




 本文通过Spring/Mybatis/webmagic框架构建项目,详细介绍了爬取种子网站的过程,包括项目搭建、数据库设计、爬虫配置、逻辑编写,以及成果展示。
本文通过Spring/Mybatis/webmagic框架构建项目,详细介绍了爬取种子网站的过程,包括项目搭建、数据库设计、爬虫配置、逻辑编写,以及成果展示。
1. 概述
因为无聊,闲来没事做,故突发奇想,爬个种子,顺便学习爬虫。本文将介绍使用Spring/Mybatis/webmagic等框架构建项目并爬取种子磁链。
2. 项目搭建
如下图为本项目的工程结构,主要代码实现在Spider包中。

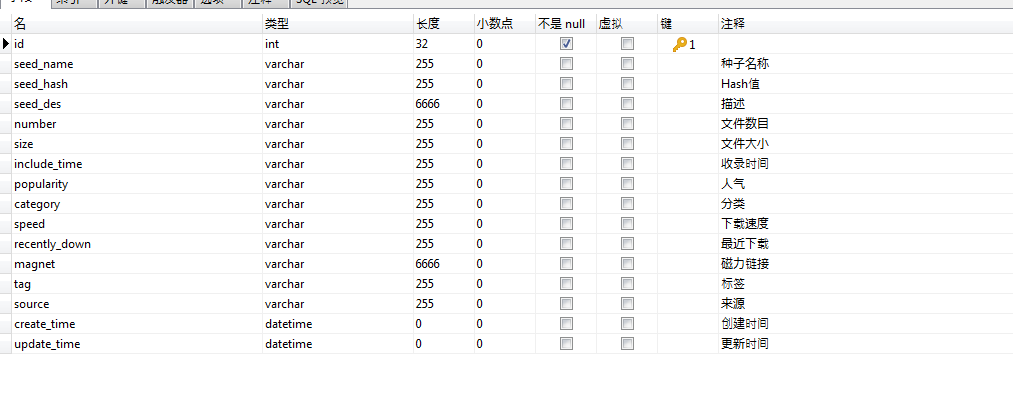
3. 数据库设计
参考众多的种子网站,找到描述种子的常用属性,如下:
4. 程序实现
1. 爬虫配置
在抓取种子之前,首先要确定所要抓取的网站地址、编码、抓取时间间隔、重试次数等信息,如下:
//设置网站源
private static String netSite="PushBT";
private Site site = Site.me().setDomain("http://www.pushbt.com")
.setCharset("UTF-8").setSleepTime(1000)//编码
.setRetryTimes(3); 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2681
2681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









