




感知机是1957年,由Rosenblatt提出,是神经网络和支持向量机的基础。感知机是二分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别,取+1和-1二值。感知机对应于输入空间中将实例划分为正负两类的分离超平面,属于判别类型。
假设训练数据集是线性可分的,感知机学习的目标是求得一个能够将训练数据集正实例点和负实例点完全正确分开的分离超平面。如果是非线性可分的数据,则最后无法获得超平面。
感知机模型
感知机的输入特征向量x为n维向量,输出y∈{+1,-1}.
感知机从输入空间到输出空间的模型如下:
f(x)=sign(w⋅x+b)f(x)=sign(w \cdot {x}+b)f(x)=sign(w⋅x+b)
其中w∈Rnw∈R^nw∈Rn叫做权值,b∈Rb∈Rb∈R叫做偏置。
sign是符号函数,即:
sign(x)={
−1x<01x≥0sign(x)= \begin{cases} -1& {x<0}\\ 1& {x\geq 0} \end{cases}sign(x)={
−11x<0x≥0
感知机有如下几何解释:
线性方程w·x+b=0 对应于特征空间RnR^nRn中的一个超平面S,其中w是超平面的法向量,b是超平面的截距。这个超平面将特征空间划分为两个部分。位于两部分的点分别被分为正、负两类。如下图所示:
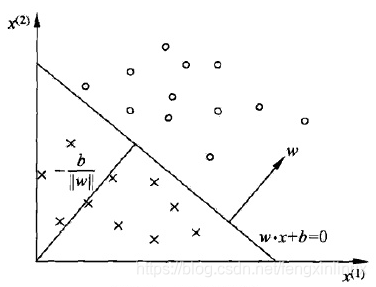
感知机的学习目的就是确定最佳的w和b
数据集的线性可分性
给定一个训练集T=(x1,y1),(x2,y2),...,(xN,yN)T={(x_1,y_1),(x_2,y_2),...,(x_N,y_N)}T=(x1,y1),(x2,y2),...,(xN,yN),如果存在某个超平面S:w·x+b=0能够将数据集的正实例点和负实例点完全正确地划分到超平面的两侧,则称为该数据集T线性可分,否则称为线性不可分。
感知机学习策略
损失函数
感知机的损失函数采用误分类点到超平面S的总距离。
首先,写出输入空间中任意一点x0x_0x0到超平面S的距离:∣w⋅x0+b∣∣∣w∣∣\frac{|w\cdot {x_0}+b|}{||w||}∣∣w∣∣∣w⋅x0+b∣
其中,||w||是w的L2L_2L2范数,L2L_2L2范数定义为向量所有元素的平方和的开平方。
对于误分类的数据(xi,yix_i,y_ixi,yi)来说,−yi(w⋅xi+b)>0-y_i(w\cdot {x_i}+b)>0−yi(w⋅xi+b)>0 成立
因为当w⋅xi+b>0w\cdot {x_i}+b>0w⋅xi+b>0时,yi=−1y_i=-1y
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6199
6199




 到【灌水乐园】发言
到【灌水乐园】发言







