




 本文详细探讨了MySQL索引的本质、B-Tree和B+Tree知识,重点分析了MyISAM和InnoDB引擎的索引实现。同时,介绍了如何通过慢查询日志进行性能分析,并利用EXPLAIN理解SQL执行计划。最后,文章分享了索引分类、创建与删除方法,以及Filesort、GROUP BY、LIMIT和COUNT等常见查询的优化策略。
本文详细探讨了MySQL索引的本质、B-Tree和B+Tree知识,重点分析了MyISAM和InnoDB引擎的索引实现。同时,介绍了如何通过慢查询日志进行性能分析,并利用EXPLAIN理解SQL执行计划。最后,文章分享了索引分类、创建与删除方法,以及Filesort、GROUP BY、LIMIT和COUNT等常见查询的优化策略。
一 索引本质
- 索引是什么?
索引:有序的数据结构。
- 索引目的?
帮助MySQL高效获取数据。
- 索引文件目录
MyISAM引擎
-rw-r-----. 1 polkitd input 61 9⽉ 2 11:31 db.opt
-rw-r-----. 1 polkitd input 8668 9⽉ 2 11:36 tb_user2.frm #表结构⽂件
-rw-r-----. 1 polkitd input 0 9⽉ 2 11:36 tb_user2.MYD #MyISAM引擎类型的表数据⽂件
-rw-r-----. 1 polkitd input 1024 9⽉ 2 11:36 tb_user2.MYI #MyISAM引擎类型的索引⽂件
InnoDB
-rw-r-----. 1 polkitd input 8668 9⽉ 2 11:33 tb_user.frm #表结构⽂件
-rw-r-----. 1 polkitd input 114688 9⽉ 2 11:34 tb_user.ibd #InnoDB的表空间⽂件,⽤于存储数据以及索引⽂件
二 MySQL索引前置知识
2.1 B-Tree知识
- 概念
度数:在树中,每个节点的⼦节点(⼦树)的个数就称为该节点的度(degree)。
阶数:定义为⼀个节点的⼦节点数⽬的最⼤值。
- m阶B-Tree满⾜以下条件
每个节点最多拥有m个⼦树
根节点⾄少有2个⼦树
分⽀节点⾄少拥有m/2颗⼦树(除根节点和叶⼦节点外都是分⽀节点)
所有叶⼦节点都在同⼀层、每个节点最多可以有m-1个key,并且以升序排列
每个⾮叶⼦节点由n-1个key和n个指针组成,key和指针互相间隔,节点两端是指针
- 3阶B-Tree的示意图(节点包含键值和数据)

- 选用B-Tree做索引结构(MongoDB)
⼀次读取⼀个磁盘块数据中包含了多个key数据,这样就可以在内存中做⽐较操作,减少了磁盘IO的操作。
2.2 B+Tree知识
- B+Tree示意图

- B+Tree相对于B-Tree有几点不同
⾮叶⼦节点只存储键值信息。
数据记录都存放在叶⼦节点中。
所有叶⼦节点之间都有⼀个s双向链指针。
- InnoDB为什么使用B+树做索引树
B+树的磁盘读写代价更低
内部节点只存储索引不存储数据。所以同一块磁盘中读取的索引数量就越多,减少IO的读写次数。
B+树的查询效率更加稳定
所以任何关键字的查找必须⾛⼀条从根节点到叶⼦节点的路。
三 索引结构与分析
3.1 MyISAM索引实现(B+Tree)
主键索引实例
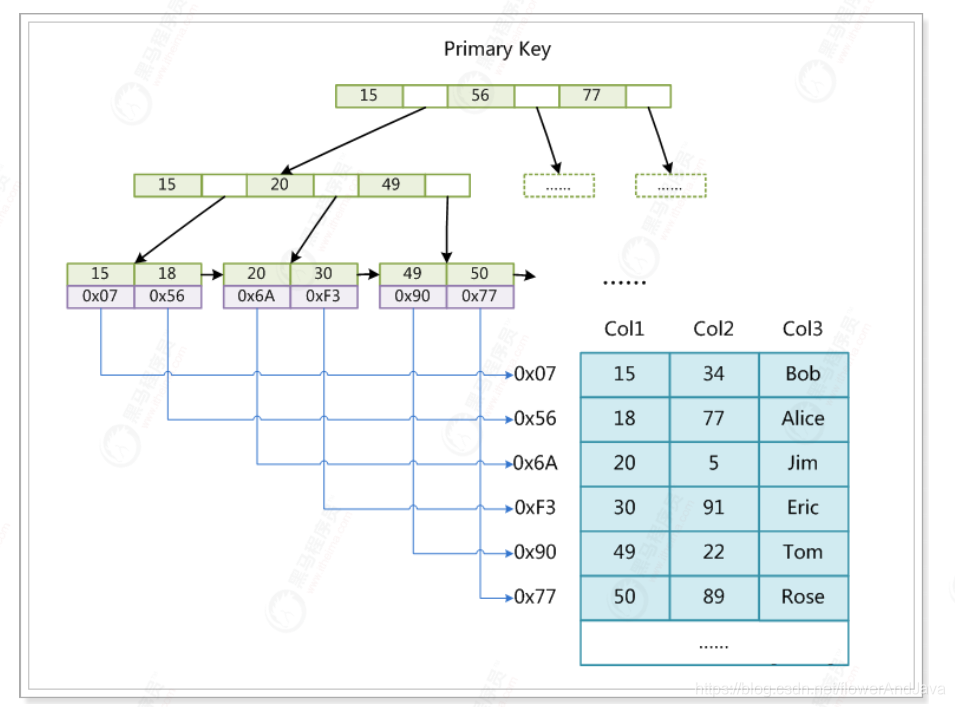
索引的解释
MyISAM的索引⽂件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引(Secondarykey)在结构上没有任何区别,
只是主索引要求key是唯⼀的,⽽辅助索引的key可以重复。
辅助索引实例
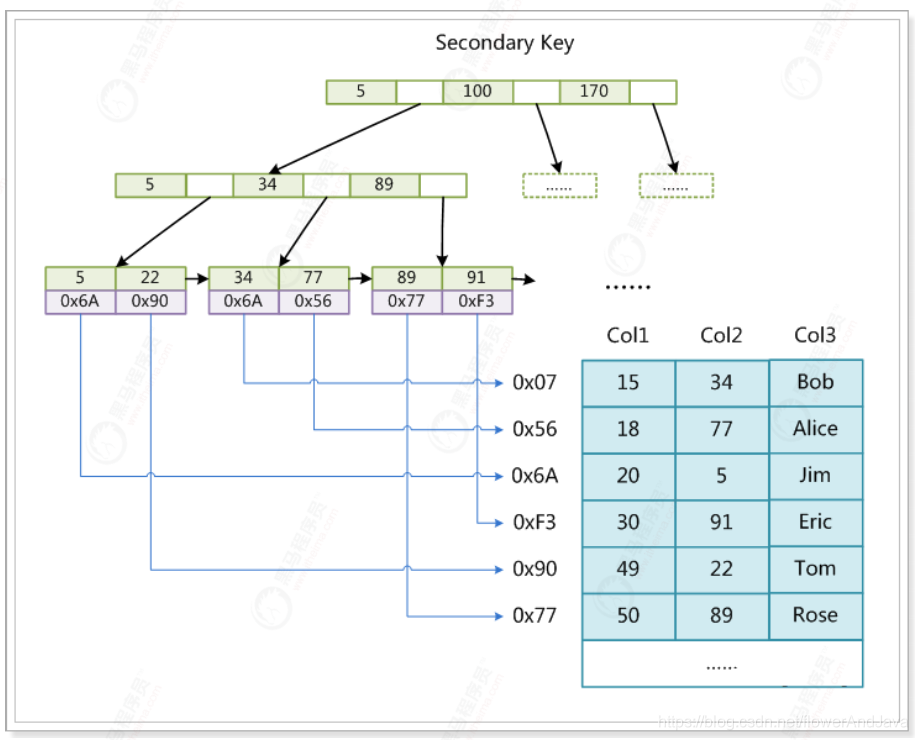
MyISAM的索引搜索步骤
MyISAM中索引检索的算法为⾸先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,
然后以data域的值为地址,读取相应数据记录。
备注
MyISAM的索引⽅式也叫做“⾮聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
3.2 InnoDB索引实现
- 主键索引(聚集索引)
引入
InnoDB的数据⽂件本身就是索引⽂件。
主键索引示意图
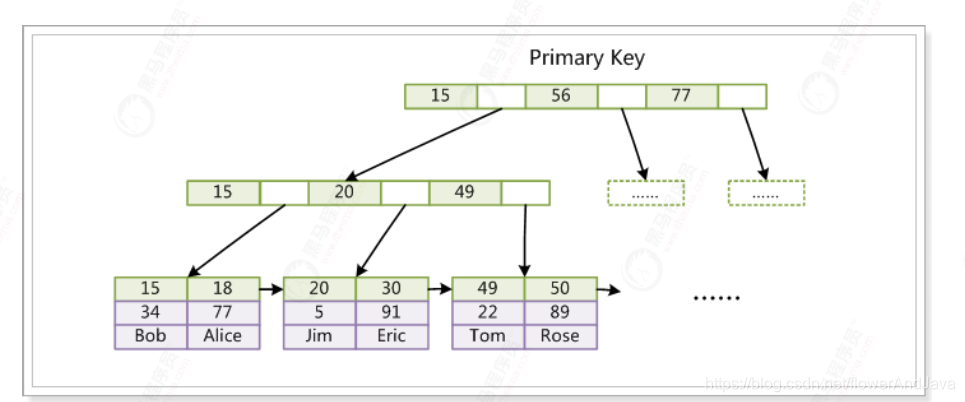
叶子节点包含完整的数据记录。这种索引也叫做聚集索引。
数据是否可以没有主键?
MyISAM可以没有主键,但是InnoDB数据文件按照主键聚集,所以InnoDB必须含有主键。但是如果没有显示指定,
MySQL会自动制定一个唯一标识和不为空的字段做为主键。如果不存在这种类型,MySQL会自动生成一个隐式主键,
字段长度为6个字节,类型为长整型。不能在业务中使用。
- 非主键索引
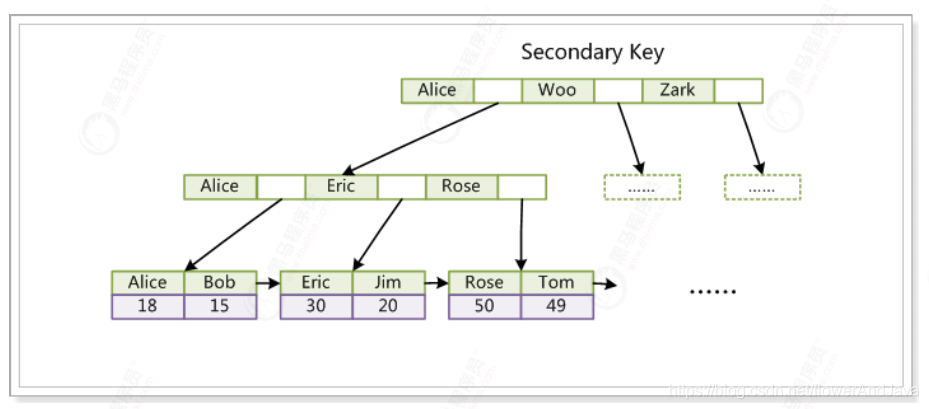
这⾥以英⽂字符的ASCII码作为⽐较准则。辅助索引搜索需要检索两遍索引:⾸先检索辅助索引获得主键,然后⽤主键到主索引中检索获得记录。
- 联合索引
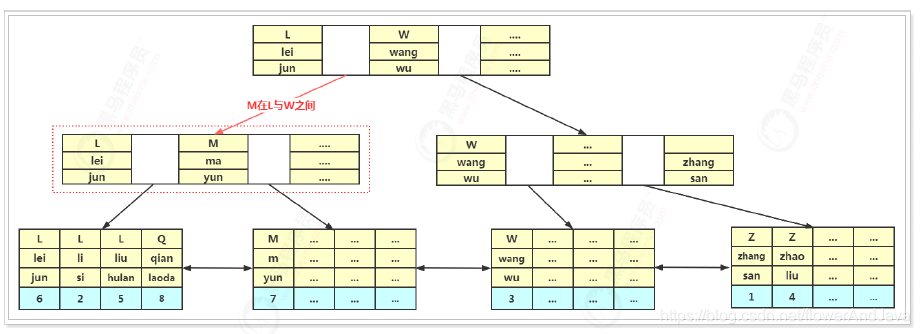
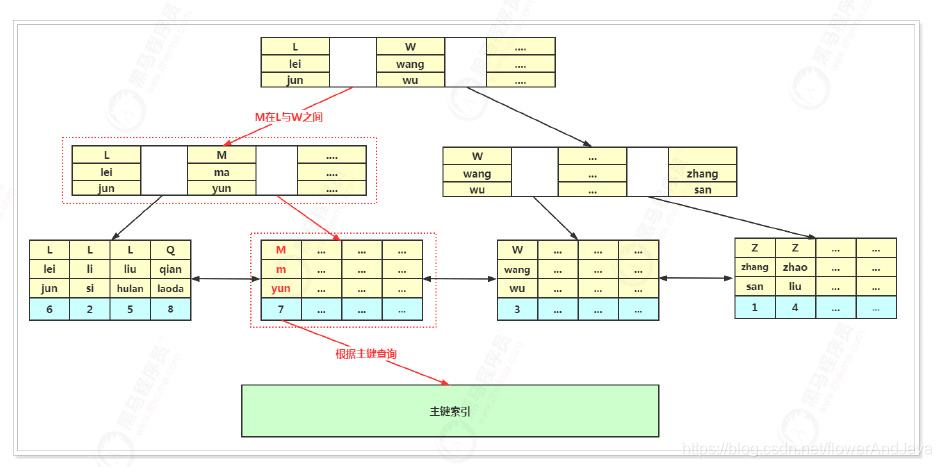
联合索引执行流程
执行sql
SELECT * FROM tb_contact WHERE index_code = 'M' AND surname = 'ma' AND name ='yun'
首先从根节点查找(根节点常驻内存中),第⼀个列为index_code,其值为:M,在L与W之间,会继续
向⼦节点查询。找到子节点后,将⼦节点数据从磁盘加载到内存中,采⽤⼆分法进⾏查找,找到M ma yun
数据符合条件,再继续查找⼦节点,读取到⼦节点中的data数据,其数据就是这条记录的主键,然后再通
过主键索引查询数据,最终将在主键索引中查询到数据。
联合索引使用注意(最左前缀原则)
使用联合索引必须按照索引顺序使用,不然导致索引失效。如下sql:(索引结构如上图)
SELECT * FROM tb_contact WHERE index_code = 'M' AND surname = 'ma' AND name ='yun' --索引会⽣效
SELECT * FROM tb_contact WHERE index_code = 'M' AND surname = 'ma' --索引⽣效
SELECT * FROM tb_contact WHERE index_code = 'M' --索引会⽣效
SELECT * FROM tb_contact WHERE surname = 'ma' AND name = 'yun' --索引不会⽣效
- 覆盖索引和回表查询
什么是回表查询?
先根据非主键索引查询到主键值。再扫描主键索引获取行数据。
什么是覆盖索引
只在一颗索引树上就能获取sql查询出所需的所有列数据。
四 慢查询日志
show profiles 能够在做SQL优化时帮助我们了解时间都耗费到哪里去。
4.1 profile开启
- 查看MySQL是否支持profile
select @@have_profiling;

2. 查看profiling是否开启
select @@profiling;

3. 开启profiling
执行命令 set profiling=1;
4.2 show profile
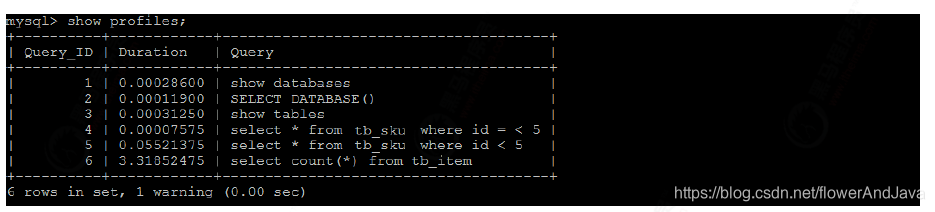
- 准备sql
show databases;
use db01;
show tables;
select * from tb_ksu where id < 5;
select count(*) from tb_ksu;
- 执行show profiles(查看sql耗时)
- 执行show profile for query query_id
查看该sql执行过程中,每个线程状态和执行时间
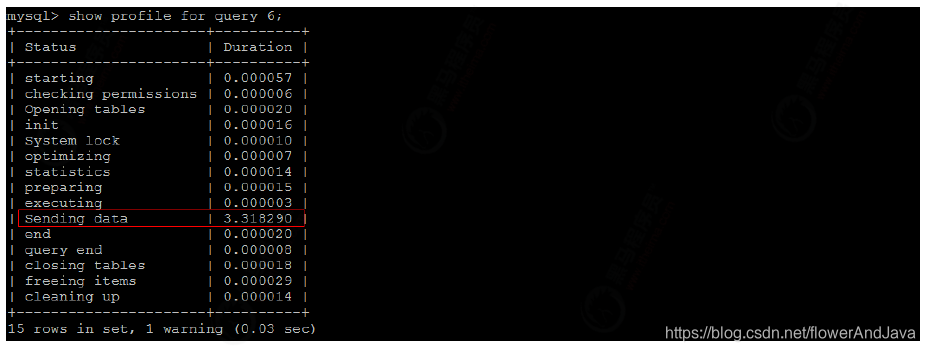
备注
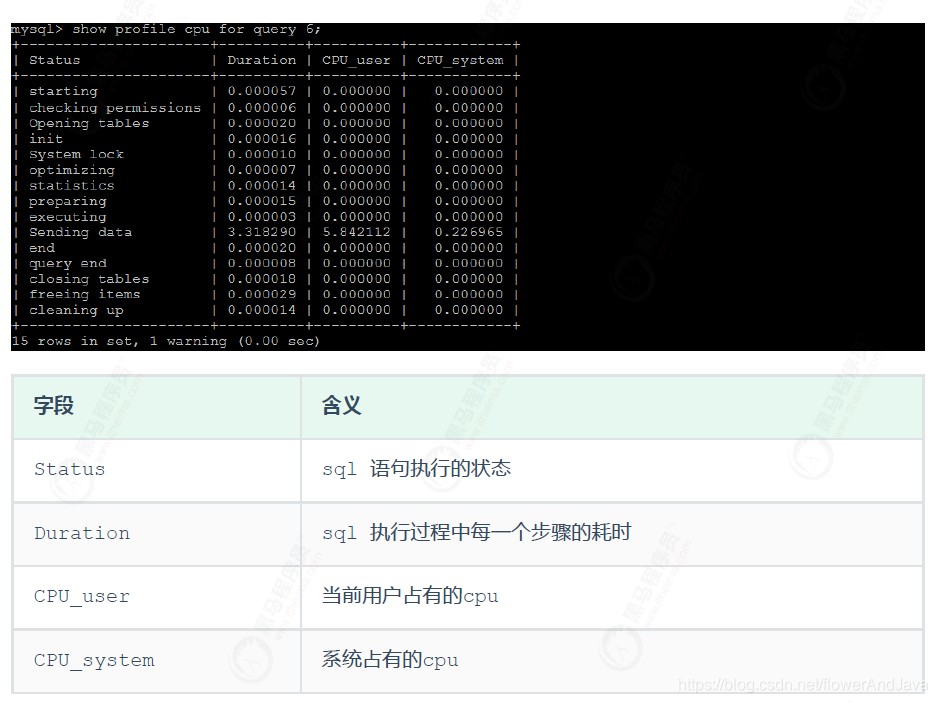
Sending data 状态表示MySQL线程开始访问数据行并把结果返回给客户端。由于在Sending data状态下,
MySQL线程往往需要做大量的磁盘读取操作,所以经常是整各查询中耗时最长的状态。
- 查看在什么资源上消耗过高时间
MySQL支持进一步选择all、cpu、block io 、context、switch、page faults等明细类型类查看MySQL在使用什么资源上耗费了过高的时
show profiles cpu for query 6;
4.3 慢查询日志分析
- 查询long_query_time 的值
show variables like 'long%'

sql执行时间超过十秒就会被记录在慢查询日志中。
2. 查看慢查询日志
cat slow_query.log
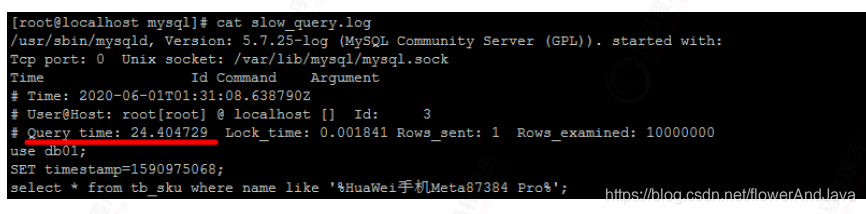
3. 慢查询日志分析
如果慢查询日志内容很多, 直接查看文件,比较麻烦, 这个时候可以借助于mysql自带的mysqldumpslow 工具, 来对慢查询日志进行分类汇总。

五 EXPLAIN执行结果认识
5.1 查看sql执行计划
explain select * from tb_sku where name like '%HuaWei 手机Meta87384 Pro%';

5.2 执行计划字段解释
- id
select查询的序列号,代表sql执行顺序。iid相同的可以认为一组,从上往下执行。在所有组中,id值越大,越先执行。
- select_type(select 类型)

- type(访问类型)
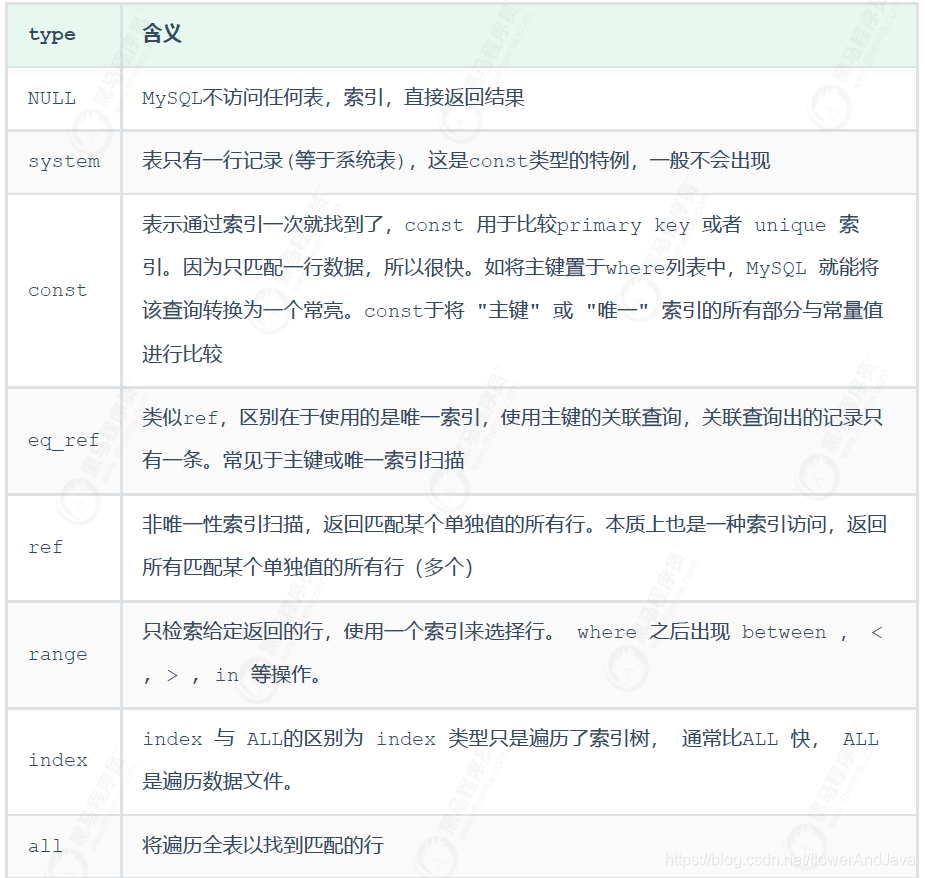
备注
一般来说, 我们需要保证查询至少达到 range 级别, 最好达到ref 。
- key
possible_keys : 显示可能应用在这张表的索引。
key : 实际使用的索引, 如果为NULL, 则没有使用索引。
key_len : 表示索引中使用的字节数, 该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前提下, 长度越短越好。
- rows
扫描行的数量
- extra
执行情况的说明和描述。
六 索引
6.1 索引分类
主键索引、唯一索引、普通索引、组合索引、全文索引
6.2 创建和删除索引
create index 索引名字 on表名(字段名) # 新增普通索引
drop index 索引名字 on 表名 # 删除索引
create unique index 索引名字 on 表名(字段名) # 添加唯一索引
create index idx_emp_age_salary on emp(age,salary); # 添加组合索引
七 常见优化
7.1 Filesort优化
- FileSort排序
不是通过返回数据进行排序叫做FileSort排序。
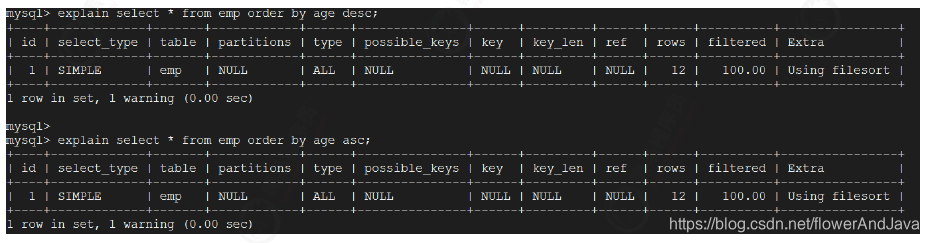
- using index(通过有序索引顺序扫描直接返回结果)
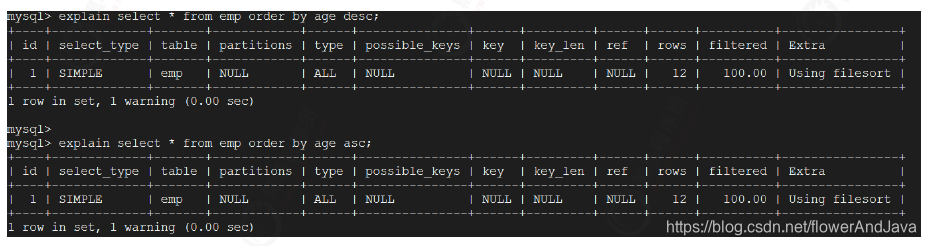
- 多字段排序
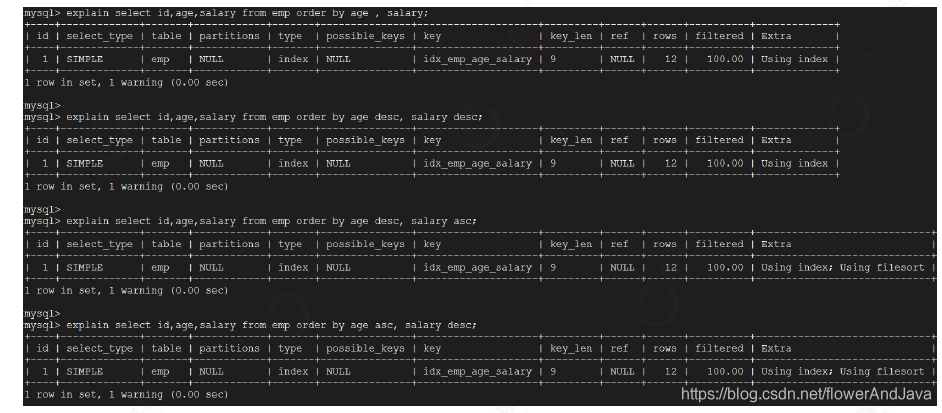
Order by 的字段都是升序,或者都是降序。否则肯定需要额外的操作,这样就会出FileSort。优化目标清晰了,通过索引直接返回有序数据,减少额外的排序。
- Filesort的优化
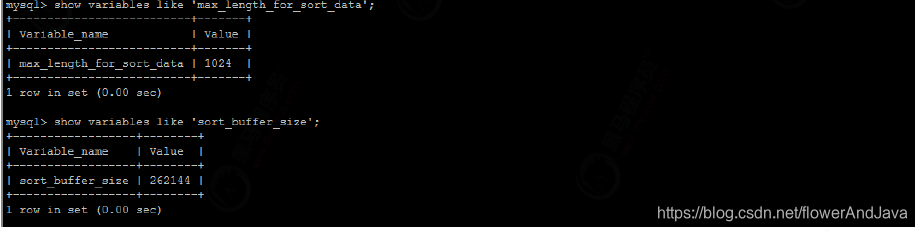
某些条件限制不能让Filesort消失。MySQL 通过比较系统变max_length_for_sort_data 的大小和Query语句取出的字段总大小。
如果max_length_for_sort_data更大采用一次扫描算法,否则采用二次扫描算法。
一次扫描算法,一次性取出所有满足条件字段在排序区中排序后直接输出结果。一次排序内存消耗大,但排序效率比二次排序效率高。
因此sort_buffer_size 和 max_length_for_sort_data 系统变量,来增大排序区的大小,提高排序的效率
7.2 group by优化
- 前置
group by 实际也会进行排序操作。但是与order by相比多了排序后的分组操作和分组后的一些聚集函数使用。
使用group by避免排序结果的消耗,可以使用禁止排序,sql加上order by null
优化前
explain select age,count(*) from emp group by age;

优化后
explain select age,count(*) from emp group by age order by null;

7.3 limit优化
一般分页查询时候,通过覆盖索引能更好的提升性能。limit分页越往后性能越差。因为要查询5000000 - 5000010 的记录,
需要先查询出前前5000010,丢弃掉前5千条。
7.4 count优化
- 概述
我们进行分页和获取总记录数,需要遍历全表数据,对计数进行累加。如果数据量比较大,cout性能比较低。
- 优化方案
a 在redis定义一个计数器,增加和删除对计数动态更新。
b 在数据库定义一个计数器,删除和插入进行动态更新。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









