







文章目录
一、Web application Proxy (了解)
- 用于防止yarn遭受web攻击,其本身呢也是resoucemanager的一部分,也可以通过配置独立的进程运行
- ReoucemanagerWeb 是基于对守信用户的判断, 在该机制中假设所有的用户都是守信用户,当其发现连接的用户是一个非守信的用户,它就可以把该用户的连接中断,不让其去连接resourcemanager
<!-- WebAppProxy Configuration-->
<property>
<description>The kerberos principal for the proxy, if the proxy is not
running as part of the RM.</description>
<name>yarn.web-proxy.principal</name>
<value/>
</property>
<property>
<description>Keytab for WebAppProxy, if the proxy is not running as part of
the RM.</description>
<name>yarn.web-proxy.keytab</name>
</property>
<property>
<description>The address for the web proxy as HOST:PORT, if this is not
given then the proxy will run as part of the RM</description>
<name>yarn.web-proxy.address</name>
<value/>
</property>
二、如何上线和卸载节点
HDFS 节点上线与卸载
<property>
<name>dfs.hosts</name>
<value></value>
<description>Names a file that contains a list of hosts that are
permitted to connect to the namenode. The full pathname of the file
must be specified. If the value is empty, all hosts are
permitted.</description>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value></value>
<description>Names a file that contains a list of hosts that are
not permitted to connect to the namenode. The full pathname of the
file must be specified. If the value is empty, no hosts are
excluded.</description>
</property>
集群节点下线 ,对于上面的配置文件来说,如果想要设置集群节点卸载,则可以通过在在dfs.hosts.exclude属性中配置,配置将要卸载的主机名称即可,之后通过hdfs 管理命令刷新节点的状态
步骤
卸载节点
首先需要编写需要卸载的主机文件列表
在HDFS上配置dfs.hosts.exclude
完成以上两个步骤之后,执行管理命令 刷新节点状态 bin/hdfs dfsadmin -refreshNodes
卸载节点完成之后,需要把卸载节点的文件列表清空
上线节点
1. 新机器安装hadoop相关配置, ip地址,映射,JDK 免密登录 ,在主机上修改salves 文件配置该新节点的主机名称
2. 完成以上步骤之后,在新节点上启动datanode 或者 nodemanager
3. 最终再次执行bin/hdfs dfsadmin -refreshNodes 平衡节点
HDFS 分布式文件的系统
HDFS Hadoop分布式文件系统,文件就是存储文件的,常见的文件系统,windows上NTFS ,linux上的文件系统ext3 ,该HDFS文件系统被设计为运行在一些廉价的服务器上
HDFS 分布式文件的系统特点:
高容错率
可以运行在廉价的服务器上,方便横向扩展
设计的目标就是存储海量数据
1. 设计的目标
硬件错误是常态,廉价的服务器对外提供IO ,磁盘的出错率是很高的,数据的安全性要保证,默认三分副本,方便替换方案
采用流式访问,读取HDFS上的数据
设计为一个大的数据集,支持海量数据存储
设计为一个简单的模型 :文件的一次写入多次读取
移动计算比移动数据更便宜 ,统计分析,1PB mapreduce , 数据在哪 计算就就在哪? 之前的一些分布式计算,总是先把数据合并在一起,之后在进行计算,而在Hadoop 中总是先计算最后在合并
方便多种平台的可移植性
2. HDFS来源
HDFS来源自Google的论文GFS ,HDFS是GFS的克隆版

3. NameNode 架构
Namenode是一个中心服务器,负责管理文件系统,命名空间,元数据,客户端访问HDFS 首先找到namenode, 被设计成一个单一节点
文件的操作: namenode负责元数据文件的操作,datanode负责文件内容的读写
HDFS文件的写入流程
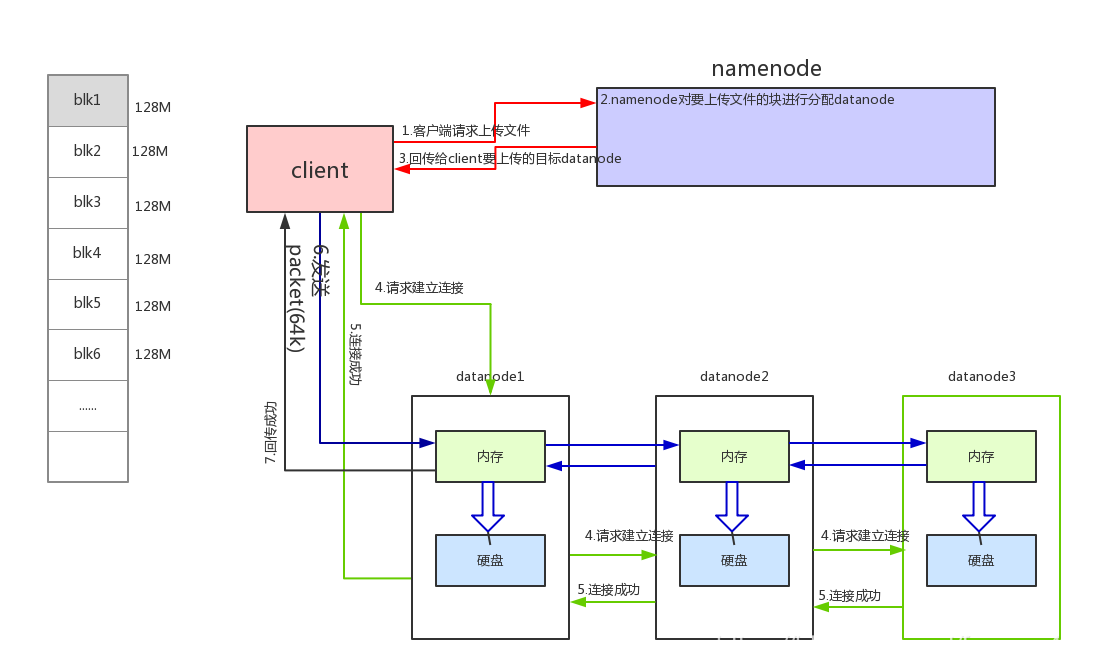
要求: 作业把HDFS写入的流程图 转换为文字,明天默写,加画图
4. DataNode
一个数据块在datanode上是以文件形式存储在磁盘上的,包括了两个文件,一个数据本身,一个是元数据包 包括数据块的长度,,数据块的校验和,由于HDFS上的数据是不允许被重复上传的所以在上传之前会对上传的数据进行检查 ,时间戳
DataNode启动后会向nameNode进行注册,通过后,会周期性的向namenode包括自己的datanode上的块信息
心跳报告,每3秒中向nmaeNode进行汇报,心跳的返回结果中带有NameNode 带给该datanode复制数据块,移动数据块的命令, 如果说超过了10分钟datanode没有响应 ,则就会任务这个datanode节点不可用,会选择其他的机器
文件: 文件在HDFS上是被切分成块的,每个块有多个副本,存储在不同的节点上,副本的默认值是3份
5.HDFS副本复制策略讲解
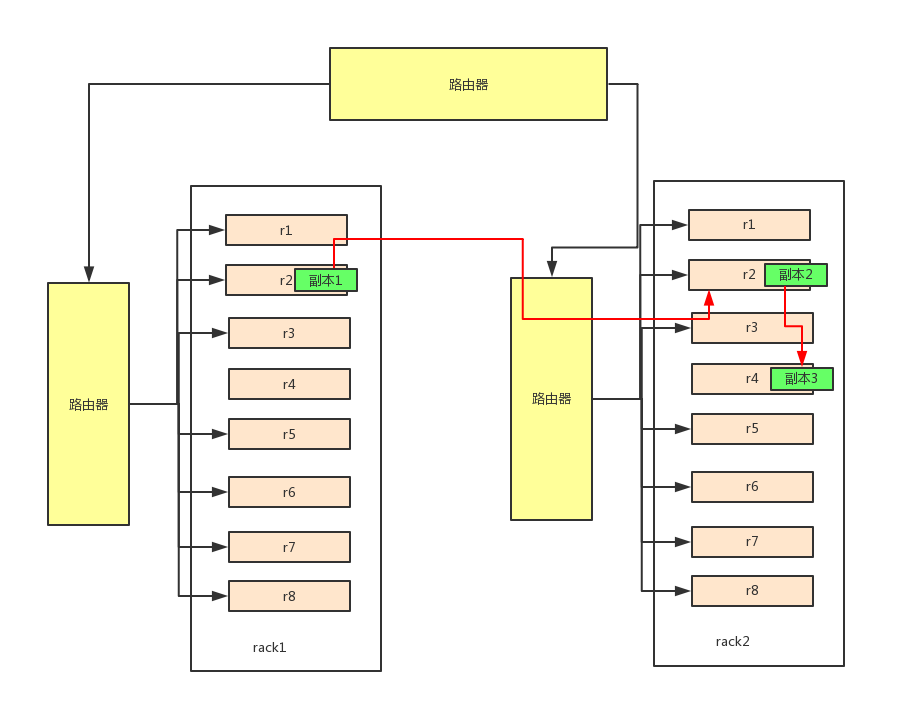
网络拓扑
服务通信速度的计算,是以网线的根数计算传输速率,在同机架中,不同的服务器传输速率都为2,在不同的机架中,不同的服务器传输速率为4
副本策略
假设副本为3份,如果客户端在集群上,发出了写的请求,则第一份副本就存在客户端的服务器上,如果客户端不在集群中,则第一份负责存放在随机的一个节点中
第二份副本为了处于安全的考虑存放在不同机架上的随机节点上
第三份副本则再和第二份副本相同机架上的随机节点中/

















 3690
3690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









