<think>
我们正在处理数据库重构任务,需要将user表中的两个字段(atype和btype)拆分到一个新的关联表usertype中。新表包含三个关键字段:id(主键)、user_id(外键关联user表)、type(标识是atype还是btype)、value(存储原始值)。核心挑战是如何在迁移过程中保障数据零丢失。
以下是完整解决方案:
### 一、数据迁移保障机制
1. **原子事务操作**
将整个迁移过程置于单个事务中,确保迁移失败时自动回滚:
```sql
START TRANSACTION; -- 开始事务
-- 创建临时备份表(结构同user表)
CREATE TABLE user_backup LIKE user;
INSERT INTO user_backup SELECT * FROM user;
-- 迁移atype字段
INSERT INTO usertype (user_id, type, value)
SELECT id, 'atype', atype FROM user WHERE atype IS NOT NULL;
-- 迁移btype字段
INSERT INTO usertype (user_id, type, value)
SELECT id, 'btype', btype FROM user WHERE btype IS NOT NULL;
-- 验证迁移完整性(示例校验逻辑)
SET @expected_rows = (SELECT COUNT(*) FROM user WHERE atype IS NOT NULL OR btype IS NOT NULL);
SET @actual_rows = (SELECT COUNT(*) FROM usertype);
-- 完整性校验失败则回滚
IF @expected_rows != @actual_rows THEN
ROLLBACK;
SIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = 'Data inconsistency detected';
ELSE
-- 删除旧字段
ALTER TABLE user DROP COLUMN atype, DROP COLUMN btype;
COMMIT; -- 提交事务
END IF;
```
*关键点*:事务内完成备份→迁移→校验→删除操作链[^1]。
2. **分段迁移与断点续传**
处理亿级数据表时,采用分段迁移策略:
```sql
-- 迁移脚本伪代码
DECLARE chunk_size INT DEFAULT 10000;
DECLARE max_id INT;
DECLARE min_id INT DEFAULT 0;
SELECT MAX(id) INTO max_id FROM user;
WHILE min_id <= max_id DO
START TRANSACTION;
-- 迁移atype分段
INSERT INTO usertype (user_id, type, value)
SELECT id, 'atype', atype FROM user
WHERE id BETWEEN min_id AND min_id + chunk_size - 1
AND atype IS NOT NULL;
-- 迁移btype分段
INSERT INTO usertype (user_id, type, value)
SELECT id, 'btype', btype FROM user
WHERE id BETWEEN min_id AND min_id + chunk_size - 1
AND btype IS NOT NULL;
SET min_id = min_id + chunk_size;
COMMIT;
END WHILE;
```
### 二、数据一致性校验方法
1. **行列级校验**
```sql
-- 检查atype迁移一致性
SELECT
(SELECT COUNT(DISTINCT user_id) FROM usertype WHERE type='atype') AS migrated_count,
(SELECT COUNT(*) FROM user_backup WHERE atype IS NOT NULL) AS source_count;
-- 精确值对比(抽样10%用户)
SELECT
u.id,
u.atype AS orig_atype,
ut.value AS new_atype
FROM user_backup u
LEFT JOIN usertype ut ON u.id = ut.user_id AND ut.type='atype'
WHERE u.id % 10 = 0 -- 每10条抽样1条
AND NOT (u.atype <=> ut.value); -- 找出不一致项
```
2. **应用层双写验证**
在迁移期间短暂开启双写模式:
```java
// 伪代码:更新user表时同步写入新表
@Transactional
public void updateUser(User user) {
// 1. 更新user主表(保留旧字段)
userDao.update(user);
// 2. 写入usertype表
usertypeDao.upsert(user.getId(), "atype", user.getAtype());
usertypeDao.upsert(user.getId(), "btype", user.getBtype());
}
```
通过对比双写日志确保数据一致性[^2]。
### 三、零丢失保障技术矩阵
| 风险类型 | 防御方案 | 实施要点 |
|----------------|-----------------------------------|----------------------------|
| 迁移中断 | 分段事务+断点记录 | 记录最后迁移的user_id |
| 数据篡改 | 迁移期间锁表 | `LOCK TABLES user WRITE` |
| 网络故障 | 应用层重试机制 | 指数退避重试策略 |
| 存储异常 | 预分配磁盘空间 | 监控usertype表空间使用率 |
| 唯一键冲突 | 迁移前清理脏数据 | 删除usertype表中测试数据 |
### 四、灾难恢复方案
1. **快速回滚路径**
```sql
-- 发现数据异常时执行回滚
START TRANSACTION;
-- 恢复旧字段
ALTER TABLE user
ADD COLUMN atype VARCHAR(255) AFTER id,
ADD COLUMN btype VARCHAR(255) AFTER atype;
-- 从备份恢复数据
UPDATE user u
JOIN user_backup b ON u.id = b.id
SET u.atype = b.atype,
u.btype = b.btype;
-- 清理新表数据
TRUNCATE TABLE usertype;
COMMIT;
```
### 五、扩展为新类型字段
新增ctype字段只需:
1. `INSERT INTO usertype (user_id, type, value) SELECT id, 'ctype', ctype FROM user;`
2. 无需修改表结构,体现新架构优势[^3]。
---
§§相关问题§§
1. 如何在线实现字段拆分不影响用户读写?
2. 分库分表环境下如何进行字段拆分?
3. 如何验证迁移后应用功能的正确性?
4. 新架构下查询性能下降该如何优化?
[^1]: 事务保障原子性操作
[^2]: 双写模式确保数据同步
[^3]: 扩展性是新架构的核心优势
</think>
### 保障数据零丢失的完整解决方案
#### 一、核心保障机制:原子事务操作
```sql
START TRANSACTION; -- 开启原子事务
-- 步骤1:创建临时备份表
CREATE TABLE user_backup AS SELECT * FROM user;
-- 步骤2:迁移atype字段
INSERT INTO usertype (user_id, type, value)
SELECT id, 'atype', atype FROM user
WHERE atype IS NOT NULL; -- 排除空值[^1]
-- 步骤3:迁移btype字段
INSERT INTO usertype (user_id, type, value)
SELECT id, 'btype', btype FROM user
WHERE btype IS NOT NULL; -- 排除空值
-- 步骤4:数据一致性验证
SET @expected = (SELECT COUNT(*) FROM user WHERE atype IS NOT NULL OR btype IS NOT NULL);
SET @actual = (SELECT COUNT(*) FROM usertype);
-- 步骤5:验证通过后删除旧字段(否则回滚)
IF @expected = @actual THEN
ALTER TABLE user
DROP COLUMN atype,
DROP COLUMN btype;
COMMIT;
ELSE
ROLLBACK;
RAISE EXCEPTION '数据不一致:预期 % 条,实际迁移 % 条', @expected, @actual;
END IF;
```
#### 二、双重验证策略(事务外补充)
1. **行级哈希校验**
```sql
-- 生成源数据哈希指纹
SELECT MD5(GROUP_CONCAT(
CONCAT_WS('|', id, COALESCE(atype,'NULL'), COALESCE(btype,'NULL'))
)) AS source_hash FROM user;
-- 生成目标数据哈希指纹
SELECT MD5(GROUP_CONCAT(
CONCAT_WS('|', user_id, type, value)
)) AS target_hash FROM usertype;
```
2. **精确值对比**
```sql
SELECT
u.id,
u.atype AS orig_atype,
MAX(CASE WHEN ut.type='atype' THEN ut.value END) AS new_atype,
u.btype AS orig_btype,
MAX(CASE WHEN ut.type='btype' THEN ut.value END) AS new_btype
FROM user u
LEFT JOIN usertype ut ON u.id = ut.user_id
GROUP BY u.id
HAVING orig_atype <> new_atype OR orig_btype <> new_btype; -- 返回差异项
```
#### 三、高可用保障措施
1. **断点续传机制**
```python
# 伪代码:分段迁移(处理亿级数据)
for chunk in read_user_chunks(size=10000): # 每次处理1万条
with transaction.atomic(): # 每个区块独立事务
migrate_atype(chunk)
migrate_btype(chunk)
write_checkpoint(chunk.max_id) # 记录断点
```
2. **实时双写容灾**
```java
// Java伪代码:迁移期间的临时双写
public void updateUser(User user) {
// 同时写入新旧结构
userDao.update(user); // 更新原表
usertypeDao.upsert(user.id, "atype", user.atype); // 更新新表
usertypeDao.upsert(user.id, "btype", user.btype);
// 异步校验
Validator.queueVerify(user.id);
}
```
#### 四、监控与应急方案
1. **实时监控看板**
```
数据迁移监控仪表板
---------------------------------
总记录数 | ✅ 匹配 (2,843,192/2,843,192)
差异记录 | 🔴 报警 (12) -> 查看详情
迁移进度 | ██████ 98.7%
吞吐量 | 24,500 条/秒
---------------------------------
```
2. **一键回滚命令**
```sql
-- 紧急回滚脚本(10秒内完成)
BEGIN;
TRUNCATE usertype; -- 清空新表
ALTER TABLE user
ADD COLUMN atype VARCHAR(255) AFTER id,
ADD COLUMN btype VARCHAR(255) AFTER atype;
UPDATE user u
JOIN user_backup b ON u.id = b.id
SET u.atype = b.atype, u.btype = b.btype;
COMMIT;
```
#### 五、最佳实践总结
1. **事前检查清单**
- [√] 禁用全库备份作业
- [√] 验证`user_backup`表空间充足
- [√] 配置binlog保留72小时
- [√] 准备回滚脚本并预演
2. **黄金法则**
- 始终在**低峰期**执行 ($t < T_{low\_peak}$)
- 迁移前**强制内存刷新**:`FLUSH TABLES WITH READ LOCK;`
- 使用**CRC32校验**替代简单计数:
```sql
SELECT SUM(CRC32(CONCAT_WS(',',atype,btype)))
FROM user_backup;
```
---




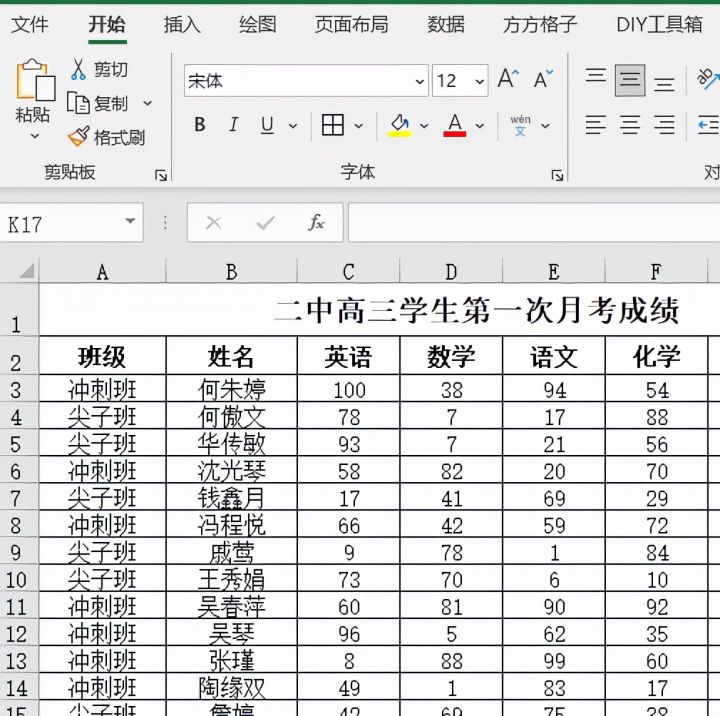
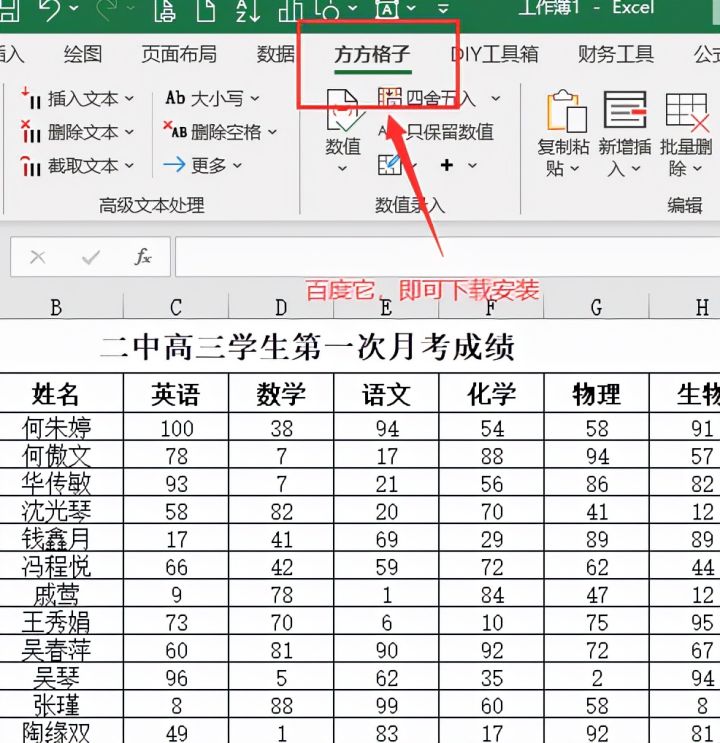
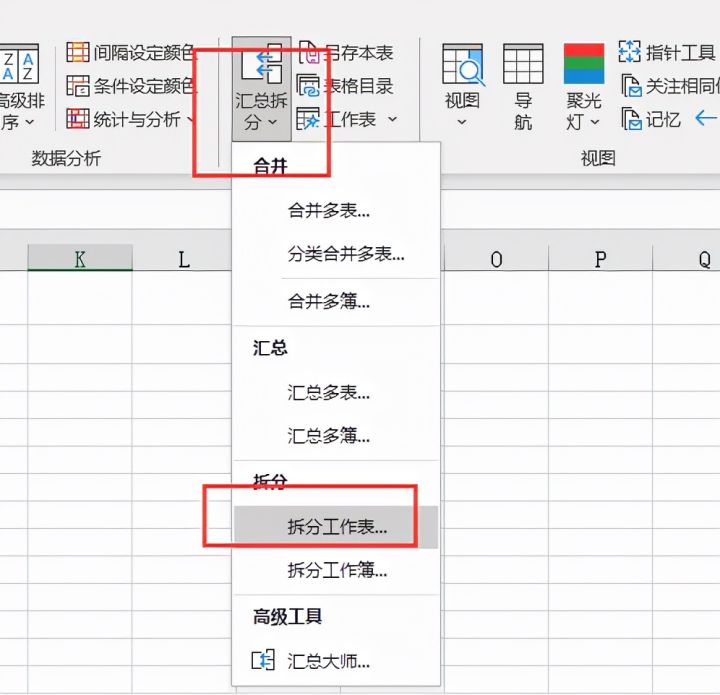
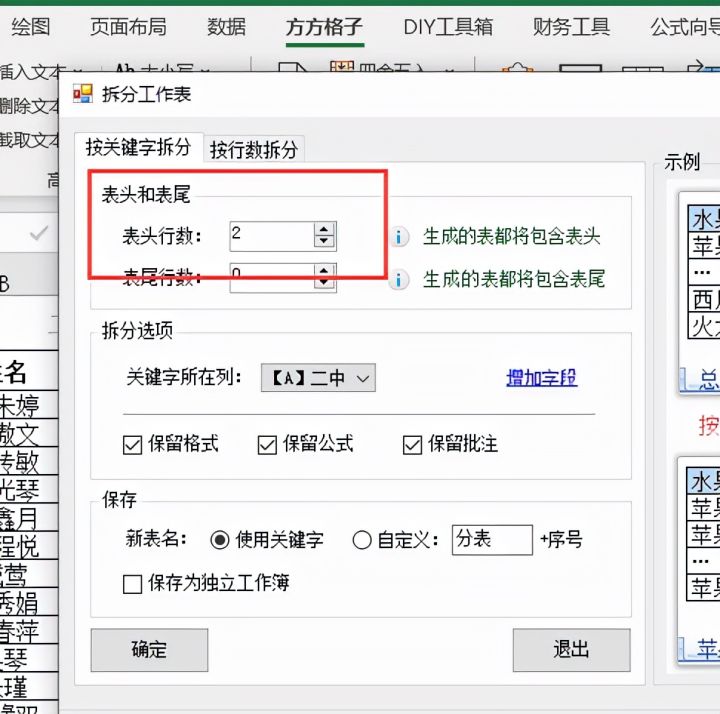
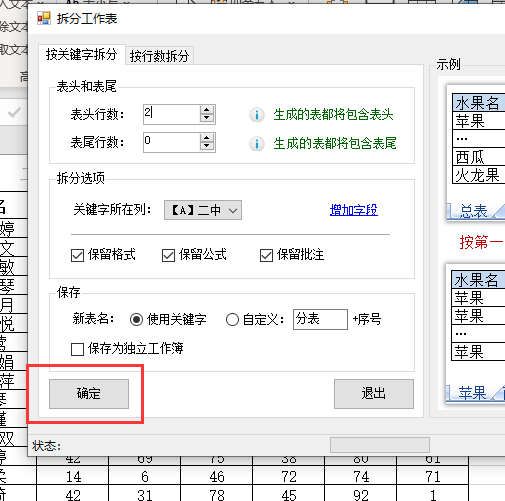
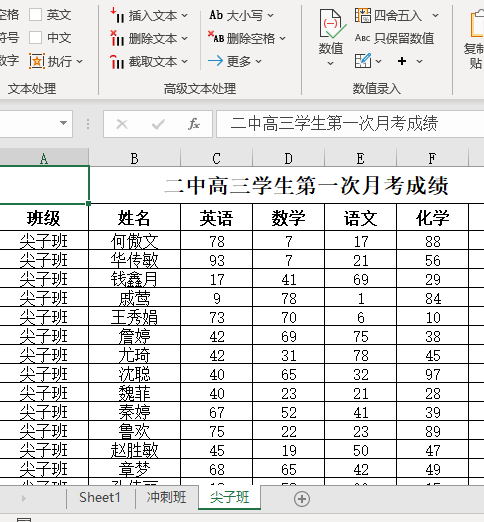
 本文介绍了如何使用特定软件工具快速拆分Excel表格,以班级为单位进行操作。步骤包括点击相应选项,选择【拆分工作表】功能,设定表头行数,最后确认完成。通过这种方法,可以高效地整理和管理大量学生数据。
本文介绍了如何使用特定软件工具快速拆分Excel表格,以班级为单位进行操作。步骤包括点击相应选项,选择【拆分工作表】功能,设定表头行数,最后确认完成。通过这种方法,可以高效地整理和管理大量学生数据。
 2645
2645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























