




在智能文档查重领域,人们往往聚焦于算法的精准度——认为只要能算出重复率、识别相似文本,就是一款好产品。但实际应用中,无数用户曾遭遇这样的困境:算法给出了90%的重复率,但密密麻麻的文本碎片和混乱的标注让使用者对着结果一脸茫然,既找不到重复内容在原文的位置,也无法快速定位风险点。这恰恰印证了一个被忽视的真相:智能文档查重的真正难点,从来不是算法本身,而是如何将复杂的查重结果转化为用户能看懂、会使用、能高效决策的可视化交互体验。
算法是基础,但“看得懂”才是用户的核心诉求
查重的本质是为用户提供“决策依据”——无论是招投标中的围串标排查、学术论文的原创性审核,还是企业机密文档的重复使用检测,用户最终需要的不是一串冰冷的重复率数字,而是“哪里重复了”“重复的内容在原文什么位置”“不同文档的重复点有何关联”的直观答案。
算法可以通过文本比对、特征提取算出重复度,但如果展示方式不合理,结果就会沦为“数据迷宫”:某高校老师曾使用某查重工具检测论文,系统仅返回“摘要部分重复率35%”,却未标注具体重复段落在原文的位置,老师不得不逐字比对原文与检测报告,耗时2小时才找到问题;某招标代理机构在比对10份标书时,工具将重复内容拆分成零散文本块,缺乏逻辑关联,评审员花了一下午才理清3家供应商的雷同脉络。
这些场景暴露了一个核心矛盾:算法的精准度需要通过可视化交互“落地”。如果用户需要耗费大量时间解读结果,再优秀的算法也无法转化为实际效率——这正是智能文档查重的真正挑战:让机器的“计算结果”成为人的“可感知信息”。
好的可视化交互,要解决“三个精准”
智能文档查重的可视化交互设计,本质是在“机器识别结果”与“人类决策需求”之间搭建桥梁。真正贴合用户需求的交互,必须实现“定位精准、关联清晰、场景适配”三大核心目标。
精准定位:让重复内容“秒回原文”
用户最基础的诉求是“看到重复内容在原文的哪里”。传统工具常将重复文本从原文档中剥离,单独罗列成清单,导致用户需要在“报告”与“原文”之间反复切换,效率极低。
而优秀的可视化交互应做到“原文锚定”:例如保留原文档的完整排版结构,用高亮色块标注重复文本块,同时通过虚线连线直观展示不同文档中重复内容的对应关系——就像在标书查重时,用户点击“施工方案”章节的重复标注,右侧立即弹出关联标书的对应段落,且两者的字体、行距、图表位置与原文完全一致。这种“所见即原文”的设计,让用户无需记忆文本位置,3秒内即可定位问题。

关联清晰:让复杂关系“一目了然”
当面对多份文档批量查重(如10v10标书比对)时,重复关系往往呈现网状结构:A与B的技术参数重复,B与C的资质文件雷同,C又与A的施工流程高度相似。此时,单纯的文本标注已无法满足需求。
可视化交互需要承担“关系翻译”的角色:通过动态图谱展示文档间的重复度关联(如多文档重复率统计、重复文本原文标记),同时生成“重复率排行榜”,按重复率高低展示结果。例如在某审计项目中,工具通过统计图表一眼标出3份报告中“采购清单”部分的交叉重复,让评审员快速锁定串标嫌疑最大的供应商组合,而这一过程仅需5分钟,远低于人工梳理的2小时。
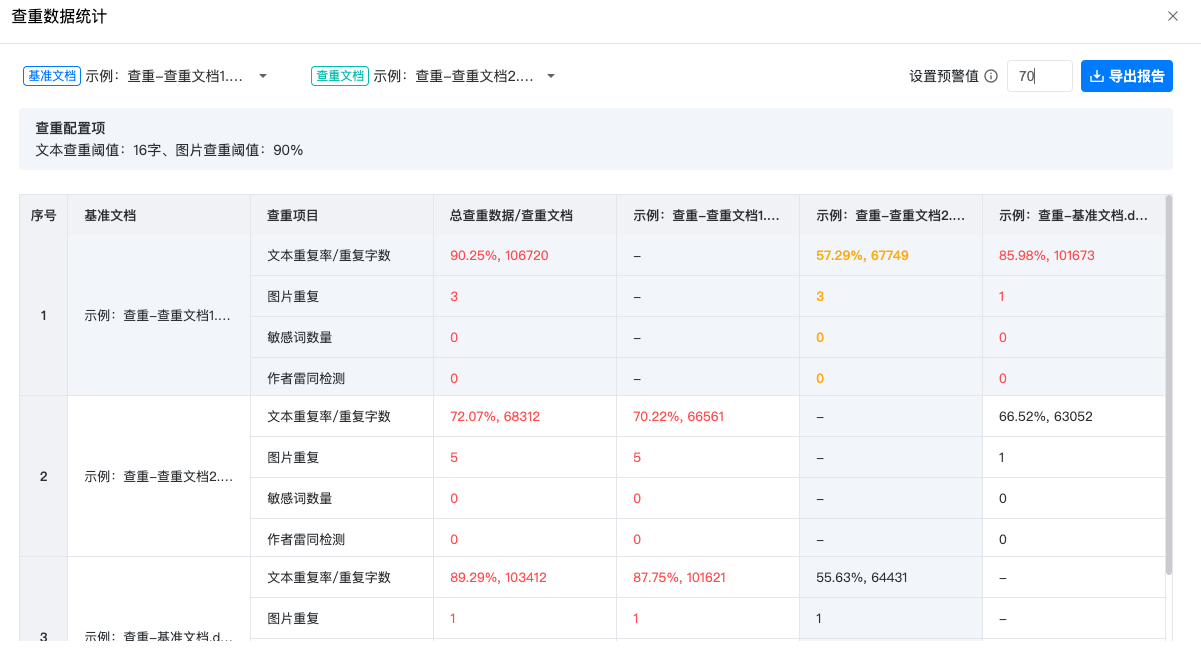
场景适配:让交互逻辑“贴合业务”
不同领域的查重需求,对交互的要求截然不同:招投标领域需要快速定位“敏感词重复”(如“独家技术”“专利号”),学术领域关注“段落改写的细微重复”,企业文档查重则重视“跨部门文件的复用痕迹”。
脱离场景的可视化交互,再精美也难以落地。例如针对招投标场景,工具需设计“招标文件模板过滤”功能——自动剔除通用模板内容(如法定条款),仅高亮展示实质性响应部分的重复;同时开发“敏感词雷达”交互模块,用户自定义风险词后,系统在原文中用特殊符号标注,并生成风险词出现频次热力图,让围串标线索无处隐藏。这种“业务嵌入型”交互,让算法结果直接服务于具体工作流程。
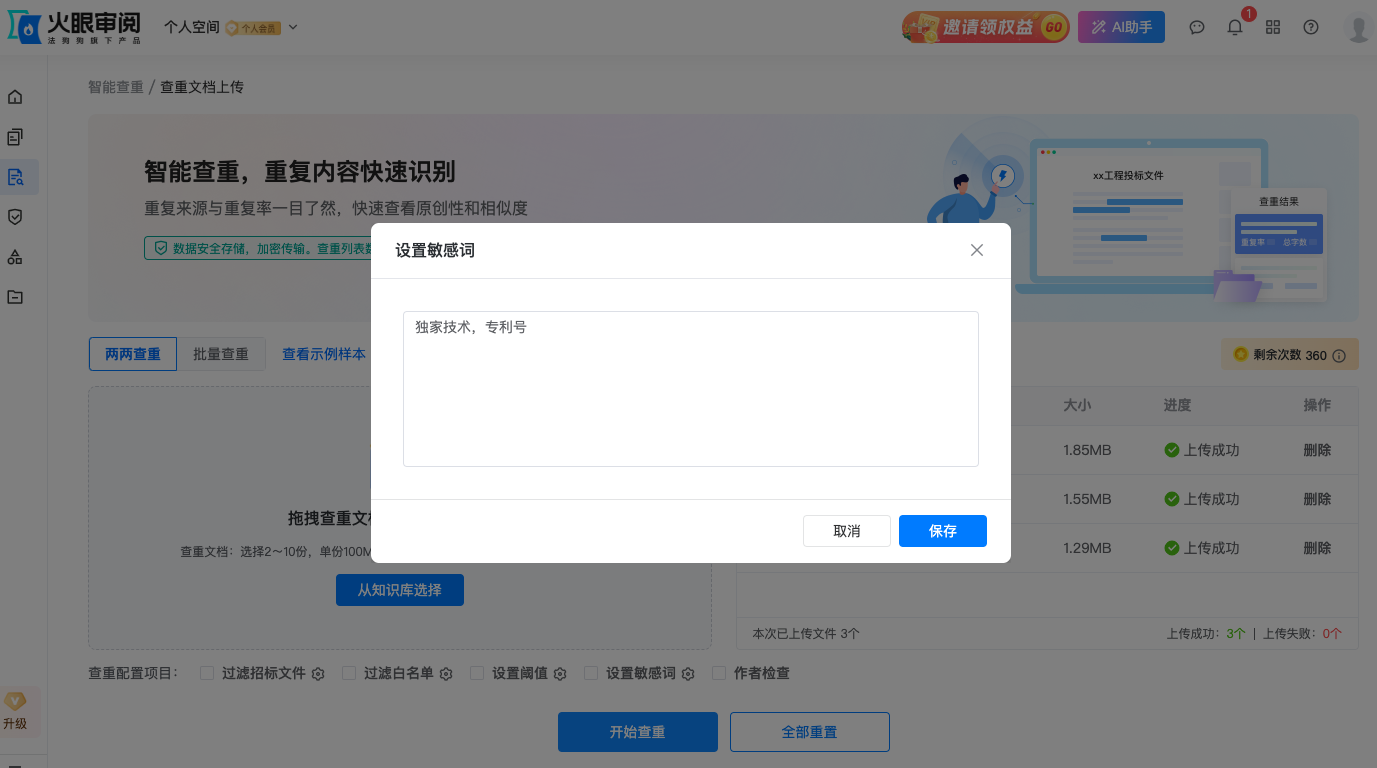
可视化交互的终极目标:让“技术语言”转化为“业务语言”
市场上不少查重产品陷入“技术炫技”的误区:过度强调算法模型的先进性,却忽视了用户的实际使用场景。某友商产品能实现99%的重复识别率,但结果展示仅支持“文本片段+重复率数字”,导致用户在评审千页标书时,不得不手动标注、交叉比对,最终将技术优势抵消在低效的交互中。
反观真正受用户认可的查重工具,其核心竞争力恰恰在于“翻译能力”——将算法识别的重复特征,转化为贴合业务场景的可视化语言:
- 对招标人员,是“重点聚焦高重复率投标文件”,包含重复文本数量、原文位置坐标、相似度量化数据,直接作为评审依据;
- 对高校老师,是“保留排版的论文比对页”,红色高亮显示疑似抄袭段落,同步展示相似文本来源文件;
- 对投标人员,是“高效修改标书、提升中标率”,支持定位文件重复内容位置、便捷修改。
这些交互设计的背后,是对用户“决策链路”的深度理解:用户需要的不是“机器发现了什么”,而是“我该如何基于发现的问题行动”。
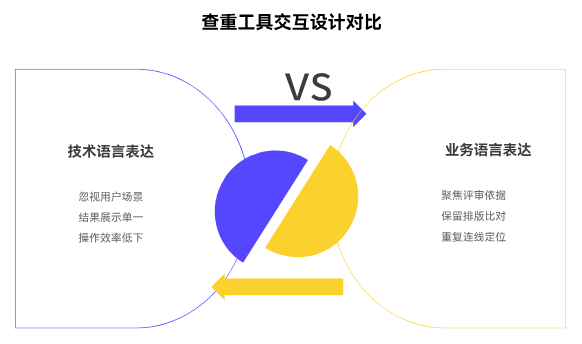
结语:交互设计的本质,是让技术服务于人的认知习惯
智能文档查重的竞争,正在从“算法精度”的单一维度,转向“算法+交互”的综合能力比拼。当多数产品还在比拼“重复率计算是否精准”时,领先者已在思考“如何让用户用最少的时间理解结果”。
毕竟,对于用户而言,一份能精准定位、清晰关联、贴合场景的查重报告,远比“99.9%的识别率”更有实际价值。智能文档查重的终极突破点,从来不是让机器更“聪明”,而是让机器的“聪明”能被人轻松“看见”。
欢迎体验我们的文档查重系统,感受专为解决实际问题而生的技术力量。




















 180
180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











