



今天跟大家分享一下如何将图片转为excel表格文件?
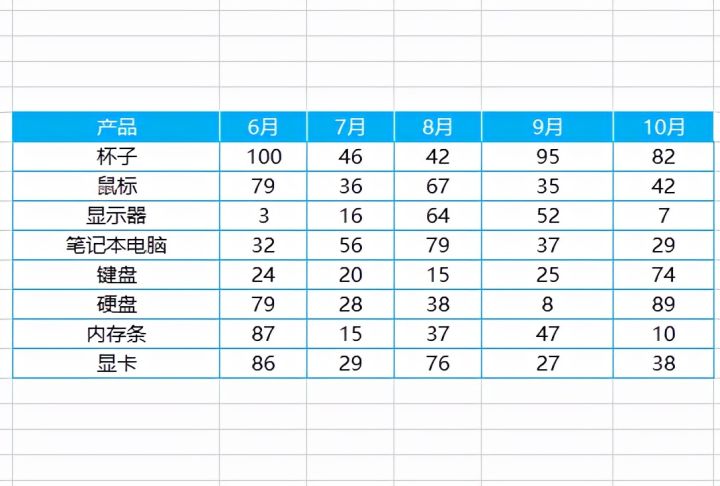
1.如下图是一个表格图片,现在我们想要将图片表格转为excel表格
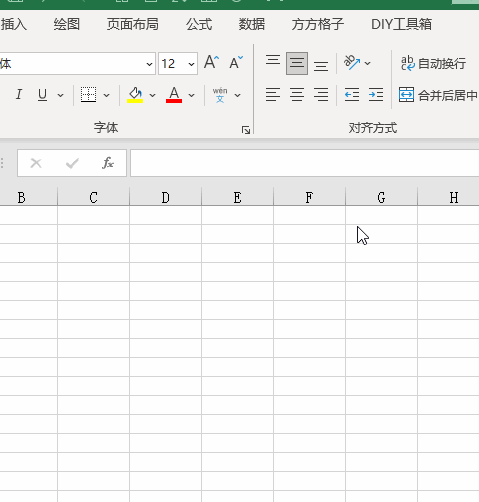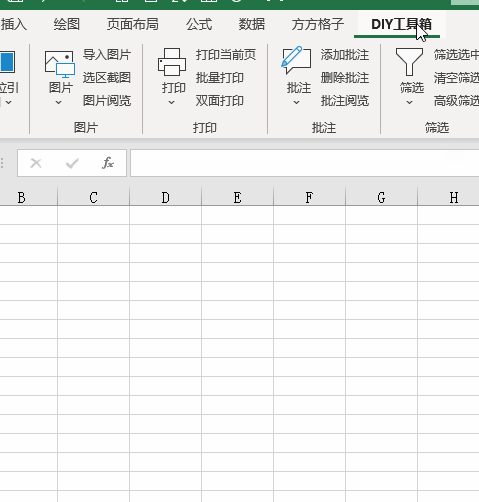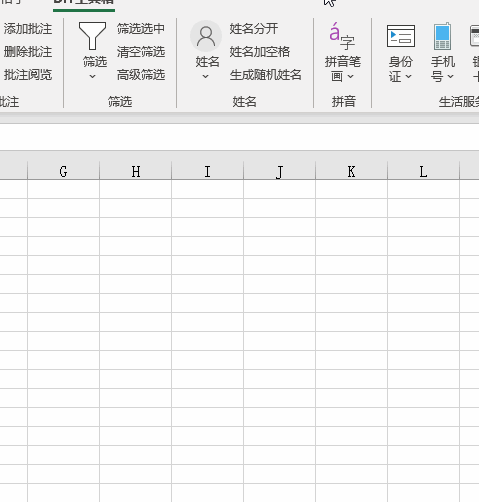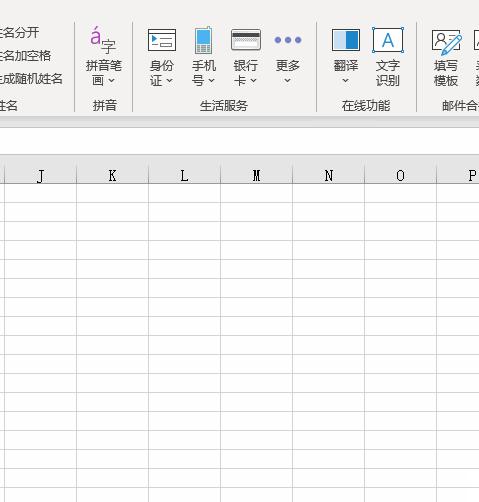
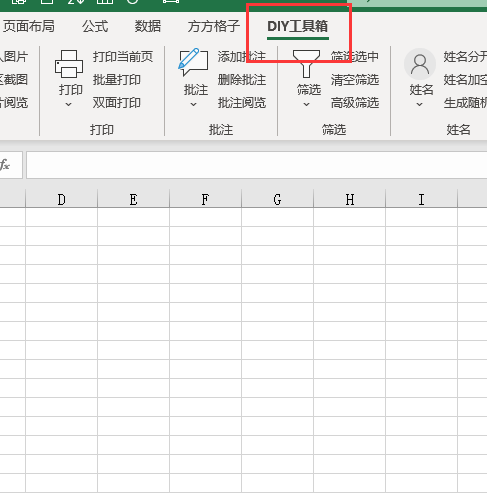
2.首先我们打开excel文件,点击【DIY工具箱】
3.选择【文字识别】
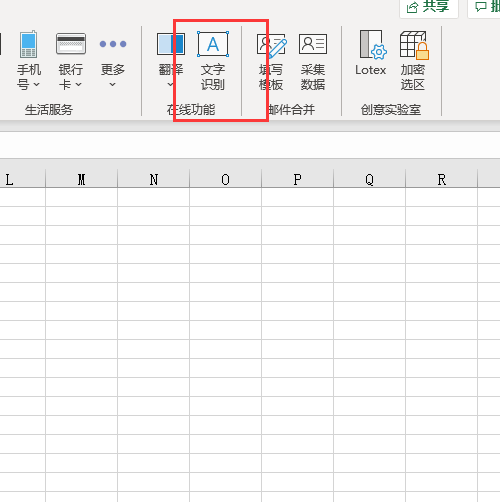
4.点击【选择】
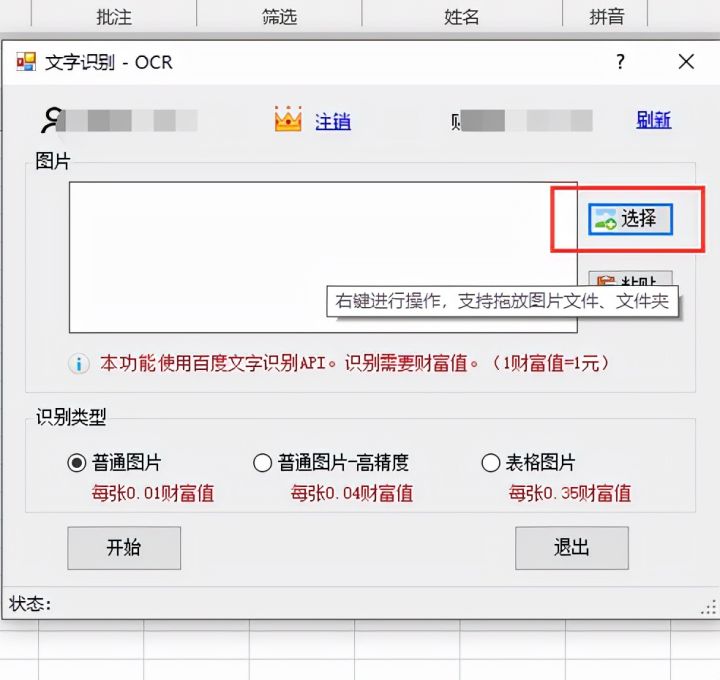
5.点击【表格图片】,选择【开始】

6.最终完成效果如下图
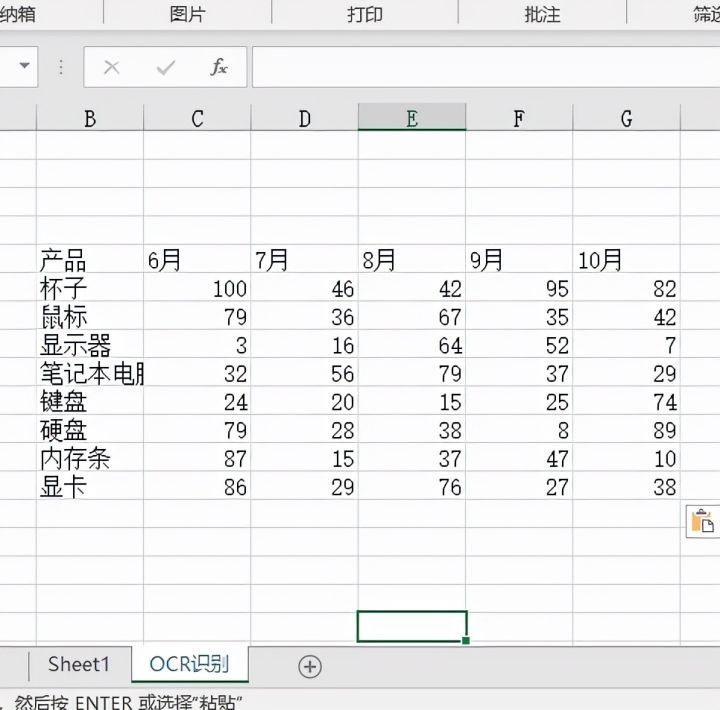
 本文介绍了如何将含有表格的图片转换为Excel文件的步骤。通过使用Excel的DIY工具箱,选择文字识别功能,然后选取表格图片并启动转换,可以快速将表格图片转换成可编辑的Excel表格,方便数据处理和编辑。
本文介绍了如何将含有表格的图片转换为Excel文件的步骤。通过使用Excel的DIY工具箱,选择文字识别功能,然后选取表格图片并启动转换,可以快速将表格图片转换成可编辑的Excel表格,方便数据处理和编辑。
今天跟大家分享一下如何将图片转为excel表格文件?
1.如下图是一个表格图片,现在我们想要将图片表格转为excel表格
2.首先我们打开excel文件,点击【DIY工具箱】
3.选择【文字识别】
4.点击【选择】
5.点击【表格图片】,选择【开始】
6.最终完成效果如下图
 4036
4036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























