




 本文介绍一种结合外部知识提升视觉问答(VQA)准确性的方法,通过引入知识图谱,实现从封闭到开放领域的VQA转变。模型利用FastRCNN识别图片中的实体,并通过关键词抽取与知识图谱检索,获取并编码外部知识。采用注意力机制融合外部知识,更新记忆模块,最终融合多模态特征进行推断。
本文介绍一种结合外部知识提升视觉问答(VQA)准确性的方法,通过引入知识图谱,实现从封闭到开放领域的VQA转变。模型利用FastRCNN识别图片中的实体,并通过关键词抽取与知识图谱检索,获取并编码外部知识。采用注意力机制融合外部知识,更新记忆模块,最终融合多模态特征进行推断。
目录
论文简介

改论文主要引入了外部知识使得封闭领域的视觉问答(VQA-visual question answering)任务变为开放领域的视觉问答,
任务形式化:
输入:一张图片+围绕图片的问题+根据问题在知识图谱中检索的外部知识(论文中使用三元组)
输出:问题的答案(一般有4个候选类别)
外部知识的获取
这一步显然是很关键的,如果获取有用的外知识是模型有效的先决条件。
由于输入是图片和问题文本,对于图片作者使用FatsRCNN(用于目标检测的模型,首先FastRCNN应该是预训练好的,作者使用这个模型可以获得图片的目标(object)的类别实体,和box的大小(这个后面有用)。然后根据关键抽取工具对Question text进行关键词抽取,由于我们FastRCNN识别的类别实体和抽取出来的关键词实体都不一定在知识库(concept)中出现,所以作者使用这些实体所有可能的n-grams拆分在concept中进行检索。很显然concept知识图谱是非常大的,所以作者只使用了一阶的graph每个node(只有一个实体描述),相应的还有二阶知识图谱,每个node可能由2个实体描述
(详细的请参考https://blog.youkuaiyun.com/blueorris/article/details/96359338)这个由很多个三元组构成的图定义为G。但是问题是这个G依然很大,必须想办法压缩。
为了挑选出top-N的三元组,作者为每条边设计了一个打分(权重)函数w(i,j),每个节点(Node)的权者w(i),w(j),对于每个视觉类别实体初始化和box大小成正比,每个关键词实体初始化一样(具体初始化并没有讲)。
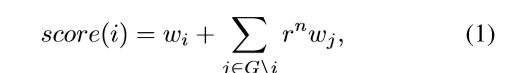
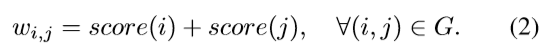
其中n代表node(i)和node(j)之间的edge个数,r是衰减因子0-1之间。作者很多的细节没有将比如这里w的初始化。
作者根据topN的w(i,j)对G进行压缩。这个新的G*就是最终作为模型使用的外部知识。
外部知识的编码
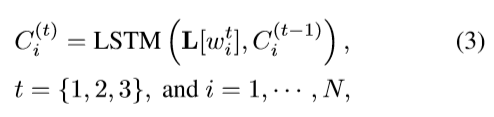
由于之前得到的是三元组,使用glove进行训练得到词向量,实体和中间的关系看作一样对待。
随后使用LSTM将每个三元组进行语义压缩,如上公式,每个三元组就用一个新的语义向量表示。
然后把这些语义向量存放到一个memory slot中

M[i]表示第i个三元组语义向量,C上面的角标3表示使用最后一个hidden state作为语义向量。
基于注意力机制的知识融合
query vector
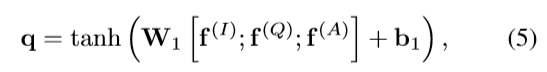
上面公式的f(I),f(Q),f(A)分别表示使用DNN模型(论文没有细说)对image,question,answers抽取得到的特征向量。这query向量捕捉到了question-answer的上下文信息。 episodic memory m(T)的m(0)=q
注意力机制
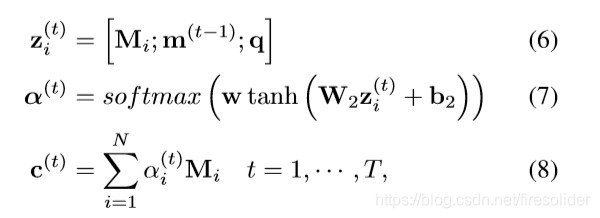
作者使用注意力机制得到有用的外部知识来更新 episodic memory m(T)
episodic memory更新
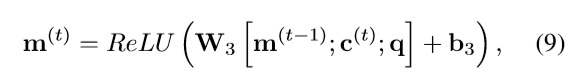
模型融合和推断
融合多模态特征
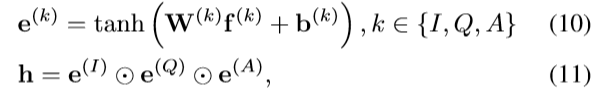
推断
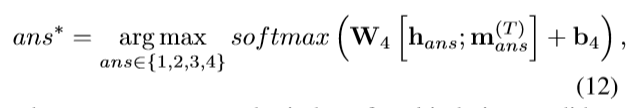
hans表示答案ans的多模态融合向量,每个答案都可以根据公式(10)(11)得到一个多模态融合特征向量,m_ans^(T)也是如此,T表示episodic memory m更新的次数。所以这个任务还是使用文本分类的范式,将问题机械的分类为4个给定的类别,其实还使用基于检索匹配的方法生成更加丰富的答案,而不是使用给定的答案进行选择。虽然模型设计花里胡哨,但是问题设计还是比较呆板的。
参考文献:Incorporating External Knowledge to Answer Open-Domain Visual Questions with Dynamic Memory Networks.
arXiv:1712.00733v1 [cs.CV] 3 Dec 2017

















 790
790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









