






本文只介绍分布式事务常用解决方案,关于分布式事务基础知识请自行百度。
2PC – (刚性事务,牺牲了一部分可用性)
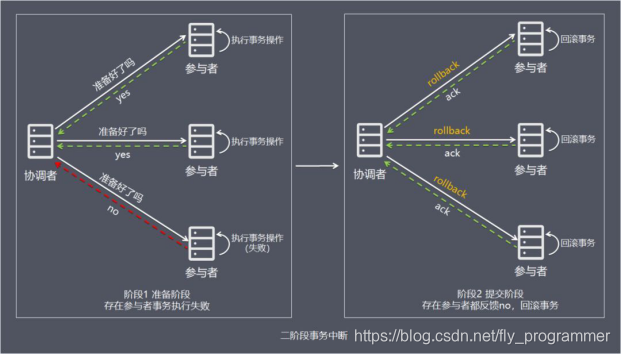
两阶段提交(Two-phase Commit,2PC),通过引入协调者(Coordinator)来协调参与者的行为,并最终决定这些参与者是否要真正执行事务。
如果事务在每个参与者上都执行成功,事务协调者发送通知让参与者提交事务;否则,协调者发送通知让参与者回滚事务。
需要注意的是,在准备阶段,参与者执行了事务,但是还未提交。只有在提交阶段接收到协调者发来的通知后,才进行提交或者回滚。
两阶段提交(Two-phase Commit,2PC),通过引入协调者(Coordinator)来协调参与者的行为,并最终决定这些参与者是否要真正执行事务。
如果事务在每个参与者上都执行成功,事务协调者发送通知让参与者提交事务;否则,协调者发送通知让参与者回滚事务。
需要注意的是,在准备阶段,参与者执行了事务,但是还未提交。只有在提交阶段接收到协调者发来的通知后,才进行提交或者回滚。
存在的问题:
同步阻塞 所有事务参与者在等待其它参与者响应的时候都处于同步阻塞状态,无法进行其它操作。
单点问题 协调者在 2PC 中起到非常大的作用,发生故障将会造成很大影响。特别是在阶段二发生故障,所有参与者会一直等待状态,无法完成其它操作。
数据不一致 在阶段二,如果协调者只发送了部分 Commit 消息,此时网络发生异常,那么只有部分参与者接收到 Commit 消息,也就是说只有部分参与者提交了事务,使得系统数据不一致。
太过保守 任意一个节点失败就会导致整个事务失败,没有完善的容错机制。
个人理解:
单点问题可引入超时机制解决?2pc只有协调者有超时机制,引入参与者超时机制?这样感觉就变成很像3PC的方案。是否可引入多协调者解决? 多协调者之间数据同步困难,实现复杂。由于其能保证数据强一致性的特点(牺牲效率),注定无法在高并发场景实现。当调用链条太长的时候,此方案无法适用。
3PC
三阶段提交协议(3PC)主要是为了解决两阶段提交协议的阻塞问题,2pc存在的问题是当协作者崩溃时,参与者不能做出最后的选择。因此参与者可能在协作者恢复之前保持阻塞。三阶段提交(Three-phase commit),是二阶段提交(2PC)的改进版本。
与两阶段提交不同的是,三阶段提交有两个改动点。
1、引入超时机制。同时在协调者和参与者中都引入超时机制。
2、在第一阶段和第二阶段中插入一个准备阶段。保证了在最后提交阶段之前各参与节点的状态是一致的。
也就是说,除了引入超时机制之外,3PC把2PC的准备阶段再次一分为二,这样三阶段提交就有CanCommit、PreCommit、DoCommit三个阶段。
之前2PC的一阶段是本地事务执行结束后,最后不Commit,等其它服务都执行结束并返回Yes,由协调者发生commit才真正执行commit。而这里的CanCommit指的是 尝试获取数据库锁 如果可以,就返回Yes。
总结
相比较2PC而言,3PC对于协调者(Coordinator)和参与者(Partcipant)都设置了超时时间,而2PC只有协调者才拥有超时机制。这解决了一个什么问题呢?
这个优化点,主要是避免了参与者在长时间无法与协调者节点通讯(协调者挂掉了)的情况下,无法释放资源的问题,因为参与者自身拥有超时机制会在超时后,
自动进行本地commit从而进行释放资源。而这种机制也侧面降低了整个事务的阻塞时间和范围。
另外,通过CanCommit、PreCommit、DoCommit三个阶段的设计,相较于2PC而言,多设置了一个缓冲阶段保证了在最后提交阶段之前各参与节点的状态是一致的。
以上就是3PC相对于2PC的一个提高(相对缓解了2PC中的前两个问题),但是3PC依然没有完全解决数据不一致的问题。
补偿事务(TCC)
TCC(Try-Confirm-Cancel)又称补偿事务。其核心思想是:“针对每个操作都要注册一个与其对应的确认和补偿(撤销操作)”。它分为三个操作:
Try阶段:主要是对业务系统做检测及资源预留。
Confirm阶段:确认执行业务操作。
Cancel阶段:取消执行业务操作。
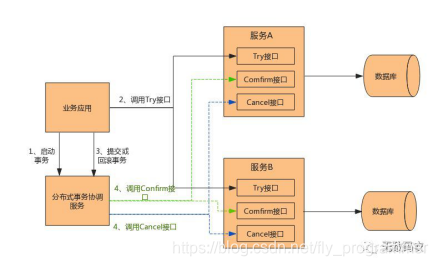
TCC事务的处理流程与2PC两阶段提交类似,不过2PC通常都是在跨库的DB层面,而TCC本质上就是一个应用层面的2PC,需要通过业务逻辑来实现。这种分布式事务的实现方式的优势在于,可以让应用自己定义数据库操作的粒度,使得降低锁冲突、提高吞吐量成为可能。
而不足之处则在于对应用的侵入性非常强,业务逻辑的每个分支都需要实现try、confirm、cancel三个操作。此外,其实现难度也比较大,需要按照网络状态、系统故障等不同的失败原因实现不同的回滚策略。为了满足一致性的要求,confirm和cancel接口还必须实现幂等。
本地消息表(最终一致性)
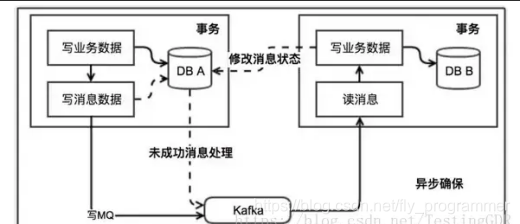
基本思路就是:
消息生产方,需要额外建一个消息表,并记录消息发送状态。消息表和业务数据要在一个事务里提交,也就是说他们要在一个数据库里面。然后消息会经过MQ发送到消息的消费方。如果消息发送失败,会进行重试发送。
消息消费方,需要处理这个消息,并完成自己的业务逻辑。此时如果本地事务处理成功,表明已经处理成功了,如果处理失败,那么就会重试执行。如果是业务上面的失败,可以给生产方发送一个业务补偿消息,通知生产方进行回滚等操作。
生产方和消费方定时扫描本地消息表,把还没处理完成的消息或者失败的消息再发送一遍。如果有靠谱的自动对账补账逻辑,这种方案还是非常实用的。
这种方案遵循BASE理论,采用的是最终一致性,笔者认为是这几种方案里面比较适合实际业务场景的,即不会出现像2PC那样复杂的实现(当调用链很长的时候,2PC的可用性是非常低的),也不会像TCC那样可能出现确认或者回滚不了的情况。
优点: 一种非常经典的实现,避免了分布式事务,实现了最终一致性。
缺点: 消息表会耦合到业务系统中,如果没有封装好的解决方案,会有很多杂活需要处理。
MQ事务消息
有一些第三方的MQ是支持事务消息的,比如RocketMQ,他们支持事务消息的方式也是类似于采用的二阶段提交,但是市面上一些主流的MQ都是不支持事务消息的,比如 RabbitMQ 和 Kafka 都不支持。
以阿里的 RocketMQ 中间件为例,其思路大致为:
第一阶段Prepared消息,会拿到消息的地址。 第二阶段执行本地事务,第三阶段通过第一阶段拿到的地址去访问消息,并修改状态。
也就是说在业务方法内要想消息队列提交两次请求,一次发送消息和一次确认消息。如果确认消息发送失败了RocketMQ会定期扫描消息集群中的事务消息,这时候发现了Prepared消息,它会向消息发送者确认,所以生产方需要实现一个check接口,RocketMQ会根据发送端设置的策略来决定是回滚还是继续发送确认消息。这样就保证了消息发送与本地事务同时成功或同时失败。
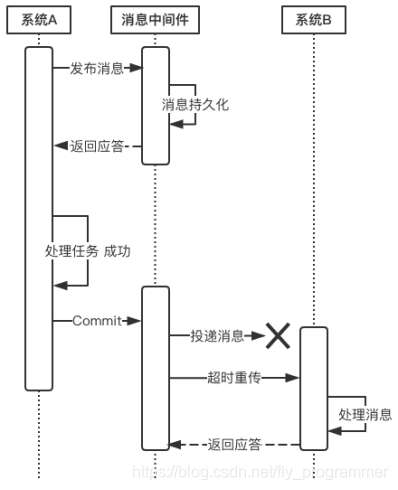
下面来说一说消息投递过程的可靠性保证。
当上游系统执行完任务并向消息中间件提交了Commit指令后,便可以处理其他任务了,此时它可以认为事务已经完成,接下来消息中间件一定会保证消息被下游系统成功消费掉!那么这是怎么做到的呢?这由消息中间件的投递流程来保证。
消息中间件向下游系统投递完消息后便进入阻塞等待状态,下游系统便立即进行任务的处理,任务处理完成后便向消息中间件返回应答。消息中间件收到确认应答后便认为该事务处理完毕!
如果消息在投递过程中丢失,或消息的确认应答在返回途中丢失,那么消息中间件在等待确认应答超时之后就会重新投递,直到下游消费者返回消费成功响应为止。当然,一般消息中间件可以设置消息重试的次数和时间间隔,比如:当第一次投递失败后,每隔五分钟重试一次,一共重试3次。如果重试3次之后仍然投递失败,那么这条消息就需要人工干预。
优点: 实现了最终一致性,不需要依赖本地数据库事务。
缺点: 实现难度大,主流MQ不支持,RocketMQ事务消息部分代码也未开源。
由于本人能力有限,此文章参考了多篇技术博客,版权归原作者所有如有侵权请立即与我联系,我将及时处理。

















 2426
2426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









