



有时收集数据,我们需要的数据可能禁止复制粘贴或者下载,但是它已经呈现或者我们拥有该图片。
为了获取数据图片里面的数据,我们可以将其转换成表格数据。
首先登录腾讯qq,借助QQ截图的一项功能来完成转换。
演示图片如图:
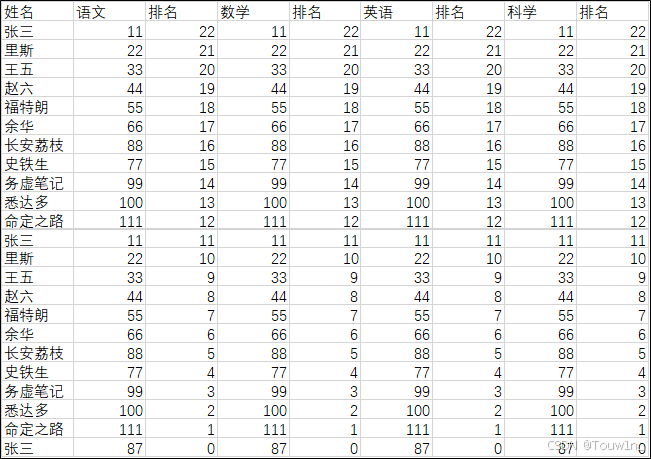
1.对一个安全的对象发送该图片,并双击放大该图片:
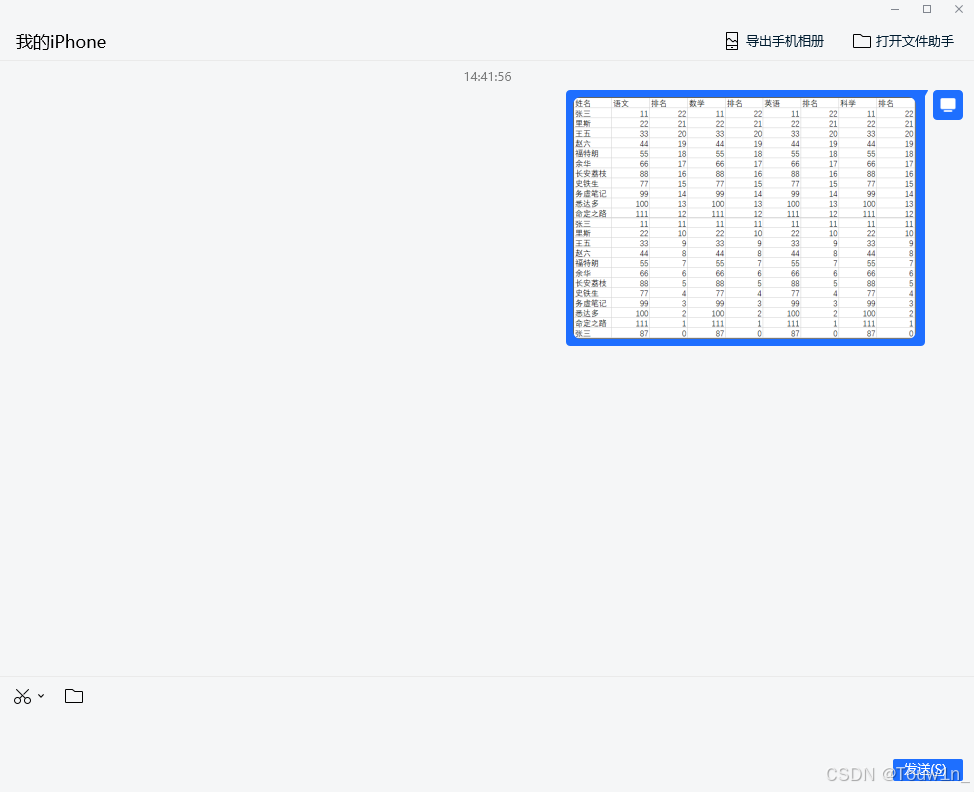
2.选择提取图中文字:
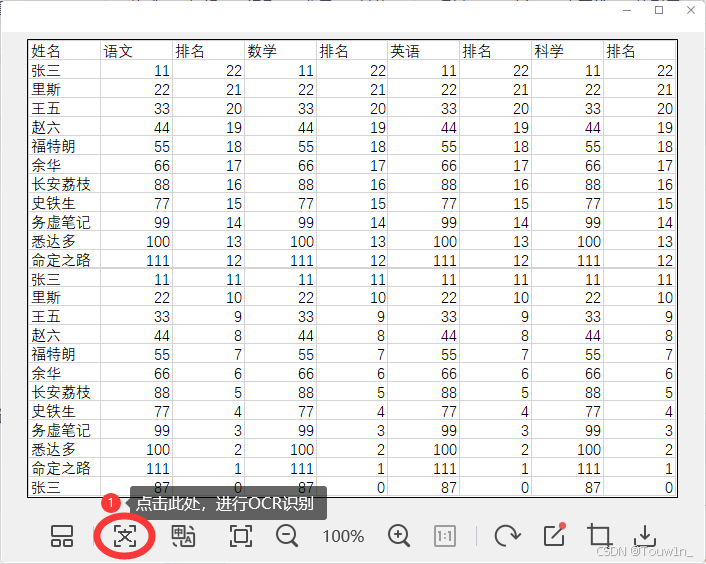
3.选择转换为在线图片
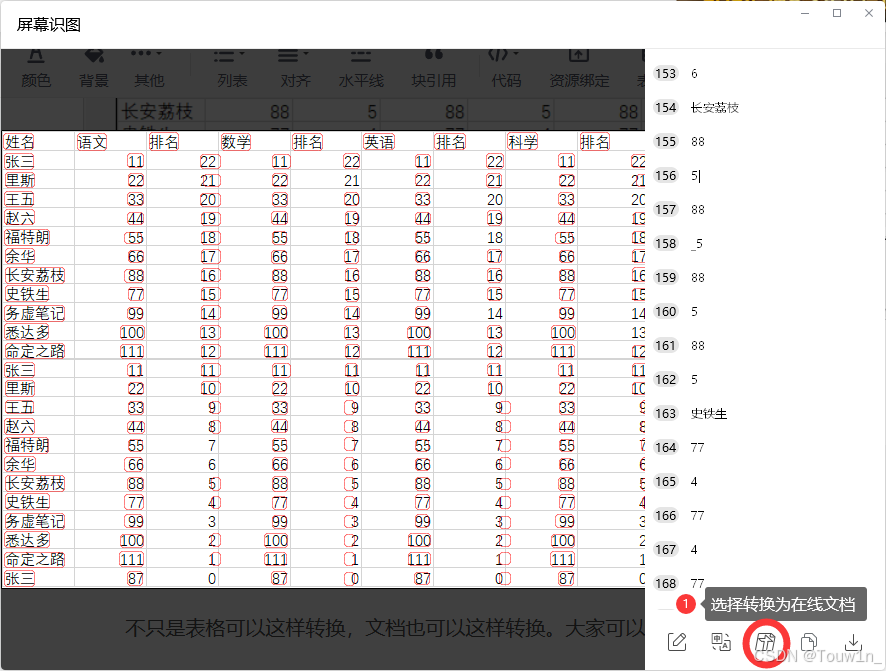
4.等待图片识别结果导入腾讯文档,ctrl+A 全选内容并复制:
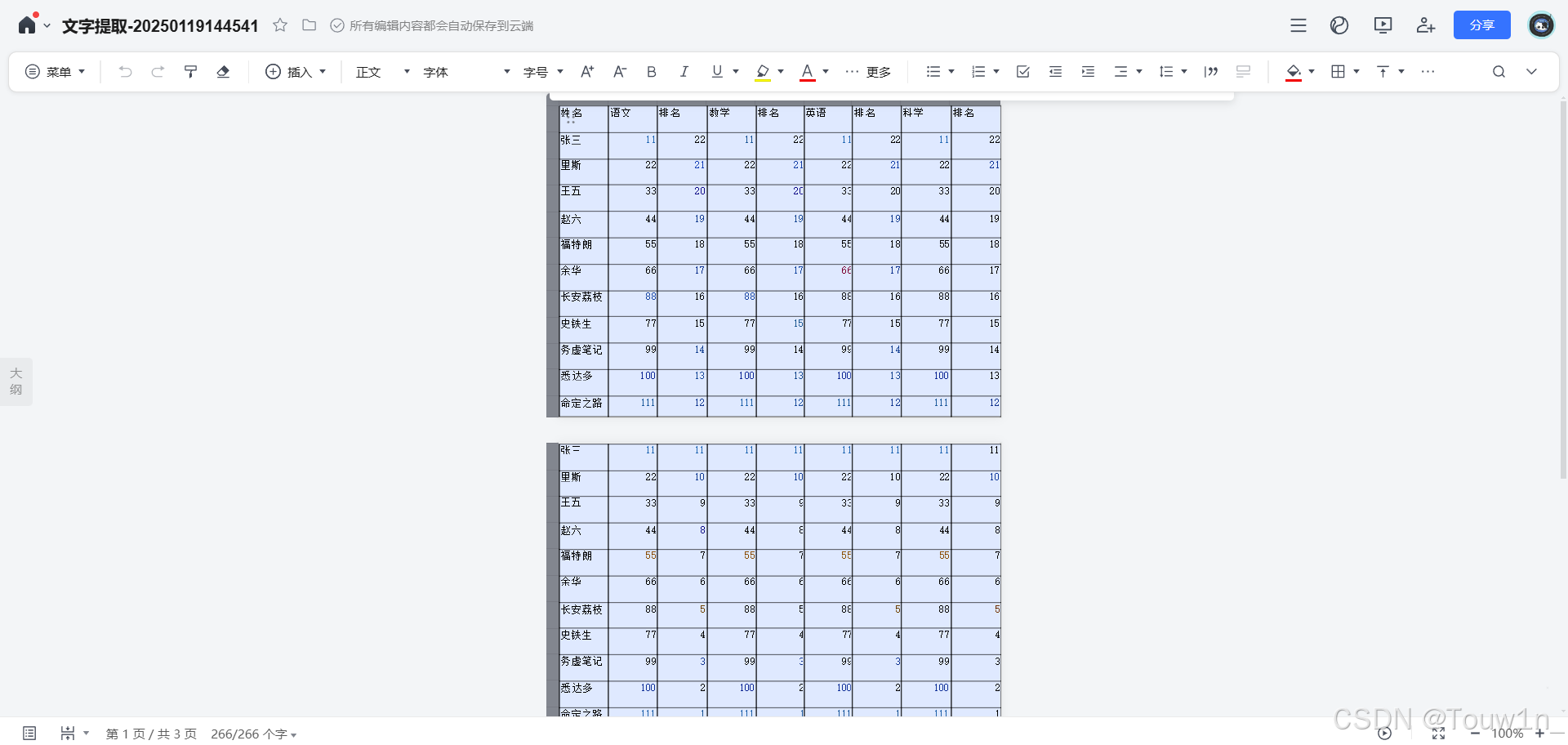
5.创建一个新的excel表格,并将复制到excel表格里,并调整一下格式:
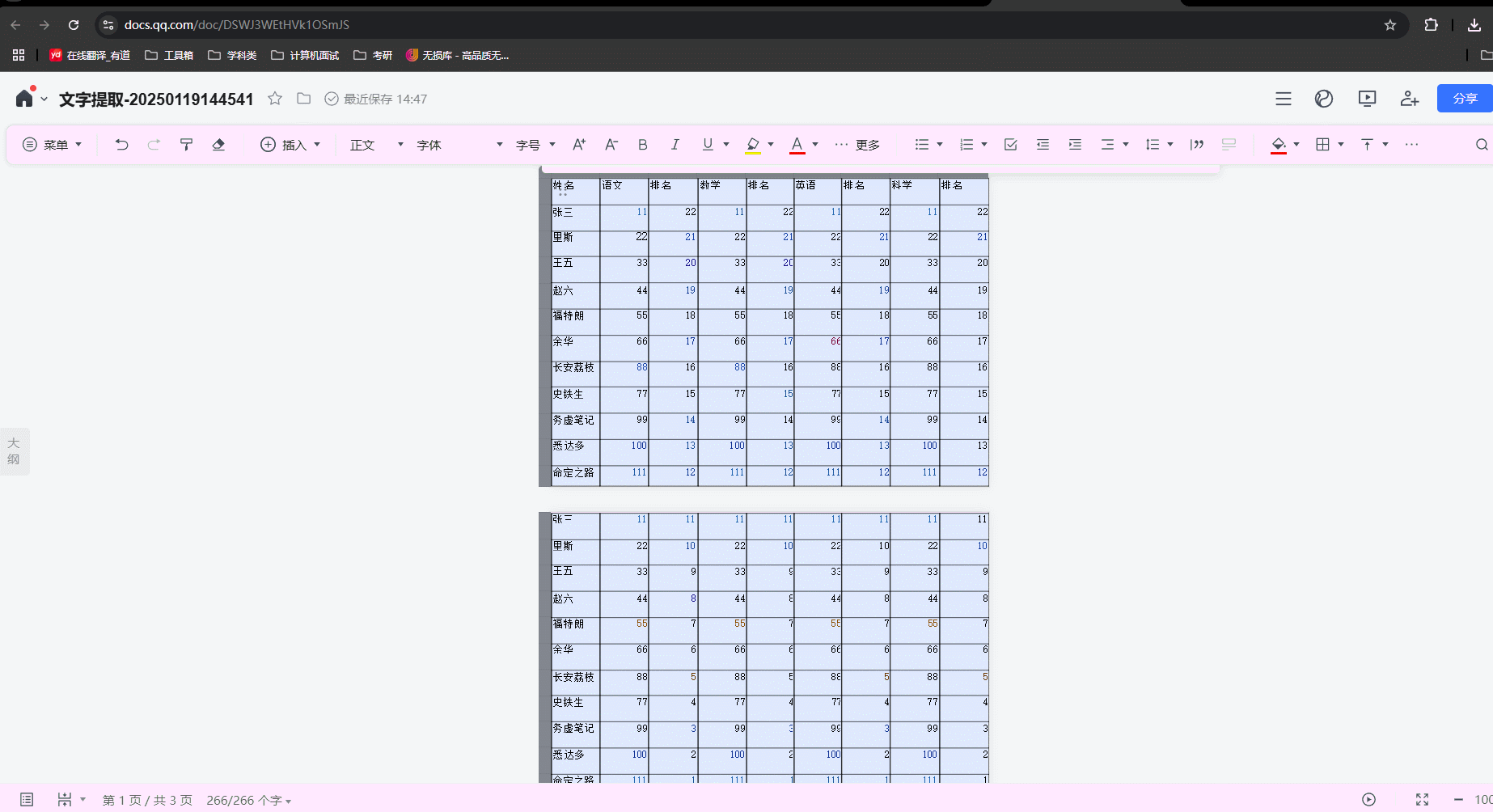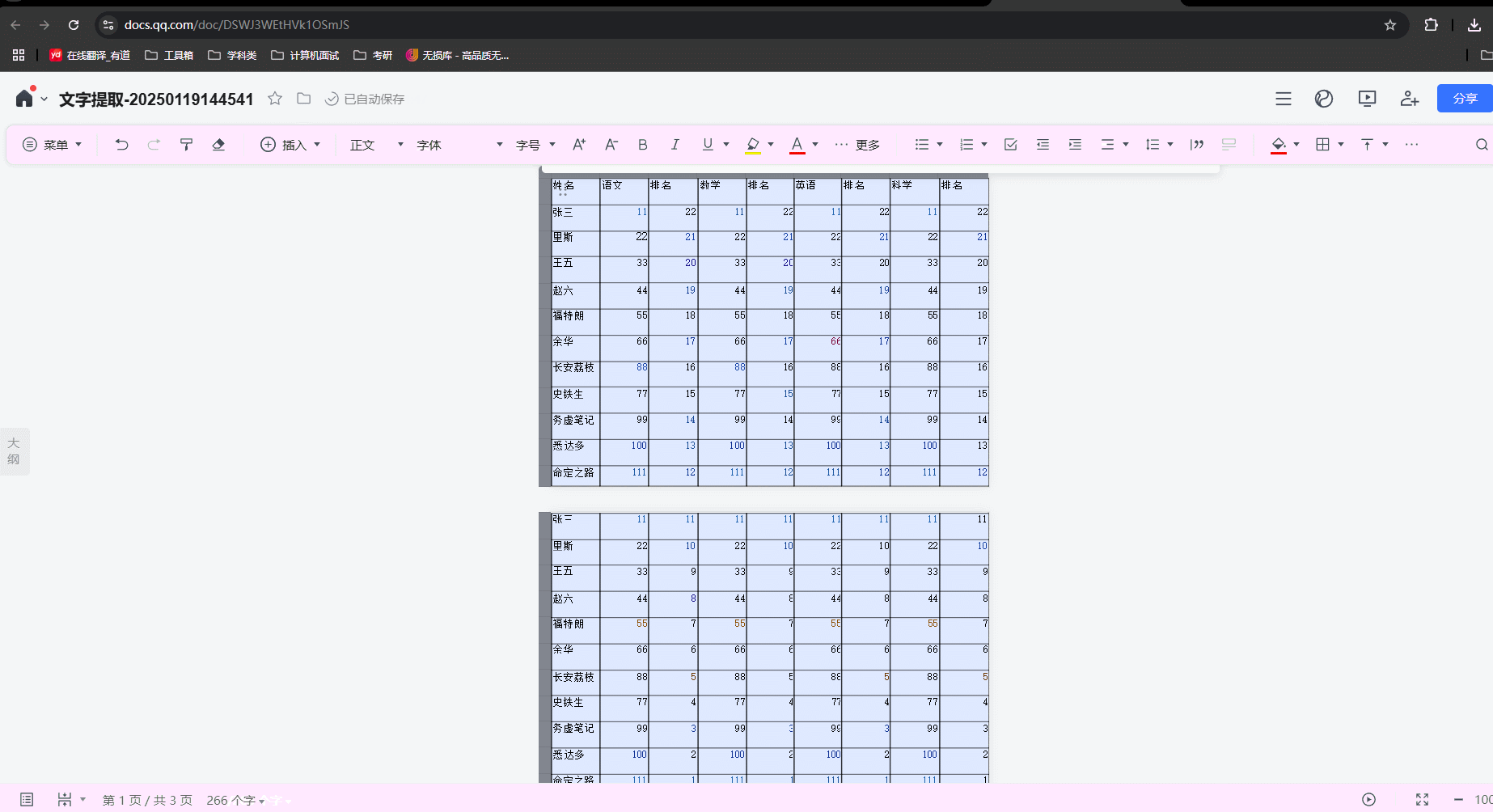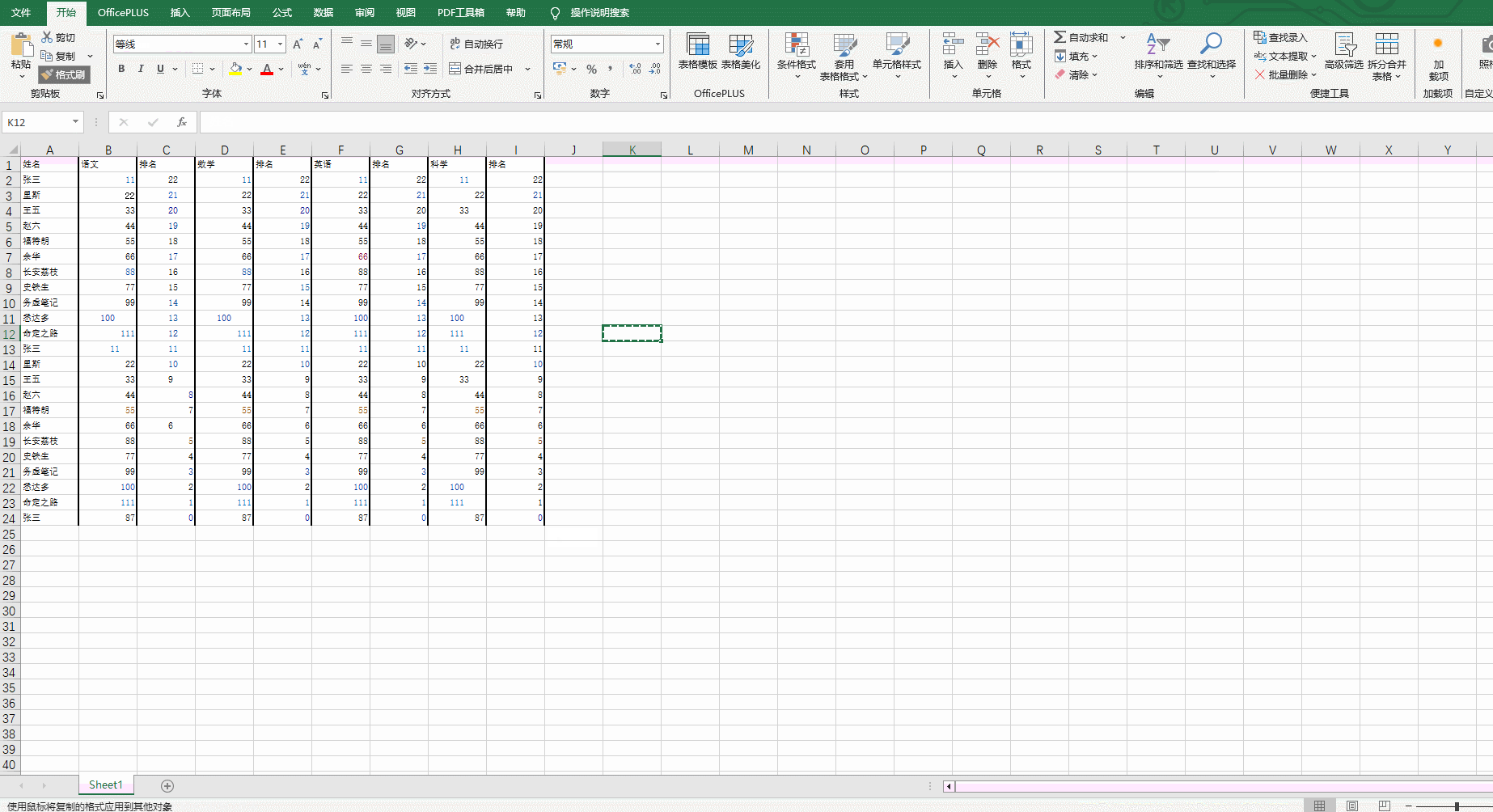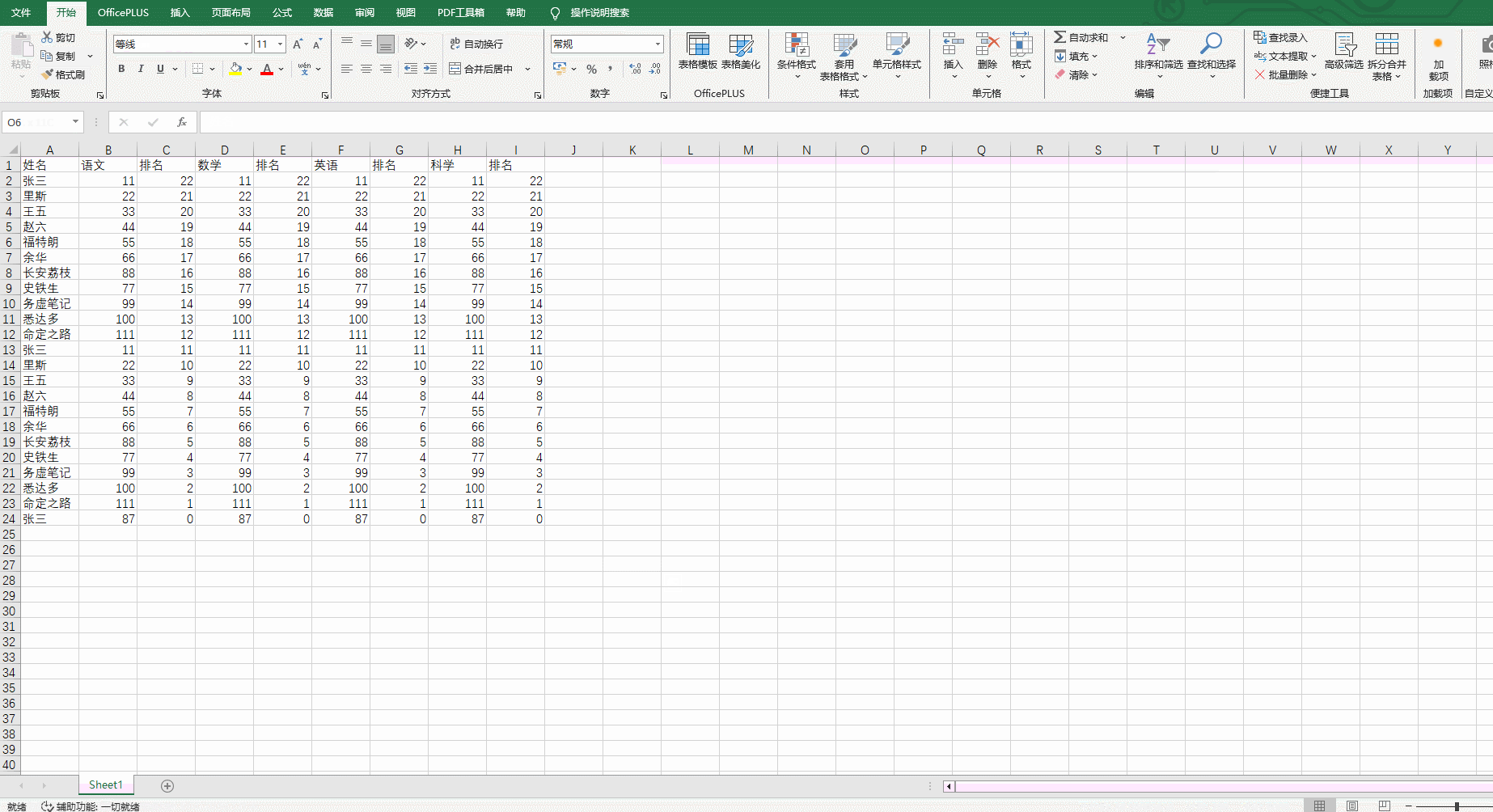
不只是表格可以这样转换,文档也可以这样转换。大家可以动手试试看。
祝大家天天开心!

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









