




文章目录
一. 概览
- DDP的原理?
在分类上,DDP属于Data Parallel。简单来讲,就是通过提高batch size来增加并行度。 - 为什么快?
DDP通过Ring-Reduce的数据交换方法提高了通讯效率,并通过启动多个进程的方式减轻Python GIL的限制,从而提高训练速度。 - DDP有多快?
一般来说,DDP都是显著地比DP快,能达到略低于卡数的加速比(例如,四卡下加速3倍)。所以,其是目前最流行的多机多卡训练方法。
二. 使用DDP一个简单例子
2.1 依赖
PyTorch(gpu)>=1.5,python>=3.6
2.2 环境准备
推荐使用官方打好的PyTorch docker,避免乱七八糟的环境问题影响心情。
# Dockerfile
# Start FROM Nvidia PyTorch image https://ngc.nvidia.com/catalog/containers/nvidia:pytorch
FROM nvcr.io/nvidia/pytorch:20.03-py3
2.3 代码
2.3.1 单GPU代码
## main.py文件
import torch
# 构造模型
model = nn.Linear(10, 10).to(local_rank)
# 前向传播
outputs = model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
loss_fn = nn.MSELoss()
loss_fn(outputs, labels).backward()
# 后向传播
optimizer = optim.SGD(model.parameters(), lr=0.001)
optimizer.step()
Bash终端运行
python main.py
2.3.2 加入DDP代码
## main.py文件
import torch
# 新增:
import torch.distributed as dist
# 新增:从外面得到local_rank参数
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", default=-1)
FLAGS = parser.parse_args()
local_rank = FLAGS.local_rank
# 新增:DDP backend初始化
torch.cuda.set_device(local_rank)
dist.init_process_group(backend='nccl') # nccl是GPU设备上最快、最推荐的后端
# 构造模型
device = torch.device("cuda", local_rank)
model = nn.Linear(10, 10).to(device)
# 新增:构造DDP model
model = DDP(model, device_ids=[local_rank], output_device=local_rank)
# 前向传播
outputs = model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
loss_fn = nn.MSELoss()
loss_fn(outputs, labels).backward()
# 后向传播
optimizer = optim.SGD(model.parameters(), lr=0.001)
optimizer.step()
Bash终端运行
# 改变:使用torch.distributed.launch启动DDP模式,
# 其会给main.py一个local_rank的参数。这就是之前需要"新增:从外面得到local_rank参数"的原因
python -m torch.distributed.launch --nproc_per_node 4 main.py
三. 基本原理
假如我们有N张显卡,
- (缓解GIL限制)在DDP模式下,会有N个进程被启动,每个进程在一张卡上加载一个模型,这些模型的参数在数值上是相同的。
- (Ring-Reduce加速)在模型训练时,各个进程通过一种叫Ring-Reduce的方法与其他进程通讯,交换各自的梯度,从而获得所有进程的梯度;
- (实际上就是Data Parallelism)各个进程用平均后的梯度更新自己的参数,因为各个进程的初始参数、更新梯度是一致的,所以更新后的参数也是完全相同的。
3.1 DDP与DP模式的不同
DP模式是很早就出现的、单机多卡的、参数服务器架构的多卡训练模式,在PyTorch,即是:
model = torch.nn.DataParallel(model)
在DP模式中,总共只有一个进程(受到GIL很强限制)。master节点相当于参数服务器,其会向其他卡广播其参数;在梯度反向传播后,各卡将梯度集中到master节点,master节点对搜集来的参数进行平均后更新参数,再将参数统一发送到其他卡上。这种参数更新方式,会导致master节点的计算任务、通讯量很重,从而导致网络阻塞,降低训练速度。但是DP也有优点,优点就是代码实现简单,实现比较方便;而DDP速度比较快,代码实现比较复杂。
四. DDP为什么能加速
4.1 Python GIL
Python GIL 最大的特征(缺点):Python GIL的存在使得,一个python进程只能利用一个CPU核心,不适合用于计算密集型的任务。
而只有使用多进程,才能有效率利用多核的计算资源。而DDP启动多进程训练,一定程度地突破了这个限制。
4.2 Ring-Reduce梯度合并
Ring-Reduce是一种分布式程序的通讯方法。 因为提高通讯效率,Ring-Reduce比DP的parameter server快。其避免了master阶段的通讯阻塞现象,n个进程的耗时是o(n)。
简单说明:
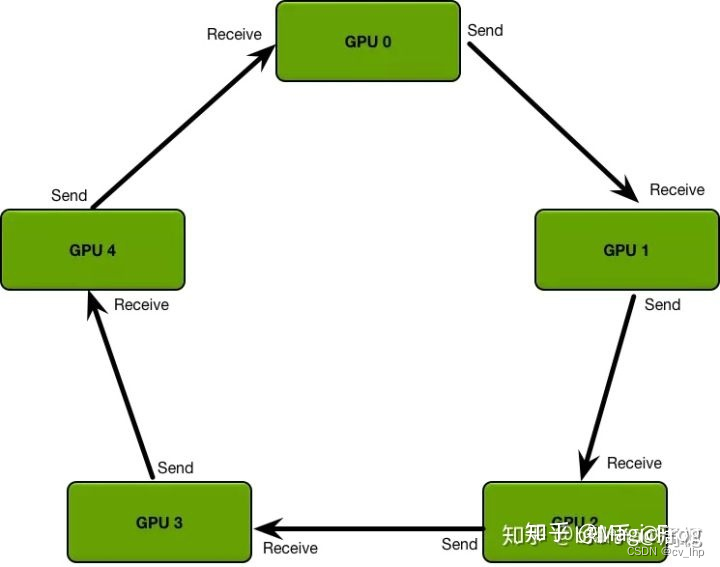
- 各进程独立计算梯度。
- 每个进程将梯度依次传递给下一个进程,之后再把从上一个进程拿到的梯度传递给下一个进程。循环n次(进程数量)之后,所有进程就可以得到全部的梯度了。
- 可以看到,每个进程只跟自己上下游两个进程进行通讯,极大地缓解了参数服务器的通讯阻塞现象!
五. 并行计算
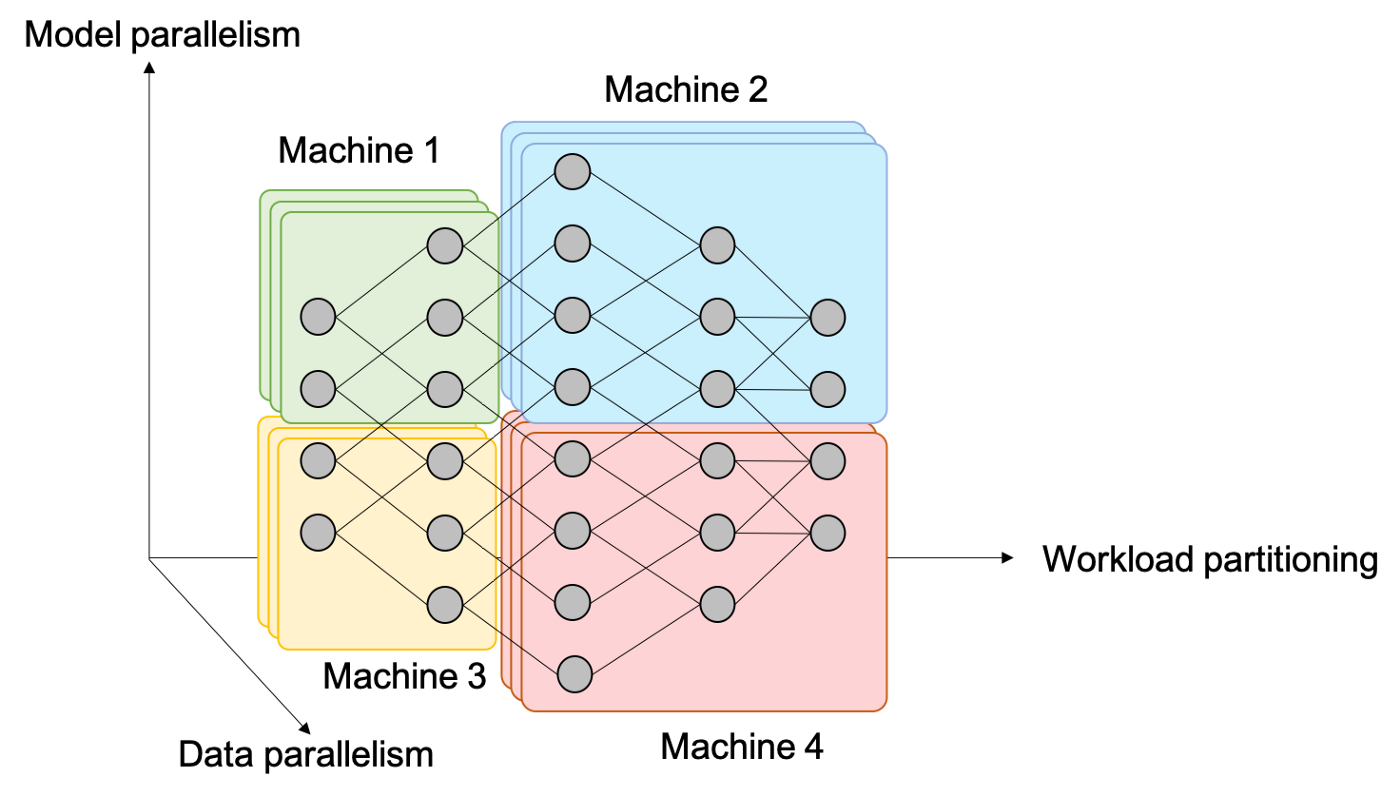
统一来讲,神经网络中的并行有以下三种形式,如下图所示:
5.1 Data Parallelism:
- 这是最常见的形式,通俗来讲,就是增大batch size。
- 平时我们看到的多卡并行就属于这种。比如DP、DDP都是。这能让我们方便地利用多卡计算资源。
- 能加速。
5.2 Model Parallelism:
- 把模型放在不同GPU上,计算是并行的。
- 有可能是加速的,看通讯效率。
5.3 Workload Partitioning:
- 把模型放在不同GPU上,但计算是串行的。
- 不能加速。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 697
697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









