







 本文介绍了如何使用Locust进行HTTP性能测试,升级至最新版本并处理了任务集和HttpLocust的迁移。通过实例演示了如何编写测试用例,执行并发测试,分析QPS和TPS指标。
本文介绍了如何使用Locust进行HTTP性能测试,升级至最新版本并处理了任务集和HttpLocust的迁移。通过实例演示了如何编写测试用例,执行并发测试,分析QPS和TPS指标。
前言
Locust并发机制摈弃了进程和线程,采用协程(gevent)机制,避免了系统级资源调度,可以大大提高单机并发能力。
本篇为学习与实践的记录,包含碰到的问题处理。
安装locust
可通过pip直接安装,在网上看到有通过命令 pip install locustio 或 pip install locustio --user ,执行命令时出错,给出了提示: Locust package has moved from ‘locustio’ to ‘locust’。
于是换成了 pip install locust ,安装成功。
locust --help 查看命令参数。
locust -V 查看版本,当前使用版本为 2.12.0。
编写测试用例
以前的版本:
from locust import HttpLocust, TaskSet, task
class UserBehavior(TaskSet):
@task
def baidu_page(self):
self.client.get('/')
class WebSiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 3000
max_wait = 6000
根据现在版本修改后:
from locust import HttpUser, TaskSet, task
class UserBehavior(TaskSet):
@task
def baidu_page(self):
self.client.get('/')
class WebSiteUser(HttpUser):
tasks= [UserBehavior] # 此处实例名不要再用task_set,会产生冲突
min_wait = 3000 # 用户执行事务之间等待的最小值,单位为毫秒
max_wait = 6000 # 用户执行事务之间等待的最大值,单位为毫秒
min_wait和max_wait 根据用户行为设置,一般3~6秒接近用户真实行为。
关于HttpLocust
以下是导入HttpLocust时的提示:
class DeprecatedHttpLocustClass(metaclass=deprecated_locust_meta_class( # type: ignore "The HttpLocust class has been renamed to HttpUser in version 1.0. " "For more info see: https://docs.locust.io/en/latest/changelog.html#changelog-1-0" ))
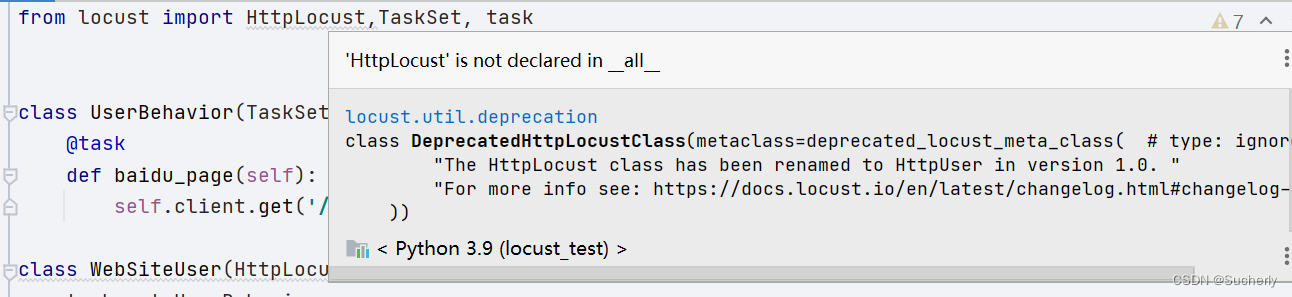
故需要将继承HttpLocust改为继承HttpUser
关于task_set
由于继承的是HttpUser,而User中有task_set且已被废弃,之前的 task_set = UserBehavior 不能再使用task_set命名,否则会报如下错误:
DeprecationWarning: Usage of User.task_set is deprecated since version 1.0.
Set the tasks attribute instead (tasks = [UserBehavior])
根据提示,建议修改成tasks= [UserBehavior]。
如果改成其他的如task_create=UserBehavior,会报如下错误:
Exception: No tasks defined on WebSiteUser. Use the @task decorator or set the 'tasks' attribute of the User (or mark it as abstract = True if you only
intend to subclass it)
执行性能测试
启动
命令: locust -f 脚本文件 --host=被测试应用的url地址 --web-host=locust访问ip
locust -f test.py --host=https://www.baidu.com --web-host="127.0.0.1"
启动结果:

locust使用8089端口。浏览器访问:http://127.0.0.1:8089。
- –web-host指定locust启动后的访问ip,默认是
0.0.0.0
也可先修改\Lib\site-packages\locust\argument_parser.py中的--web-host参数default默认值为 “127.0.0.1”。执行命令的时候便不用传该参数了:
locust -f test.py --host=https://www.baidu.com
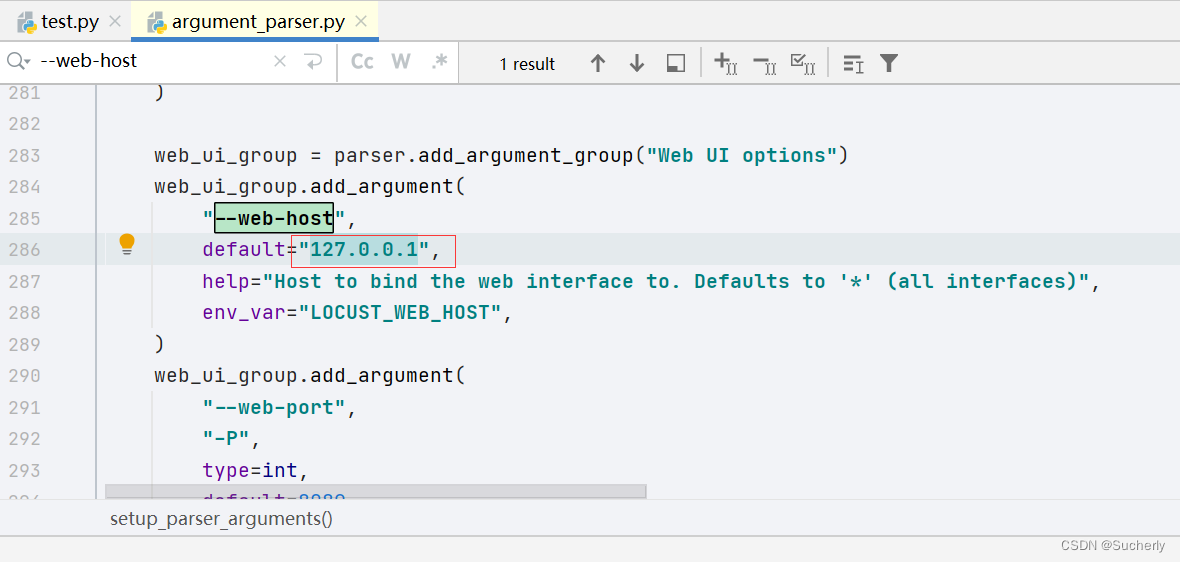
启动结果:

浏览器访问http://127.0.0.1:8089:
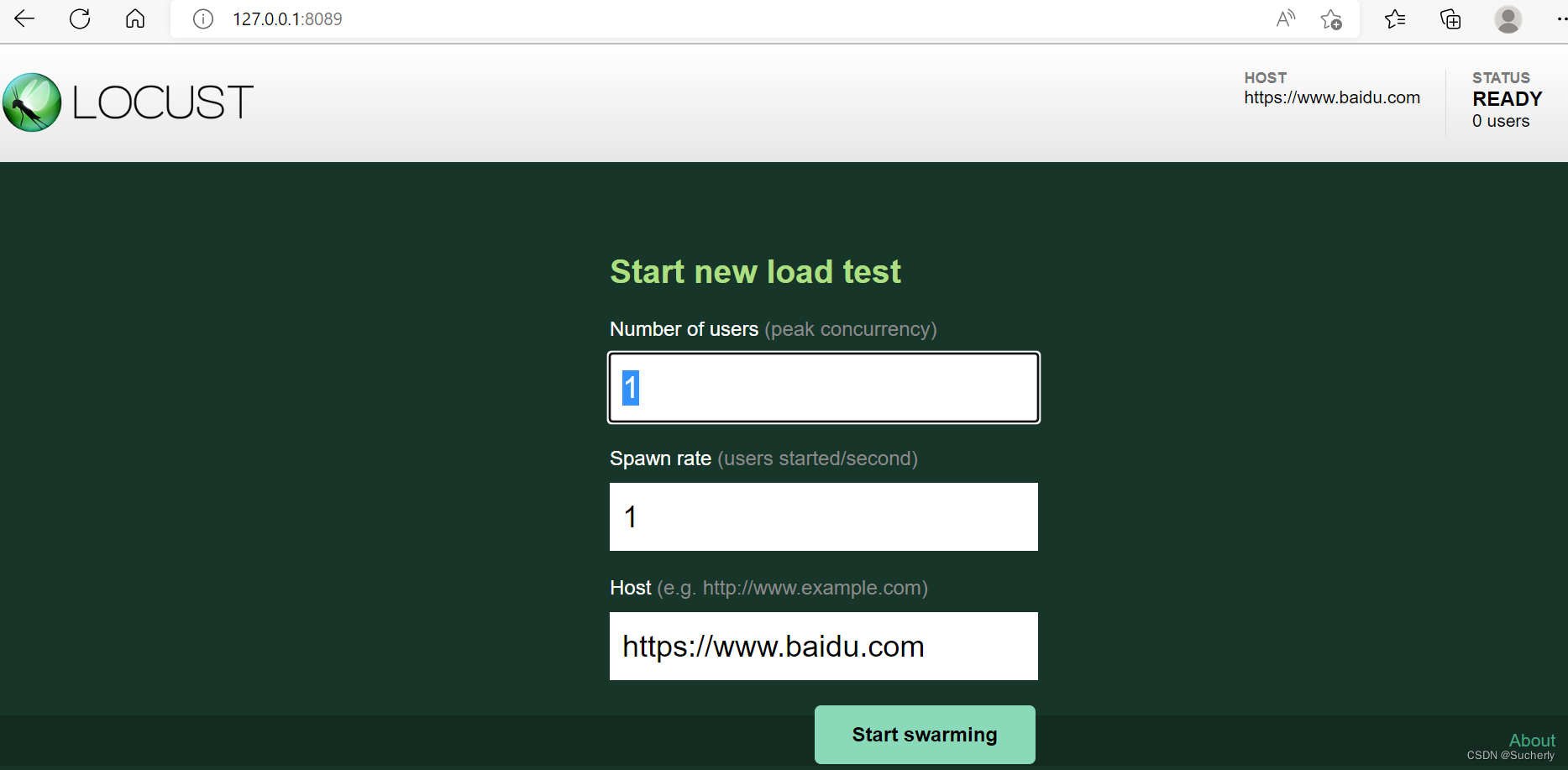
执行
参数说明:
- Number of users:模拟用户数
- Spawn rate:每秒启动的用户数
- Host:访问地址
现设置 Number of users 为20,Spawn rate 为5,点击 Start swarming 按钮,开始运行:

字段说明:
- type:请求类型
- name:请求路径
- requests:当前请求的数量
- fails:当前请求失败的数量
- median:中间值,单位为毫秒。表示一半的服务器响应时间低于该值,而另一半高于该值。
- 90%ile:单位为毫秒。90%的响应时间小于该值。
- 99%ile:单位为毫秒。90%的响应时间小于该值。
- average:平均响应时间,单位为毫秒。
- min:最小响应时间,单位为毫秒。
- max:最大响应时间,单位为毫秒。
- average size:平均每个请求的数据量,单位为字节;
- current RPS(requests per second):当前每秒钟处理请求的数量,即RPS。(以前叫reqs/sec:每秒钟处理请求的数量,即QPS;)
- current fails/sec:当前每秒钟请求失败的数量。
最后一行 Aggregated 是合计。以前叫 Total。
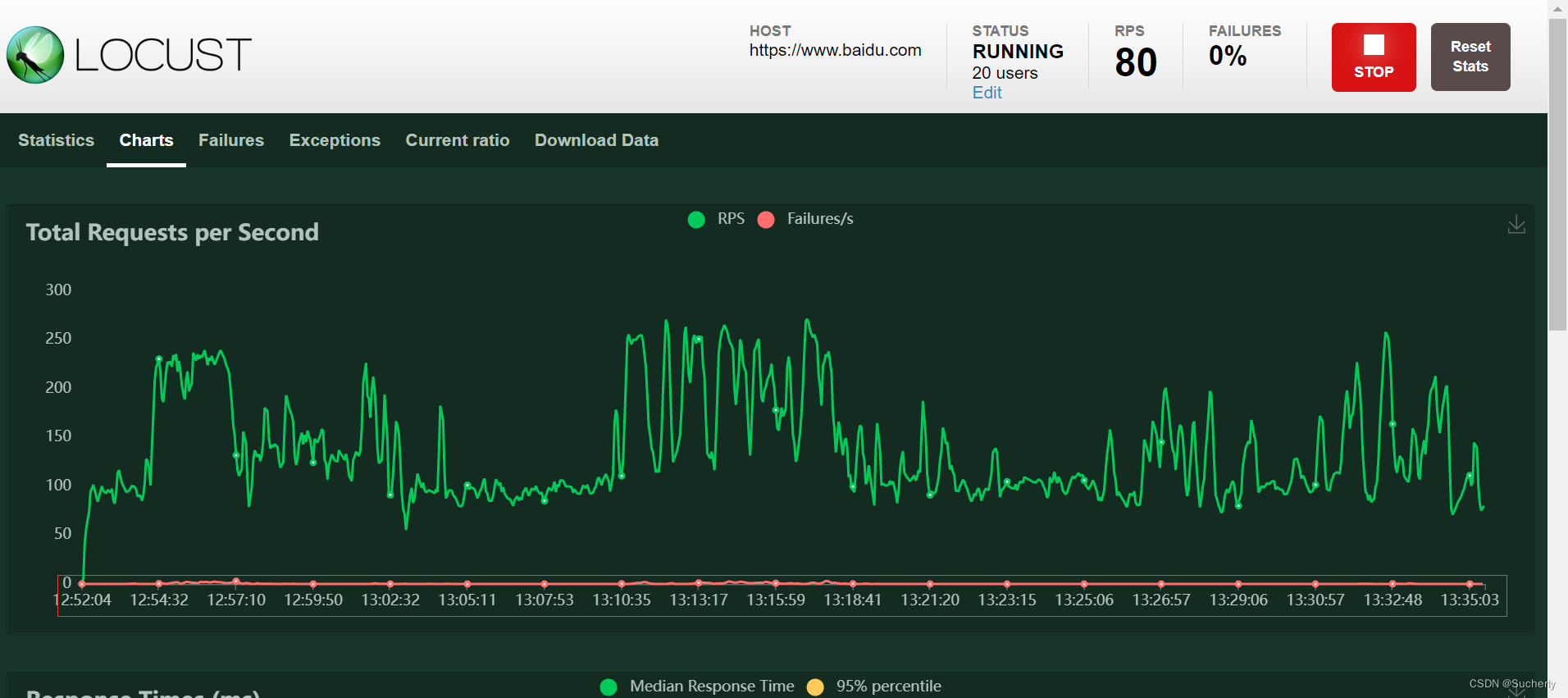
这个页面没有运行时长的统计,可以切换到 Charts 看图表中的时长:
或者切换到 Download Data 中,点击 Download Report ,会产生一个html 报告(包括Request Statistics, Response Time Statistics, Failures Statistics, Charts, Final ratio):
性能测试分析
常用词
- QPS : Query Per Second每秒查询率。等效于RPS(每秒的响应请求数)。
QPS = 并发量 / 平均响应时间
RPS = 请求数/秒 =总请求数 / ( 进程总数 * 请求时间 )
- TPS : Transactions Per Second(每秒传输的事物处理个数),即服务器每秒处理的事务数。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。
TPS=事务数/时间(秒)
- PV:即 page view,页面浏览量。用户每一次对网站中的每个页面访问均被记录1次。用户对同一页面的多次刷新,访问量累计。
- UV:即 Unique visitor,独立访客。通过客户端的cookies实现。即同一页面,客户端多次点击只计算一次,访问量不累计。
- IP:即 Internet Protocol,本意本是指网络协议,在数据统计这块指通过ip的访问量。即同一页面,客户端使用同一个IP访问多次只计算一次,访问量不累计。
其他计算:
日PV=QPS*60*60*24 //即QPS乘以一天的秒数
服务器数量 = ceil( 每天总PV / 单台服务器每天总PV )
峰值QPS=(日PV*80%)/(60*60*24*20%)//通用公式每天80%的访问集中在20%的时间里,这20%时间叫做峰值时间
服务器数=峰值时间每秒QPS / 单台机器的QPS
(参考https://blog.youkuaiyun.com/weixin_44370919/article/details/104927621)
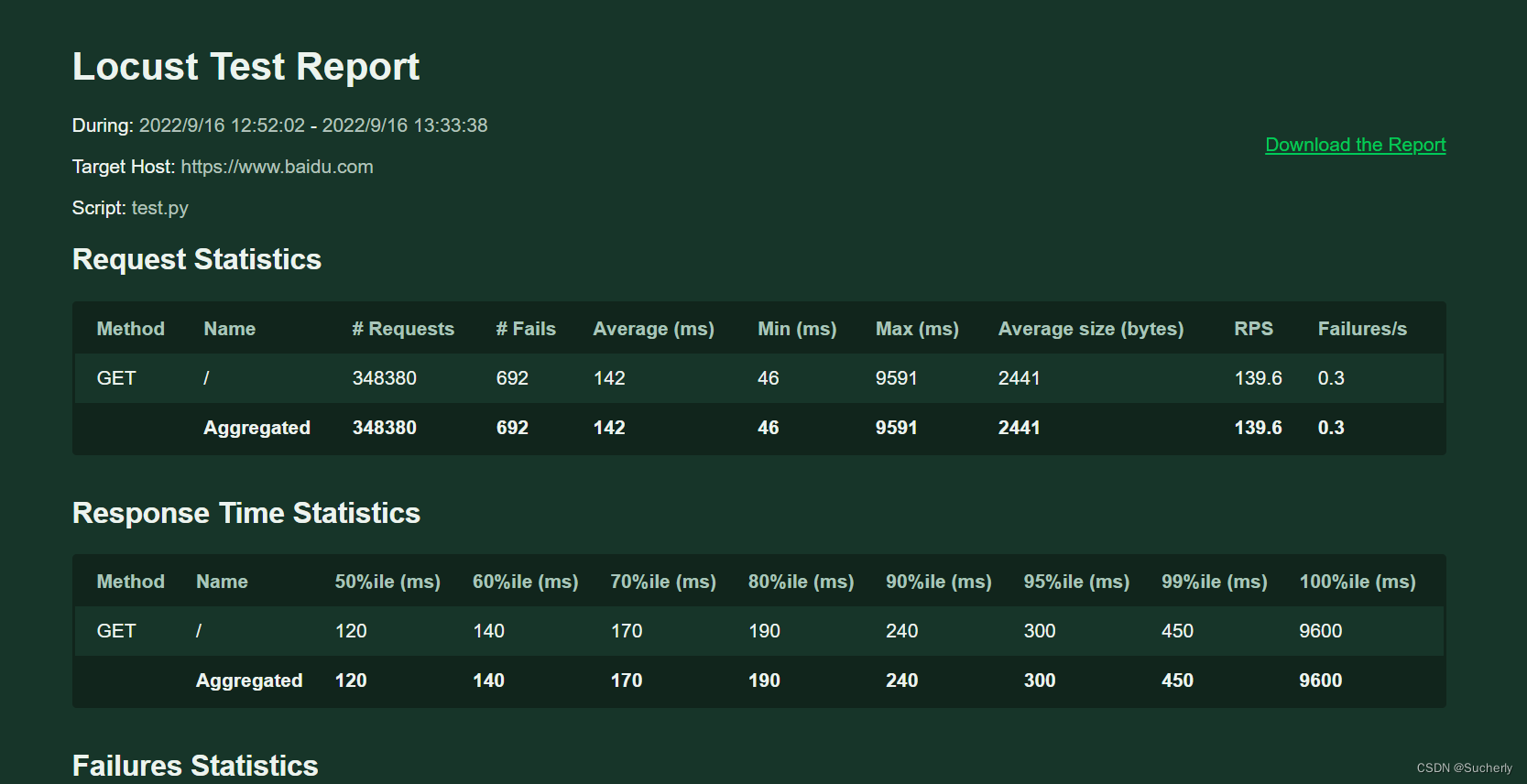
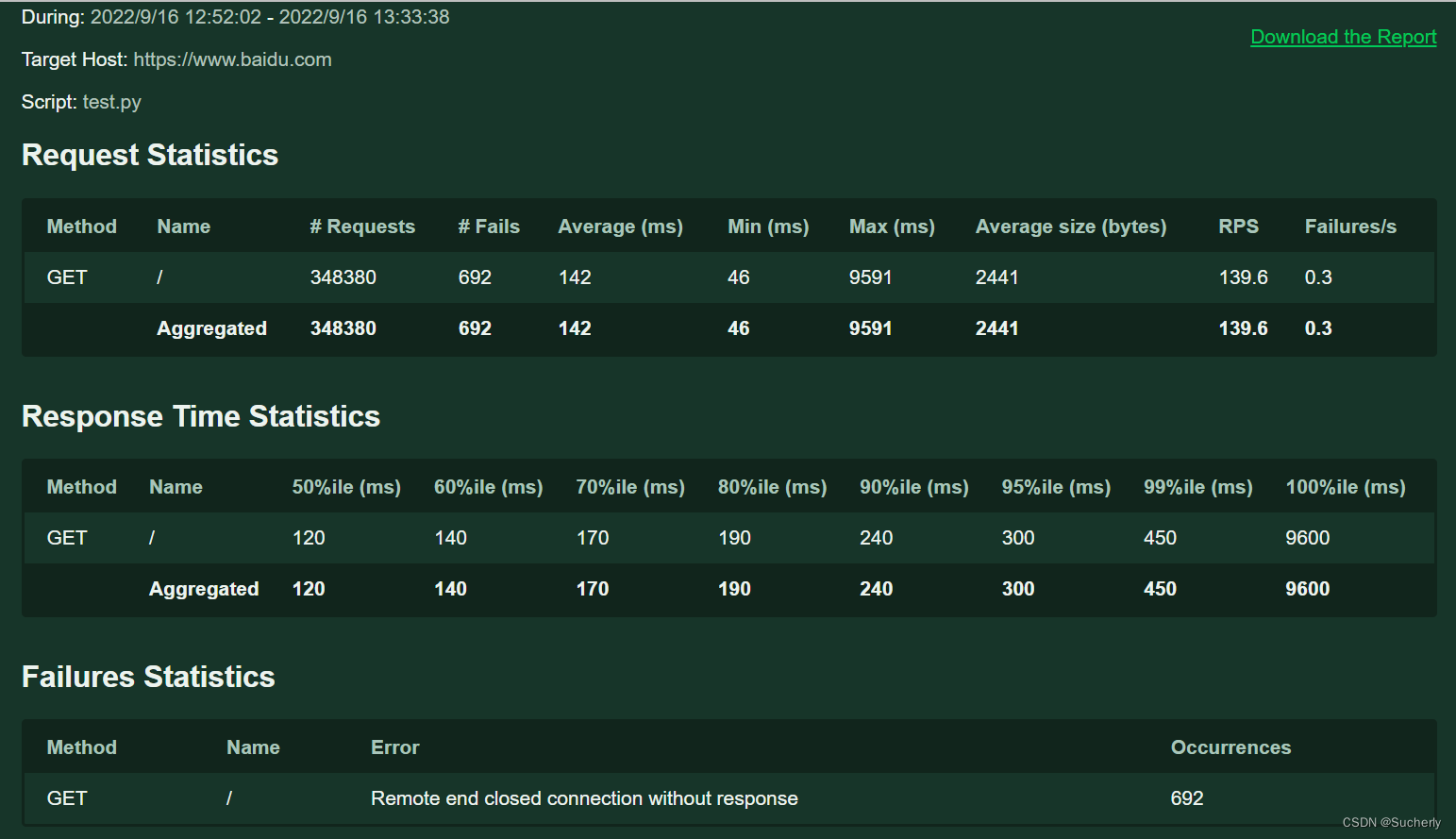
以下面的单次报告作描述(仅参考):
虚拟用户数为20,每秒产生5个虚拟用户数,运行时长为41分32秒(即2492s)时,平均响应时间为0.142秒,99%的响应时间小于1秒。但最大响应时间是9.591秒,时间过长。
平均每秒请求数为139.6。
此外,在348380个请求中,有692个请求失败,失败率为0.198%,失败率较高,平均每秒会有0.3个请求失败,失败原因是远程端连接关闭无响应。
实际情况需要根据需求去确定测试、进行分析、再总结。先写到这,后续更新。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









