



通过数据堆叠、数据清洗、特征提取、特征选择、构建模型等方法,实现对泰坦尼克号生存人数的预测。因为是刚开始接触机器学习,所以会有很多模型还没学到,知识较为浅层,kaggle的得分是80
1.观察数据
通过泰坦尼克号比赛中,很多很多的资料中,有一个非常重要的点便是对数据的理解,我们要打一个比赛,要去分析一些数据的前提是我们对于数据足够的了解,知道它们之间的关系,了解他们的数据类型……
2.导入数据
首先我们将训练数据和测试数据进行纵向堆叠,方便数据处理。
#合并数据集,方便同时对两个数据集进行清洗
full = train.append( test , ignore_index = True )#使用append
print ('合并后的数据集:',full.shape)进行纵向堆叠
3.观察数据
在导入数据以后,我们没有办法直观的看到数据,所以我们便需要DataFrame的一些属性来让我们更好的去理解数据,接下来介绍几个经常用的观察数据的工具
.describe()
train_df.describe()
PassengerId Survived Pclass Age SibSp Parch Fare
count 891.000000 891.000000 891.000000 714.000000 891.000000 891.000000 891.000000
mean 446.000000 0.383838 2.308642 29.699118 0.523008 0.381594 32.204208
std 257.353842 0.486592 0.836071 14.526497 1.102743 0.806057 49.693429
min 1.000000 0.000000 1.000000 0.420000 0.000000 0.000000 0.000000
25% 223.500000 0.000000 2.000000 20.125000 0.000000 0.000000 7.910400
50% 446.000000 0.000000 3.000000 28.000000 0.000000 0.000000 14.454200
75% 668.500000 1.000000 3.000000 38.000000 1.000000 0.000000 31.000000
max 891.000000 1.000000 3.000000 80.000000 8.000000 6.000000 512.329200.info()
train_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB我们可以清晰的观察到我们的数据中是存在缺失值的,那我们怎么让缺失值更加直观的显示出来呢
full.isnull().sum()
Age 263
Cabin 1014
Embarked 2
Fare 1
Name 0
Parch 0
PassengerId 0
Pclass 0
Sex 0
SibSp 0
Survived 418
Ticket 0
dtype: int64在这用 describe 函数进行了描述,发现没有异常值,但是存在缺失值。我们发现数据总共有 1309 行。
其中数据类型列:年龄(Age)、船舱号(Cabin)里面有缺失数据:
1)年龄(Age)里面数据总数是 1046 条,缺失了 1309-1046=263
2)船票价格(Fare)里面数据总数是 1308 条,缺失了 1 条数据。
字符串列:
1)登船港口(Embarked)里面数据总数是 1307,只缺失了 2 条数据,缺失比较少
2)船舱号(Cabin)里面数据总数是 295,缺失了 1309-295=1014,缺失比较大。
这为我们下一步数据清洗指明了方向,只有知道哪些数据缺失数据,我们才能有针对性的处理。
4.数据预处理
1)对于缺失值较少的数据我们选择利用中位数,平均数等来进行适当的填充,例如刚刚的数据“Embarked”,"Fare",“Age”
from sklearn.impute import SimpleImputer
Embarked=full.loc[:,"Embarked"].values.reshape(-1,1)
imp_most=SimpleImputer(strategy="most_frequent")
full.loc[:,"Embarked"]=imp_most.fit_transform(Embarked)
Fare=full.loc[:,"Fare"].values.reshape(-1,1)
fare_mid=SimpleImputer(strategy="median")
full.loc[:,"Fare"]=fare_mid.fit_transform(Fare)
Age=full.loc[:,"Age"].values.reshape(-1,1)
Age_mid=SimpleImputer(strategy="mean")
full.loc[:,"Age"]=Age_mid.fit_transform(Age)
print(full.isnull().sum())
Age 0
Cabin 1014
Embarked 0
Fare 0
Name 0
Parch 0
PassengerId 0
Pclass 0
Sex 0
SibSp 0
Survived 418
Ticket 0
dtype: int64”Embarked”利用众数填充,"Fare"利用中值填充,"Age"利用均值填充
2)对于缺失值较多的特征,我们一般选择删除,对于“Cabin”特征,我选择了删除,因为确实的数据实在是太多了,没有办法进行处理。
5.处理分类性特征:哑变量
from sklearn.preprocessing import OneHotEncoder
X=full.loc[:,"Embarked"].values.reshape(-1,1)
enc=OneHotEncoder(categories='auto').fit(X)
result=enc.transform(X).toarray()
result
array([[0., 0., 1.],
[1., 0., 0.],
[0., 0., 1.],
...,
[0., 0., 1.],
[0., 0., 1.],
[1., 0., 0.]])这时会有人好奇这是什么,为什么要用这个?明明数据已经补充完整了呀
为什么要用哑变量
首先我们观察刚刚的数据可以发现我们的数据类型有int型也有object型,但是我目前学习到的机器学习算法只能处理数值型数据,所以我们需要对数据进行编码,也就是把文字型数据转换为数值型,而这也就是我们的编码和哑变量
有三种特征:
1)名义变量
舱门类(SCQ),性别,这一类特征相互独立,没有任何联系
2)有序变量
学历(小学,初中,高中),有高有低,但是我们不能说小学+初中=高中,这类特征相互之间无法计算
3)有距变量
体重,有高有低,而且可以进行相互的计算,例如45kg+95kg=140kg
而对于我们刚刚的名义变量我们便只能使用哑变量的方法

full.head()

这里的新特征012便是我们利用独热编码创造出来的新特征
在这里我必要要提一下独热编码的重要接口
.get——feature_names()
enc.get_feature_names()
array(['x0_C', 'x0_Q', 'x0_S'], dtype=object)这个接口是系统自动根据你进行处理特征的种类等来命名的一个接口,我们接下来便可以利用这个接口来命名我们的新特征
同样我们利用相同的方法处理我们的“Pclass”特征
6.删除一些无用特征
full.drop('Name',axis=1,inplace=True)
full.drop('Cabin',axis=1,inplace=True)
full.drop('Ticket',axis=1,inplace=True)我们删除这些特征,因为我们认为这些特征是无用的(但是其实是可以进行处理的,但是我不太会)
最后让我们来看一下我们处理好的数据

到这里我们的数据便处理完毕了
7.构建模型选择模型
(1)建立训练数据集和测试数据集,从原始数据集(名名为 source,即前 891 行数据)中拆分出训练数据集和测试数据集。
(2)选择机器学习算法
在这里尝试了不同的机器学习算法,并对每个算法进行了评估。
from sklearn.model_selection import train_test_split
for i in range(0,4):
train_X, test_X, train_y, test_y = train_test_split(source_X ,
source_y,
train_size=size[i],
random_state=5)
#逻辑回归
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit( train_X , train_y )
scorelist[0].append(model.score(test_X , test_y ))
#随机森林Random Forests Model
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100)
model.fit( train_X , train_y )
scorelist[1].append(model.score(test_X , test_y ))
#支持向量机Support Vector Machines
from sklearn.svm import SVC
model = SVC()
model.fit( train_X , train_y )
scorelist[2].append(model.score(test_X , test_y ))
#梯度提升决策分类Gradient Boosting Classifier
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier()
model.fit( train_X , train_y )
scorelist[3].append(model.score(test_X , test_y ))
#KNN最邻近算法 K-nearest neighbors
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors = 3)
model.fit( train_X , train_y )
scorelist[4].append(model.score(test_X , test_y ))
#朴素贝叶斯分类 Gaussian Naive Bayes
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit( train_X , train_y )
scorelist[5].append(model.score(test_X , test_y ))
# 分类问题,score得到的是模型的正确率
#print(model.score(test_X , test_y ))
这并不能让我们直观的发现那个模型是最合适的,这时便需要我们的画图工具了,利用画图工具来更好的让我们观察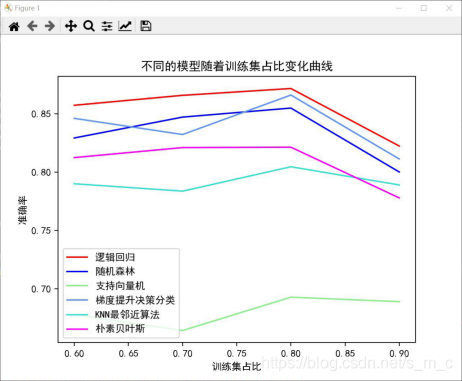
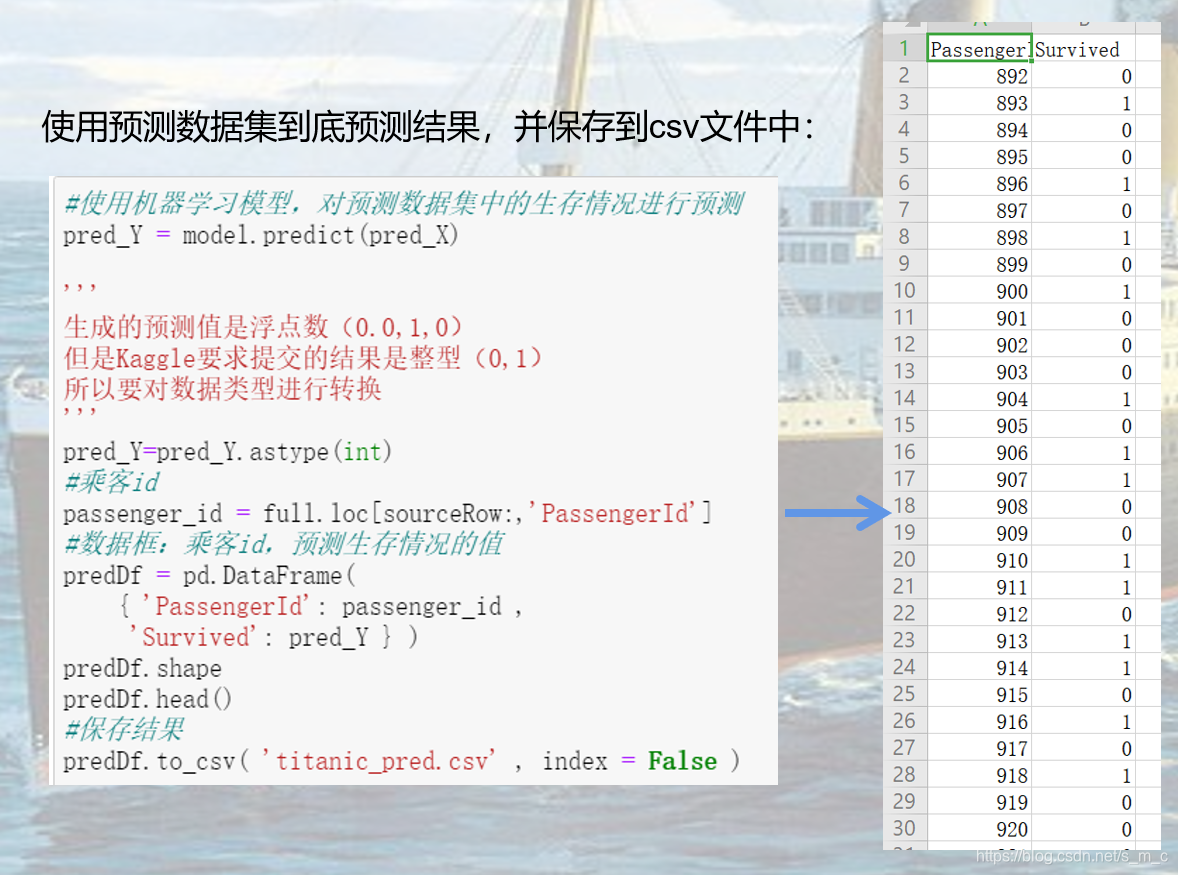
使用预测数据集到底预测结果,并保存到 csv 文件中:
总结:
选择了一个比较基础的kaggle项目,目的是熟悉kaggle竞赛流程,深入分析理解项目中的每一行个过程,这个项目对数据的特征处理那一步 进行了比较多的处理,从中学习到了很多。
****8.通过比赛认识到的不足
通过对其他学长学姐代码的观摩,我认识到了我的很多的不足,在这里我把我的笔记展示给大家

比较好的画图网站
我再来推荐一些博主写的关于画图工具的网站

















 1491
1491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









