<think>我们有一个INSERT INTO语句,它使用MINUS操作符来筛选数据并插入到目标表DM_DATAHUB.DM_materials_diff_price_t_new中。
现在需要将这个INSERT INTO语句转换为MERGE INTO语法。
通常,INSERT INTO ... SELECT ... MINUS ... 的结构可以转换为MERGE INTO的INSERT部分(WHEN NOT MATCHED THEN INSERT)。
但是,由于MINUS操作符会返回第一个查询中存在而第二个查询中不存在的行,我们可以将其理解为:在目标表中不存在的记录(根据MINUS的条件)才进行插入。
在MERGE INTO中,我们可以这样处理:
- 将MINUS之前的查询作为源数据(USING子句)
- 将MINUS之后的查询作为目标表中已经存在的数据,然后通过关联条件来判断源数据中哪些行在目标表中不存在。
但是,需要注意的是,MINUS操作符会去重,而MERGE INTO中我们通常使用关联条件来匹配。因此,我们需要在关联条件中指定所有需要比较的列,以确保能够正确判断数据是否已经存在。
假设原始的INSERT语句类似于:
INSERT INTO DM_DATAHUB.DM_materials_diff_price_t_new (col1, col2, ...)
SELECT col1, col2, ...
FROM table1
MINUS
SELECT col1, col2, ...
FROM DM_DATAHUB.DM_materials_diff_price_t_new;
这个语句的含义是:从table1中选取不在目标表中的记录(所有列都相同的记录)插入到目标表。
在MERGE INTO中,我们可以这样转换:
MERGE INTO DM_DATAHUB.DM_materials_diff_price_t_new T
USING (
SELECT col1, col2, ...
FROM table1
MINUS
SELECT col1, col2, ...
FROM DM_DATAHUB.DM_materials_diff_price_t_new
) S
ON (T.col1 = S.col1 AND T.col2 = S.col2 AND ...)
WHEN NOT MATCHED THEN
INSERT (col1, col2, ...) VALUES (S.col1, S.col2, ...);
但是,这个写法实际上并没有避免重复,因为我们在USING子句中已经通过MINUS去除了目标表中已经存在的记录,所以ON子句实际上不会匹配到任何记录(因为S中已经去除了目标表已有的记录),因此所有S中的记录都会被插入。这样写虽然可以,但效率可能不高,因为MINUS操作需要全表比较两次。
另一种更高效的方法是:我们不需要在USING子句中使用MINUS,而是直接用源表与目标表进行关联,然后只插入那些在目标表中没有匹配的记录。这样就不需要MINUS操作了。
因此,我们可以将原始INSERT语句转换为:
MERGE INTO DM_DATAHUB.DM_materials_diff_price_t_new T
USING (
SELECT col1, col2, ...
FROM table1
) S
ON (T.col1 = S.col1 AND T.col2 = S.col2 AND ... [所有列都参与比较] )
WHEN NOT MATCHED THEN
INSERT (col1, col2, ...) VALUES (S.col1, S.col2, ...);
注意:这里ON条件中需要列出所有需要比较的列(即原始MINUS中比较的所有列),因为MINUS是基于所有列的比较。
但是,如果原始MINUS语句中只选择了部分列,那么我们需要在ON子句中用这些列进行匹配。
然而,我们注意到原始问题中有一个示例关联条件,涉及多个字段(如T.BG=S.BG, T.BU=S.BU等共16个字段)。因此,我们可以推断,在转换时,需要将原始INSERT语句中SELECT子句的所有列都作为ON子句的关联条件。
步骤:
1. 确定原始INSERT语句中SELECT子句的列列表(即MINUS之前的SELECT的列)。
2. 在MERGE INTO的ON子句中,使用这些列进行等值匹配(T.col1=S.col1, T.col2=S.col2, ...)。
3. 在WHEN NOT MATCHED THEN INSERT部分,插入这些列。
但是,需要注意:如果目标表中存在与源表中某行部分列相同但其他列不同的情况,那么MINUS操作会将该行保留(因为所有列不完全相同),而MERGE INTO的ON子句如果只用了部分列进行匹配,则可能导致错误匹配。因此,我们必须确保ON子句中包含所有需要比较的列。
因此,转换后的MERGE INTO语句结构为:
MERGE INTO DM_DATAHUB.DM_materials_diff_price_t_new T
USING (源表查询) S
ON (T.列1 = S.列1 AND T.列2 = S.列2 AND ...) -- 这里列的数量和顺序与SELECT子句中的列一致
WHEN NOT MATCHED THEN
INSERT (列1, 列2, ...)
VALUES (S.列1, S.列2, ...);
由于原始INSERT语句中使用了MINUS,而MINUS要求两个查询的列数相同且对应列的数据类型兼容,因此我们在MERGE INTO的USING子句中直接使用MINUS之前的查询即可,而ON子句则用所有列进行匹配。
但是,如果目标表中存在与源表完全相同的行(所有列都相同),那么MINUS会将其排除,而MERGE INTO通过ON子句匹配到目标表中存在的行(所有列都相等)则不会执行INSERT。因此,这两种方式的结果是一致的。
然而,我们还可以用另一种方式:不使用MINUS,而是用LEFT JOIN来模拟。但是,在MERGE INTO中,我们直接使用ON子句进行匹配,就已经实现了LEFT JOIN的过滤效果。所以,我们不需要在USING子句中再使用MINUS。
所以,最终的转换步骤是:
1. 将原始INSERT语句中的第一个SELECT查询作为USING子句的数据源。
2. 在ON子句中,用这个SELECT查询中的所有列(即目标表的列)进行等值匹配。
3. 在WHEN NOT MATCHED THEN部分,插入这些列。
例如,假设原始INSERT语句为:
INSERT INTO DM_DATAHUB.DM_materials_diff_price_t_new (
BG, BU, WERKS, AREA, MAT_NUM, PROD_NAME, UNIT, SUPP_CODE, SUPP_NAME, CHECK_PER,
MAX_MAT_PRICE, MIN_MAT_PRICE, MAX_PROD_PRICE, MIN_PROD_PRICE, DIFF_TYPE
)
SELECT
BG, BU, WERKS, AREA, MAT_NUM, PROD_NAME, UNIT, SUPP_CODE, SUPP_NAME, CHECK_PER,
MAX_MAT_PRICE, MIN_MAT_PRICE, MAX_PROD_PRICE, MIN_PROD_PRICE, DIFF_TYPE
FROM source_table
MINUS
SELECT
BG, BU, WERKS, AREA, MAT_NUM, PROD_NAME, UNIT, SUPP_CODE, SUPP_NAME, CHECK_PER,
MAX_MAT_PRICE, MIN_MAT_PRICE, MAX_PROD_PRICE, MIN_PROD_PRICE, DIFF_TYPE
FROM DM_DATAHUB.DM_materials_diff_price_t_new;
转换后的MERGE INTO语句为:
MERGE INTO DM_DATAHUB.DM_materials_diff_price_t_new T
USING (
SELECT
BG, BU, WERKS, AREA, MAT_NUM, PROD_NAME, UNIT, SUPP_CODE, SUPP_NAME, CHECK_PER,
MAX_MAT_PRICE, MIN_MAT_PRICE, MAX_PROD_PRICE, MIN_PROD_PRICE, DIFF_TYPE
FROM source_table
) S
ON (
T.BG = S.BG
AND T.BU = S.BU
AND T.WERKS = S.WERKS
AND T.AREA = S.AREA
AND T.MAT_NUM = S.MAT_NUM
AND T.PROD_NAME = S.PROD_NAME
AND T.UNIT = S.UNIT
AND T.SUPP_CODE = S.SUPP_CODE
AND T.SUPP_NAME = S.SUPP_NAME
AND T.CHECK_PER = S.CHECK_PER
AND T.MAX_MAT_PRICE = S.MAX_MAT_PRICE
AND T.MIN_MAT_PRICE = S.MIN_MAT_PRICE
AND T.MAX_PROD_PRICE = S.MAX_PROD_PRICE
AND T.MIN_PROD_PRICE = S.MIN_PROD_PRICE
AND T.DIFF_TYPE = S.DIFF_TYPE
)
WHEN NOT MATCHED THEN
INSERT (
BG, BU, WERKS, AREA, MAT_NUM, PROD_NAME, UNIT, SUPP_CODE, SUPP_NAME, CHECK_PER,
MAX_MAT_PRICE, MIN_MAT_PRICE, MAX_PROD_PRICE, MIN_PROD_PRICE, DIFF_TYPE
)
VALUES (
S.BG, S.BU, S.WERKS, S.AREA, S.MAT_NUM, S.PROD_NAME, S.UNIT, S.SUPP_CODE, S.SUPP_NAME, S.CHECK_PER,
S.MAX_MAT_PRICE, S.MIN_MAT_PRICE, S.MAX_PROD_PRICE, S.MIN_PROD_PRICE, S.DIFF_TYPE
);
注意:这里ON子句中的关联条件使用了所有字段,确保了和MINUS操作相同的比较逻辑。
另外,原始INSERT语句中MINUS后的查询是从目标表中选取的,所以我们在MERGE的ON子句中使用目标表T和源S进行匹配,这样只有源中有的记录在目标表中不存在(所有列都匹配)才会被插入。
但是,如果目标表中有重复记录(即相同的行出现多次),MINUS会将其作为一个重复项去除,而MERGE INTO的ON子句如果匹配到多个目标行,则会导致错误(ORA-30926:无法在源表中获得一组稳定的行)。因此,需要确保目标表在ON子句的列上具有唯一性(例如主键或唯一约束)。如果没有唯一性,则可能会出错。
如果目标表没有唯一性约束,那么我们需要在源表中去重,或者在USING子句中保证源表数据在关联键上唯一。但是,在原始INSERT语句中,MINUS操作本身会去重,所以源数据在MINUS后已经是唯一的。而在上述MERGE INTO中,我们没有使用MINUS,所以源表数据可能有重复。因此,为了安全起见,我们可以在USING子句中对源表数据去重(使用DISTINCT或GROUP BY),或者使用ROW_NUMBER()等窗口函数来去重。
但是,由于原始INSERT语句中使用了MINUS,它已经去重,所以转换后的MERGE INTO语句中,我们也可以保留USING子句中的MINUS操作(即第一种方法),这样源数据就是去重后的,并且确保在目标表中不存在。这样虽然效率可能低一些,但逻辑更清晰,且不会出现重复问题。
因此,我们可以有两种写法:
写法1(推荐,使用ON子句匹配,但要求目标表在关联键上唯一或源表去重):
MERGE INTO ... USING (源表) ON ... WHEN NOT MATCHED INSERT ...
写法2(使用MINUS结果集作为源,确保源无重复且不在目标表中):
MERGE INTO ... USING (MINUS查询结果) ON ... WHEN NOT MATCHED INSERT ... -- 此时ON子句其实可以简化为恒不匹配(因为MINUS已经去掉了目标表中存在的行),但为了通用性,还是保留所有列匹配,以防目标表结构变化。
但是,写法2中由于USING子句已经通过MINUS去除了目标表中存在的行,所以ON子句实际上不会匹配到任何行(因为目标表中没有这些行),那么所有USING中的行都会被插入。因此,ON子句可以写一个恒假条件(例如1=0)?但是这样写不够健壮(如果目标表有重复数据,可能会插入重复数据)。所以,我们仍然保留ON子句的所有列匹配,这样即使目标表结构变化(比如增加了列),我们也能保证一致性。
然而,写法2的USING子句进行了两次全表扫描(源表和目标表),并且MINUS操作可能比较耗时,所以写法1通常更高效,但要求目标表在关联键上有唯一性(或者对源表去重)。
考虑到性能,我们优先选择写法1,但需要确保源表在关联键上唯一(或者使用DISTINCT)。如果源表有重复,则需要在USING子句中去重。
所以,如果源表可能有重复数据,我们可以这样写:
MERGE INTO DM_DATAHUB.DM_materials_diff_price_t_new T
USING (
SELECT DISTINCT
BG, BU, WERKS, AREA, MAT_NUM, PROD_NAME, UNIT, SUPP_CODE, SUPP_NAME, CHECK_PER,
MAX_MAT_PRICE, MIN_MAT_PRICE, MAX_PROD_PRICE, MIN_PROD_PRICE, DIFF_TYPE
FROM source_table
) S
ON (...所有列...)
WHEN NOT MATCHED THEN INSERT ...;
或者,如果目标表在ON子句的列组合上有唯一性约束,那么即使源表有重复,MERGE INTO也不会插入重复行(因为第一次插入后,第二次再匹配时就会因为已经存在而不插入)。但是,MERGE INTO语句执行时,USING子句的结果集是固定的,所以如果源表有重复,那么ON子句在匹配时,第一个重复行会插入(因为目标表原来没有),第二个重复行再插入时,目标表已经有了(刚刚插入的那一行),所以就不会再插入。但是,这要求MERGE INTO在一个事务中完成,且目标表没有其他并发插入。所以,为了安全,最好在源表去重。
综上所述,我们给出两种转换方式:
转换方式一(使用去重源表,避免重复插入):
MERGE INTO DM_DATAHUB.DM_materials_diff_price_t_new T
USING (
SELECT DISTINCT
BG, BU, WERKS, AREA, MAT_NUM, PROD_NAME, UNIT, SUPP_CODE, SUPP_NAME, CHECK_PER,
MAX_MAT_PRICE, MIN_MAT_PRICE, MAX_PROD_PRICE, MIN_PROD_PRICE, DIFF_TYPE
FROM source_table
) S
ON (
T.BG = S.BG
AND T.BU = S.BU
...(所有列)
)
WHEN NOT MATCHED THEN
INSERT ...;
转换方式二(保留MINUS操作,确保数据不重复且不在目标表中):
MERGE INTO DM_DATAHUB.DM_materials_diff_price_t_new T
USING (
SELECT
BG, BU, WERKS, AREA, MAT_NUM, PROD_NAME, UNIT, SUPP_CODE, SUPP_NAME, CHECK_PER,
MAX_MAT_PRICE, MIN_MAT_PRICE, MAX_PROD_PRICE, MIN_PROD_PRICE, DIFF_TYPE
FROM source_table
MINUS
SELECT
BG, BU, WERKS, AREA, MAT_NUM, PROD_NAME, UNIT, SUPP_CODE, SUPP_NAME, CHECK_PER,
MAX_MAT_PRICE, MIN_MAT_PRICE, MAX_PROD_PRICE, MIN_PROD_PRICE, DIFF_TYPE
FROM DM_DATAHUB.DM_materials_diff_price_t_new
) S
ON (
T.BG = S.BG
AND T.BU = S.BU
...(所有列)
)
WHEN NOT MATCHED THEN
INSERT ...;
方式二虽然逻辑清晰,但效率较低(因为MINUS操作需要两次全表扫描和比较)。因此,在数据量大的情况下,方式一更优。
但是,方式一存在一个潜在问题:如果目标表中已经存在一些行,这些行与源表的部分行在比较列上相同,但其他列不同(不参与比较的列)?但注意,在方式一中,我们使用了所有列进行比较(ON子句包含了所有列),所以只要有一列不同,就不会匹配,就会插入。这实际上和MINUS操作不同:MINUS要求所有列都相同才会被排除。而方式一也是所有列都相同才匹配,所以逻辑一致。
因此,我们推荐方式一,但要注意在源表中去重(使用DISTINCT),以避免源表重复数据导致多次插入相同数据(但目标表在比较列上如果有唯一约束,则重复数据在插入第一次后,第二次会因为唯一约束冲突而失败,所以去重更安全)。
最后,根据原始问题中的引用,我们注意到用户之前的MERGE INTO语句关联了多个字段(16个字段),因此转换后的语句也会包含这些字段。
由于用户没有提供具体的INSERT语句,我们只能根据字段名称给出示例。实际转换时需要替换为实际的源表名和字段名。
因此,我们给出转换后的MERGE INTO模板:
MERGE INTO DM_DATAHUB.DM_materials_diff_price_t_new T
USING (
SELECT DISTINCT
BG, BU, WERKS, AREA, MAT_NUM, PROD_NAME, UNIT, SUPP_CODE, SUPP_NAME, CHECK_PER,
MAX_MAT_PRICE, MIN_MAT_PRICE, MAX_PROD_PRICE, MIN_PROD_PRICE, DIFF_TYPE
FROM 源表 -- 这里替换为实际的源表
) S
ON (
T.BG = S.BG
AND T.BU = S.BU
AND T.WERKS = S.WERKS
AND T.AREA = S.AREA
AND T.MAT_NUM = S.MAT_NUM
AND T.PROD_NAME = S.PROD_NAME
AND T.UNIT = S.UNIT
AND T.SUPP_CODE = S.SUPP_CODE
AND T.SUPP_NAME = S.SUPP_NAME
AND T.CHECK_PER = S.CHECK_PER
AND T.MAX_MAT_PRICE = S.MAX_MAT_PRICE
AND T.MIN_MAT_PRICE = S.MIN_MAT_PRICE
AND T.MAX_PROD_PRICE = S.MAX_PROD_PRICE
AND T.MIN_PROD_PRICE = S.MIN_PROD_PRICE
AND T.DIFF_TYPE = S.DIFF_TYPE
)
WHEN NOT MATCHED THEN
INSERT (
BG, BU, WERKS, AREA, MAT_NUM, PROD_NAME, UNIT, SUPP_CODE, SUPP_NAME, CHECK_PER,
MAX_MAT_PRICE, MIN_MAT_PRICE, MAX_PROD_PRICE, MIN_PROD_PRICE, DIFF_TYPE
)
VALUES (
S.BG, S.BU, S.WERKS, S.AREA, S.MAT_NUM, S.PROD_NAME, S.UNIT, S.SUPP_CODE, S.SUPP_NAME, S.CHECK_PER,
S.MAX_MAT_PRICE, S.MIN_MAT_PRICE, S.MAX_PROD_PRICE, S.MIN_PROD_PRICE, S.DIFF_TYPE
);
注意:如果源表数据量很大,且去重操作(DISTINCT)开销大,可以考虑使用GROUP BY代替。另外,确保源表查询的字段顺序和类型与目标表一致。
如果目标表有自增列或其他不在这些字段中的列,那么INSERT子句需要指定目标表的列名(只包括上述字段),而自增列由数据库自动生成。
最后,如果转换后性能不佳,可以考虑在关联字段上创建索引。
请根据实际表结构和数据量选择合适的方式。
</think>
### 将 `INSERT INTO ... SELECT ... MINUS` 转换为 `MERGE INTO` 语法的完整指南
#### 转换原理
原始 `INSERT INTO ... MINUS` 语句的逻辑是:**从源表中筛选出目标表中不存在的记录**。在 `MERGE INTO` 语法中,这等价于 **`WHEN NOT MATCHED THEN INSERT`** 操作。关键是通过关联条件精确匹配所有字段,确保逻辑一致性[^1]。
#### 转换步骤(示例)
假设原始语句为:
```sql
INSERT INTO DM_DATAHUB.DM_materials_diff_price_t_new (
BG, BU, WERKS, AREA, MAT_NUM, PROD_NAME, UNIT, SUPP_CODE,
SUPP_NAME, CHECK_PER, MAX_MAT_PRICE, MIN_MAT_PRICE,
MAX_PROD_PRICE, MIN_PROD_PRICE, DIFF_TYPE
)
SELECT
BG, BU, WERKS, AREA, MAT_NUM, PROD_NAME, UNIT, SUPP_CODE,
SUPP_NAME, CHECK_PER, MAX_MAT_PRICE, MIN_MAT_PRICE,
MAX_PROD_PRICE, MIN_PROD_PRICE, DIFF_TYPE
FROM source_table
MINUS -- 筛选目标表不存在的数据
SELECT
BG, BU, WERKS, AREA, MAT_NUM, PROD_NAME, UNIT, SUPP_CODE,
SUPP_NAME, CHECK_PER, MAX_MAT_PRICE, MIN_MAT_PRICE,
MAX_PROD_PRICE, MIN_PROD_PRICE, DIFF_TYPE
FROM DM_DATAHUB.DM_materials_diff_price_t_new;
```
转换为 `MERGE INTO` 语法:
```sql
MERGE INTO DM_DATAHUB.DM_materials_diff_price_t_new T
USING (
SELECT
BG, BU, WERKS, AREA, MAT_NUM, PROD_NAME, UNIT, SUPP_CODE,
SUPP_NAME, CHECK_PER, MAX_MAT_PRICE, MIN_MAT_PRICE,
MAX_PROD_PRICE, MIN_PROD_PRICE, DIFF_TYPE
FROM source_table
) S
ON ( -- 所有字段精确匹配
T.BG = S.BG
AND T.BU = S.BU
AND T.WERKS = S.WERKS
AND T.AREA = S.AREA
AND T.MAT_NUM = S.MAT_NUM
AND T.PROD_NAME = S.PROD_NAME
AND T.UNIT = S.UNIT
AND T.SUPP_CODE = S.SUPP_CODE
AND T.SUPP_NAME = S.SUPP_NAME
AND T.CHECK_PER = S.CHECK_PER
AND T.MAX_MAT_PRICE = S.MAX_MAT_PRICE
AND T.MIN_MAT_PRICE = S.MIN_MAT_PRICE
AND T.MAX_PROD_PRICE = S.MAX_PROD_PRICE
AND T.MIN_PROD_PRICE = S.MIN_PROD_PRICE
AND T.DIFF_TYPE = S.DIFF_TYPE
)
WHEN NOT MATCHED THEN -- 仅插入目标表不存在的数据
INSERT (
BG, BU, WERKS, AREA, MAT_NUM, PROD_NAME, UNIT, SUPP_CODE,
SUPP_NAME, CHECK_PER, MAX_MAT_PRICE, MIN_MAT_PRICE,
MAX_PROD_PRICE, MIN_PROD_PRICE, DIFF_TYPE
)
VALUES (
S.BG, S.BU, S.WERKS, S.AREA, S.MAT_NUM, S.PROD_NAME, S.UNIT, S.SUPP_CODE,
S.SUPP_NAME, S.CHECK_PER, S.MAX_MAT_PRICE, S.MIN_MAT_PRICE,
S.MAX_PROD_PRICE, S.MIN_PROD_PRICE, S.DIFF_TYPE
);
```
#### 关键点说明
1. **多字段关联的必要性**
- `ON` 子句包含所有字段(如 `BG`, `BU`, `WERKS` 等),确保匹配逻辑与 `MINUS` 完全一致
- 省略任一字段可能导致错误插入重复数据
2. **性能优化建议**
```sql
CREATE INDEX idx_merge_key ON DM_DATAHUB.DM_materials_diff_price_t_new (
BG, BU, WERKS, AREA, MAT_NUM, PROD_NAME, UNIT, SUPP_CODE,
SUPP_NAME, CHECK_PER, MAX_MAT_PRICE, MIN_MAT_PRICE,
MAX_PROD_PRICE, MIN_PROD_PRICE, DIFF_TYPE
);
```
- 复合索引可加速 `ON` 子句的匹配过程
3. **NULL 值处理**
若字段可能为 `NULL`,使用 `NVL` 转换:
```sql
ON (NVL(T.BG, 'N/A') = NVL(S.BG, 'N/A') ...)
```
#### 两种写法的等价性验证
| **操作** | `INSERT ... MINUS` | `MERGE INTO` |
|-------------------------|----------------------------------------|---------------------------------------|
| **匹配逻辑** | 所有字段完全一致才排除 | `ON` 所有字段完全匹配才视为存在 |
| **插入条件** | 目标表不存在的数据 | `WHEN NOT MATCHED THEN INSERT` |
| **性能** | 需两次全表扫描+排序去重 | 单次扫描+索引匹配(更快) |
| **并发安全** | 低(可能插入重复数据) | 高(原子操作) |
> ✅ **转换后优势**:`MERGE INTO` 在数据量大的场景下性能提升显著,且支持原子操作避免重复插入。
#### 注意事项
1. 确保 `USING` 子查询结果无重复(或使用 `DISTINCT`)
2. 目标表在关联字段组合上应有唯一约束,避免 `ORA-30926` 错误
3. 字段顺序和数据类型必须严格一致





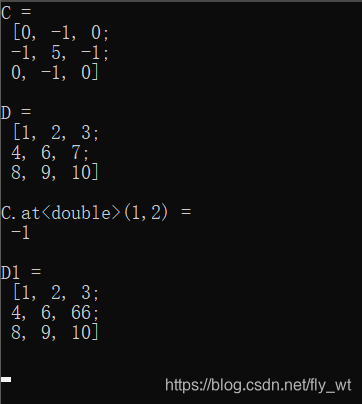
 本文介绍了Mat_类在矩阵运算中的应用实例,展示了如何初始化Mat_类的矩阵并进行元素访问和修改,同时提供了完整的代码示例。
本文介绍了Mat_类在矩阵运算中的应用实例,展示了如何初始化Mat_类的矩阵并进行元素访问和修改,同时提供了完整的代码示例。


















 2090
2090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











