






知乎:AIQL (已授权)
链接:https://zhuanlan.zhihu.com/p/20585825634在本文中,我们将深入探讨Deepseek采用的策略优化方法GRPO,并顺带介绍一些强化学习(Reinforcement Learning, RL)的基础知识,包括PPO等关键概念。
策略函数(policy)
在强化学习中, 表示在状态 下采取动作 的条件概率。具体来说,它是由策略函数 决定的。
详细说明
表示在时间步 时的状态(state)。
状态是环境对智能体的当前描述,例如在游戏中可能是角色的位置、速度等信息。
表示在时间步 时智能体采取的动作(action)。
动作是智能体在给定状态下可以执行的操作,例如在游戏中可能是“向左移动”或“跳跃”。
是策略函数(policy),表示在状态 下选择动作 的概率。
如果是确定性策略, 会直接输出一个确定的动作;如果是随机策略,它会输出一个动作的概率分布。
在 PPO 中, 是新策略 和旧策略 在状态 下选择动作 的概率比。
这个比值用于衡量策略更新的幅度,并通过裁剪机制限制其变化范围,确保训练的稳定性。
举例说明
假设我们有一个简单的游戏环境:
状态 :角色的位置。
动作 :可以执行的动作是“向左”或“向右”。
策略 :在某个位置 下,策略可能以 70% 的概率选择“向左”,以 30% 的概率选择“向右”。
在 PPO 中,我们会比较新旧策略在相同状态 下选择相同动作 的概率,从而计算概率比 ,并用于优化目标函数。
总结
表示在状态 下选择动作 的条件概率,由策略函数 决定。在 PPO 中,这一概率用于计算新旧策略的比值,从而控制策略更新的幅度。
近端策略优化(PPO)
PPO(Proximal Policy Optimization) 是一种用于强化学习的策略优化算法,由 OpenAI 提出。它通过限制策略更新的幅度,确保训练过程的稳定性。
核心思想
PPO 的核心在于限制策略更新的幅度,避免因更新过大导致性能下降。它通过引入“裁剪”机制,控制新旧策略之间的差异。
公式
PPO 的替代目标函数 用于优化策略 ,公式如下:
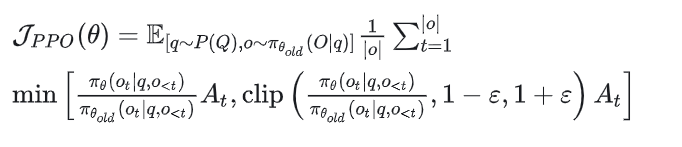
其中:
期望符号 表示对查询 和输出 的期望:
: 查询 从分布 中采样。
: 输出 由旧策略 生成。
对输出 的每个时间步 求平均:
是输出序列的长度。
其核心目标函数为:
其中:
是新旧策略的概率比。
是优势函数,衡量动作的相对好坏。
是裁剪参数,通常为 0.1 或 0.2。
步骤
采样:使用当前策略与环境交互,收集数据,在语言模型中,可以类比为生成补全(generating completions)。
计算优势值:基于收集的数据计算优势值函数 。
优化目标函数:通过梯度上升优化目标函数 。
更新策略:重复上述步骤,直到策略收敛。
优点
稳定性:通过裁剪机制,避免策略更新过大。
高效性:相比 TRPO,PPO 实现更简单,计算效率更高。
补充
在强化学习中,策略的目标是最大化期望回报,而不是最小化损失。所以,在PPO中使用的是梯度上升,原因在于它的优化目标是最大化目标函数(如强化学习中的期望回报),而不是最小化损失函数(如分类或回归问题)。
Advantage(优势函数)
定义
Advantage函数用于衡量在某个状态(State)下,采取某个动作(Action)相对于平均表现的优劣程度。它的数学定义为: , 其中:
是动作值函数,表示在状态 下采取动作 后,未来累积回报的期望。
是状态值函数,表示在状态 下,按照当前策略采取动作后,未来累积回报的期望。
是优势函数,表示在状态 下采取动作 比平均表现好多少(或差多少)。
作用
Advantage函数用于指导策略更新:
如果 ,说明动作 比平均表现更好,策略应该更倾向于选择这个动作;
如果 ,说明动作 比平均表现更差,策略应该减少选择这个动作的概率。
在PPO等算法中,Advantage函数通常通过GAE(Generalized Advantage Estimation)来估计。
直观理解
Advantage函数就像一个“评分”,告诉模型某个动作在当前状态下是好还是坏,以及好(或坏)的程度。
KL Penalty(KL散度惩罚)
定义
KL Penalty是基于KL散度(Kullback-Leibler Divergence)的一种正则化手段。KL散度用于衡量两个概率分布之间的差异。在强化学习中,KL Penalty通常用于限制当前策略 和参考策略 之间的差异。其数学定义为: 其中:
是当前策略(由模型参数 决定)。
是参考策略(通常是更新前的策略或某个基线策略)。
是KL散度,用于衡量两个策略之间的差异。
作用
KL Penalty用于防止策略更新过大,确保当前策略不会偏离参考策略太远。这样可以避免训练过程中的不稳定现象(如策略崩溃)。
在PPO等算法中,KL Penalty通常被添加到目标函数中,作为正则化项。
直观理解
KL Penalty就像一个“约束”,告诉模型在更新策略时不要“步子迈得太大”,以免失去稳定性。
Advantage和KL Penalty的关系
Advantage 用于指导策略更新,告诉模型哪些动作更好。
KL Penalty 用于约束策略更新,防止策略变化过大。
在PPO等算法中,Advantage和KL Penalty共同作用,既鼓励模型选择更好的动作,又确保更新过程稳定可靠。
举例说明
假设我们训练一个机器人走迷宫:
Advantage:机器人发现“向右转”比“向左转”更容易找到出口,于是Advantage函数会给“向右转”一个正的值,鼓励策略更倾向于选择“向右转”。
KL Penalty:为了防止策略突然变得只选择“向右转”而忽略其他可能性,KL Penalty会限制策略的变化幅度,确保策略更新是平滑的。
总结
Advantage(优势函数):衡量某个动作比平均表现好多少,用于指导策略更新。
KL Penalty(KL散度惩罚):限制策略更新的幅度,确保训练过程的稳定性。
群体相对策略优化(GRPO)
GRPO 是一种在线学习算法(online learning algorithm),这意味着它通过使用训练过程中由训练模型自身生成的数据来迭代改进。GRPO 的目标直觉是最大化生成补全(completions)的优势函数(advantage),同时确保模型保持在参考策略(reference policy)附近。
其目标函数为:
为了理解 GRPO 的工作原理,可以将其分解为四个主要步骤:
生成补全(Generating completions)
计算优势值(Computing the advantage)
估计KL散度(Estimating the KL divergence)
计算损失(Computing the loss)
1. 生成补全(Generating completions)
在每一个训练步骤中,我们从提示(prompts)中采样一个批次(batch),并为每个提示生成一组 个补全(completions)(记为 )。
2. 计算优势值(Computing the advantage)
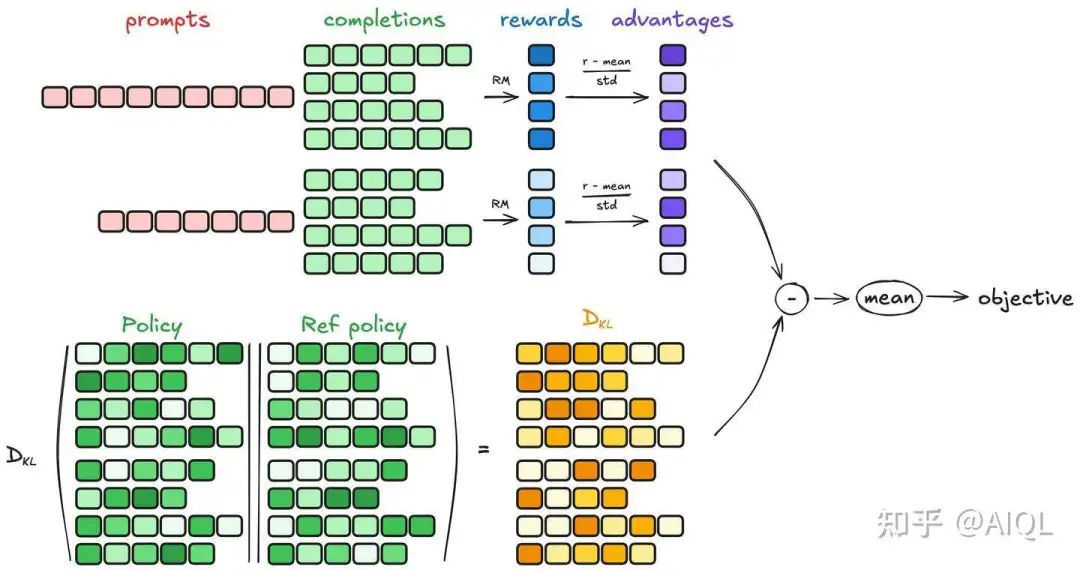
对于每一个 序列,使用奖励模型(reward model)计算其奖励(reward)。为了与奖励模型的比较性质保持一致——通常奖励模型是基于同一问题的输出之间的比较数据集进行训练的——优势的计算反映了这些相对比较。其归一化公式如下:
这种方法赋予了该方法其名称:群体相对策略优化(Group Relative Policy Optimization, GRPO)
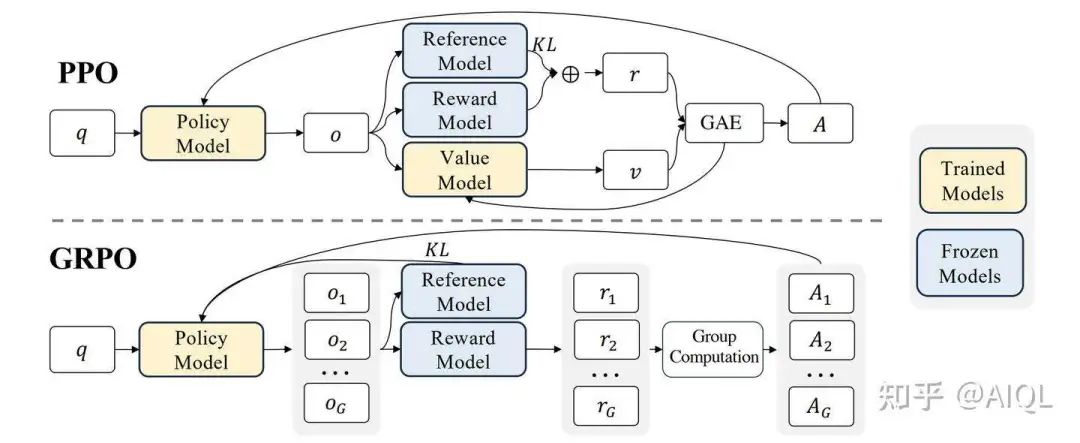
GRPO通过优化PPO算法,解决了计算优势值时需要同时依赖奖励模型(reward model)和价值模型(value model)的问题,成功移除了value model(价值模型),显著降低了推理时的内存占用和时间开销。Advantage(优势值)的核心价值在于为模型输出提供更精准的评估,不仅衡量答案的绝对质量,还通过相对比较(与其他回答的对比)来更全面地定位其优劣。
3. 估计KL散度(Estimating the KL divergence)
在实际算法实现中,直接计算KL散度可能会面临一些挑战:
计算复杂度高:KL散度的定义涉及对两个概率分布的对数比值的期望计算。对于复杂的策略分布,直接计算KL散度可能需要大量的计算资源;
数值稳定性:在实际计算中,直接计算KL散度可能会遇到数值不稳定的问题,尤其是当两个策略的概率分布非常接近时,对数比值可能会趋近于零或无穷大。近似器可以通过引入一些数值稳定性的技巧(如截断或平滑)来避免这些问题;
在线学习:在强化学习中,策略通常需要在每一步或每几步更新一次。如果每次更新都需要精确计算KL散度,可能会导致训练过程变得非常缓慢。近似器可以快速估计KL散度,从而支持在线学习和实时更新。
Approximating KL Divergence 提出的近似器可以根据当前策略和参考策略的差异动态调整估计的精度,从而在保证计算效率的同时,尽可能减少估计误差,其定义如下:
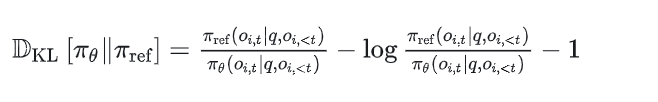
这个近似器的核心思想是通过对当前策略和参考策略的概率比值的简单变换来估计KL散度。具体来说:
第一项: 是参考策略与当前策略的概率比值。
第二项: 是对数概率比值。
第三项: 是一个常数项,用于调整近似器的偏差。
这个近似器的优势在于它只需要计算当前策略和参考策略的概率比值,而不需要直接计算KL散度的积分或期望。因此,它可以在保证一定精度的同时,显著降低计算复杂度。
近似器的直观理解
这个近似器的设计灵感来自于泰勒展开。KL散度可以看作是两个分布之间的某种“距离”,而这个近似器通过一阶或二阶近似来估计这个距离。具体来说:
当 和 非常接近时,,此时 ,近似器的值趋近于零,符合KL散度的性质。
当 和 差异较大时,近似器会给出一个较大的正值,反映出两个分布之间的差异。
4. 计算损失(Computing the loss)
这一步的目标是最大化优势,同时确保模型保持在参考策略附近。因此,损失定义如下:
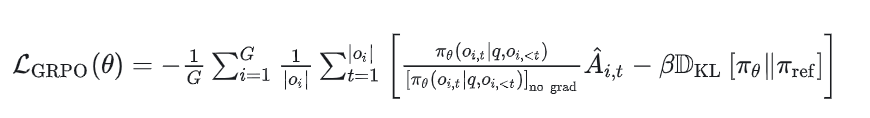
其中第一项表示缩放后的优势,第二项通过KL散度惩罚与参考策略的偏离。
在原始论文中,该公式被推广为在每次生成后通过利用裁剪替代目标(clipped surrogate objective)进行多次更新:
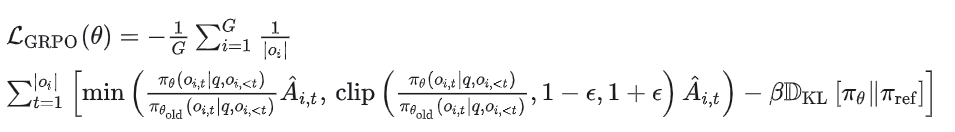
其中 通过将策略比率限制在 和 之间,确保更新不会过度偏离参考策略。
在很多代码实现,比如Huggingface的TRL中,与原始论文一样每次生成只进行一次更新,因此可以将损失简化为第一种形式。
总结
GRPO通过优化PPO算法,移除了价值模型,降低了计算开销,同时利用群体相对优势函数和KL散度惩罚,确保策略更新既高效又稳定。
想象一下,你是个销售员,这个月业绩10万块,PPO算法就像个精明的老会计,拿着算盘噼里啪啦一顿算,考虑市场行情、产品类型,最后得出结论:“嗯,这10万还算靠谱,但GAE一算,发现你的优势值还不够高,还得再加把劲啊”
而GRPO呢,就像老板直接搞了个“内卷大赛”,把所有销售员拉到一个群里,每天晒业绩:“你10万,他15万,她20万……”老板还时不时发个红包,刺激大家继续卷。你的10万块在群里瞬间被淹没,老板摇摇头:“你这水平,还得加把劲啊!”
GRPO这招绝了,它把PPO的“算盘”扔了,省了不少计算功夫,直接搞“内卷PK”,用KL散度惩罚来确保大家别躺平。这样一来,策略更新既快又稳,老板再也不用担心有人摸鱼了,毕竟大家都在拼命卷,谁敢松懈?
写在最后
总结一下:PPO是“单打独斗看实力”,GRPO是“内卷大赛拼到死”,最后GRPO还省了算盘钱,老板笑得合不拢嘴,而我们只能默默加班,继续卷。
PS:看到这里,如果觉得不错,可以来个点赞、在看、关注。 给公众号添加【星标⭐️】不迷路!您的支持是我坚持的最大动力!
欢迎多多关注公众号「NLP工作站」,加入交流群(3群也满了,等开4群吧),交个朋友吧,一起学习,一起进步!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









