合适的位置;
- 打开到bin文件目录,将bin文件目录的地址添加到环境变量中。
- 环境变量的配置:将路径地址复制到path中。
验证是否安装成功:
在Windows终端中输入:ffmpeg -version
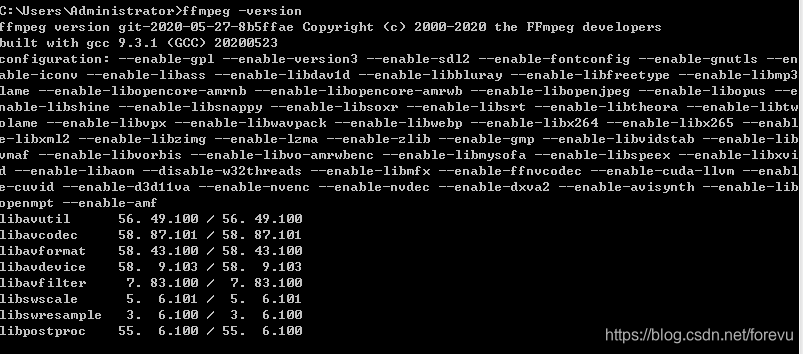
出现这样,表示安装成功
通过终端进行视频的提取
- 打开开始菜单
- 输入cmd
- 找到要存储视频文件的位置,并且到该目录下
- 直接输入程序最后运行的结构即可
- 如:'ffmpeg -i https://sina.com-h-sina.com/20180728/1491_c02546bf/index.m3u8 -c copy 速度与激情7.mp4’即可。
有啥问题,希望各位一起探讨。。。谢谢!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









