




目录
一、理论
1、基础知识
- 决策树有ID3、C4.5、CART(分类和回归树Classfier and regression tree):ID3使用信息增益最大的特征作为树生长的依据;C4.5是对ID3的改进,用信息增益率最大的特征作为树生长的依据;CART利用二分类方法,根据基尼指数最大的特征作为树生长的依据。参考
- 特点:决策树算法每次生成分枝时只考虑一个特征,决策树的生成是局部最优,剪枝是全局最优。ID3倾向于选择分类较多的特征。对训练集,复杂度是 O ( n ∗ m ∗ l o g m ) O(n*m*logm) O(n∗m∗logm);一个预测样本,复杂度是 O ( l o g m ) O(logm) O(logm),m是特征个数,n是样本个数。
- 优缺点:
优点:1)简单直观,生成的决策树很直观。
2)基本不需要预处理,不需要提前归一化,处理缺失值。
3)使用决策树预测的代价是O(log2m), m为样本数。
4)可以处理多维度输出的分类问题。
5)相比于神经网络之类的黑盒分类模型,决策树在逻辑上可以得到很好的解释
6)可以交叉验证的剪枝来选择模型,从而提高泛化能力。
7) 对于异常点的容错能力好,健壮性高。
缺点:1)决策树算法非常容易过拟合,导致泛化能力不强。可以通过设置节点最少样本数量和限制决策树深度来改进。
2)决策树会因为样本的改动导致树结构的剧烈改变。这个可以通过集成学习之类的方法解决。
3)寻找最优的决策树是一个NP难的问题,我们一般是通过启发式方法,容易陷入局部最优。可以通过集成学习之类的方法来改善。
4)有些比较复杂的关系,决策树很难学习,比如异或。这个就没有办法了,一般这种关系可以换神经网络分类方法来解决。
5)如果某些特征的样本比例过大,生成决策树容易偏向于这些特征。这个可以通过调节样本权重来改善。 - 拆分准则:
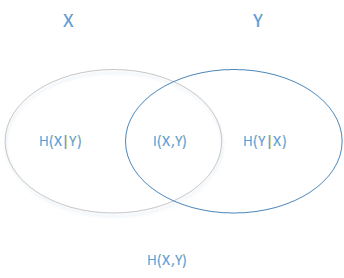
熵用来衡量随机变量的不确定性,值越大,不确定性越强。熵的值与随机变量取值无关,只与其分布有关:
H ( X ) = − ∑ i = 1 n p i l o g 2 p i H(X) = -\sum\limits_{i=1}^{n}p_i log_2p_i H(X)=−i=1∑npilog2pi n是标签取值的个数; p i p_i pi是X取值为x时的概率
来源: P ( X , Y ) = P ( X ) P ( Y ) P(X,Y)=P(X)P(Y) P(X,Y)=P(X)P(Y),为使其变为可加形式,取对数变为 l o g p logp logp;负号是为使函数变为递减函数(对数是递增函数)。概率是衡量可能性的,同信息一致性是相反的,因此乘以-logp。
条件熵是在已知变量Y的条件下X的不确定性:
H
(
X
∣
Y
)
=
−
∑
i
=
1
n
p
(
x
i
,
y
i
)
l
o
g
2
p
(
x
i
∣
y
i
)
=
∑
j
=
1
n
p
(
y
j
)
H
(
X
∣
y
j
)
H(X|Y) = -\sum\limits_{i=1}^{n}p(x_i,y_i)log_2p(x_i|y_i) = \sum\limits_{j=1}^{n}p(y_j)H(X|y_j)
H(X∣Y)=−i=1∑np(xi,yi)log2p(xi∣yi)=j=1∑np(yj)H(X∣yj)
信息增益(互信息,entropy) 衡量变量X在知道变量Y后对未知性的变化,值越大,未知性减少越多:
g
(
X
,
Y
)
=
H
(
X
)
−
H
(
X
∣
Y
)
g(X,Y)=H(X)-H(X|Y)
g(X,Y)=H(X)−H(X∣Y)。Y的值越多,g(Y,X)可能更大
信息增益比:由于信息增益的大小是相对于训练集而言的,没有绝对意义;当经验熵较大时,信息增益值反而偏大,反之会偏小,此时可以使用信息增益比:
g
r
(
D
,
A
)
=
g
(
D
,
A
)
H
A
(
D
)
g_r(D,A)=\frac{g(D,A)}{H_A(D)}
gr(D,A)=HA(D)g(D,A),其中
H
A
(
D
)
=
−
∑
i
=
1
n
p
i
l
o
g
2
p
i
H_A(D)=-\sum\limits_{i=1}^{n}p_ilog_2p_i
HA(D)=−i=1∑npilog2pi,n是特征A的取值个数,
p
i
p_i
pi是A各取值的概率。
H
A
(
D
)
H_A(D)
HA(D)可以校正信息增益容易偏向取值较多的特征的问题(除以了特征自身的熵(不是目标值的熵))。
信息增益准则对可取值数目较多的属性有所偏好;信息增益比对可选取值数目较少的属性有所偏好。
基尼指数:表示变量的不纯度,值越小不纯度越低:
G
i
n
i
(
p
)
=
∑
k
=
1
K
p
k
(
1
−
p
k
)
=
1
−
∑
k
=
1
K
p
k
2
Gini(p) = \sum\limits_{k=1}^{K}p_k(1-p_k) = 1- \sum\limits_{k=1}^{K}p_k^2
Gini(p)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2,其中k为标签类别数,
p
k
p_k
pk为第k个类别的概率(发生的概率)。基尼指数是熵的近似,通过泰勒展开式
f
(
x
)
=
−
l
o
g
2
x
f(x)=-log_2x
f(x)=−log2x在
x
=
1
x=1
x=1处展开,忽略无穷小可得
f
(
x
)
≈
1
−
x
f(x)\approx 1-x
f(x)≈1−x,从而有
H
(
X
)
=
−
∑
p
k
l
o
g
2
p
k
≈
∑
p
k
(
1
−
p
k
)
H(X)=-\sum p_klog_2p_k\approx \sum p_k(1-p_k)
H(X)=−∑pklog2pk≈∑pk(1−pk)。
条件基尼指数:已知变量A时数据集的基尼系数:
G
i
n
i
(
D
,
A
)
=
∑
i
=
1
m
∣
D
i
∣
∣
D
∣
G
i
n
i
(
D
i
)
Gini(D,A) = \sum\limits_{i=1}^{m}\frac{|D_i|}{|D|}Gini(D_i)
Gini(D,A)=i=1∑m∣D∣∣Di∣Gini(Di),m是特征A的取值个数,
G
i
n
i
(
D
i
)
Gini(D_i)
Gini(Di)是特征A取i值时对应的数据集的基尼指数。用基尼指数做分类准则时,计算过程同信息增益。
损失函数:
C
(
T
)
=
∑
l
e
a
f
N
t
⋅
H
(
t
)
C(T)=\sum_{leaf}N_t·H(t)
C(T)=∑leafNt⋅H(t),
H
(
t
)
H(t)
H(t)是叶子节点的熵,以叶子节点样本量
N
t
N_t
Nt为权重。
特征重要性根据切分准则进行判定(建决策树过程中就已对重要性进行排序)
ID3和C4.5对分类决策树都是将连续变量进行离散化,从而根据划分准则确定划分变量和划分点。
5. 投票(补充):一票否决;少数服从多数;阈值表决;贝叶斯投票。示例:多个观众对几部电影投票(可以不投票),但由于观众观影量有限,对部分电影可能未看过,从而无得分,可以用如下方法计算得分:
W
R
i
=
v
v
+
m
R
i
+
m
v
+
m
C
WR_i=\frac{v}{v+m}R_i+\frac{m}{v+m}C
WRi=v+mvRi+v+mmC,其中
R
i
R_i
Ri是电影
i
i
i的用户投票的平均得分,C是所有电影的平均得分(先验得分,作为无人评价的下限),
v
i
v_i
vi是该电影投票人数,
m
m
m是排名前n的电影的最低投票数(视为先验投票数)。
决策树容易过拟合,最重要的就是树的深度max_depth(5、10等逐渐增加)、父节点样本量min_samples_split、子节点样本量min_samples_leaf。可以用测试集通过做决策树某参数变化与对应得分间的关系图来确定合适的参数值。
2、ID3
缺点:只适用于离散特征,不能用于连续特征。使用信息增益值做划分准则,会倾向于选择值较多的特征。没有考虑缺失值。只考虑树的生成,没有考虑剪枝,容易过拟合。
计算单个特征的信息增益:
训练集为D,样本量为|D|。设标签有K个类
C
k
C_k
Ck,k=1,2,…,K,
∣
C
k
∣
|C_k|
∣Ck∣是属于类
C
k
C_k
Ck的样本个数,
∑
i
=
1
K
∣
C
k
∣
=
∣
D
∣
\sum\limits_{i=1}^{K}|C_k|=|D|
i=1∑K∣Ck∣=∣D∣。设特征A有n个不同的取值
a
1
,
a
2
,
…
,
a
n
{a_1,a_2,…,a_n}
a1,a2,…,an,根据特征A的取值将D划分为n个子集
D
1
,
D
2
,
…
,
D
n
D_1,D_2,…,D_n
D1,D2,…,Dn,
∣
D
i
∣
|D_i|
∣Di∣为
D
i
D_i
Di的样本个数,
∑
i
=
1
n
∣
D
i
∣
=
∣
D
∣
\sum\limits_{i=1}^{n}|D_i|=|D|
i=1∑n∣Di∣=∣D∣ 。记子集
D
i
D_i
Di中属于类
C
k
C_k
Ck的样本的集合为
D
i
k
D_ik
Dik,即
D
i
k
=
D
i
⋂
C
k
D_ik=D_i⋂C_k
Dik=Di⋂Ck,
∣
D
i
k
∣
|D_ik|
∣Dik∣为
D
i
k
D_ik
Dik的样本个数:
1)计算数据集D的经验熵:
H
(
D
)
=
−
∑
k
=
1
K
∣
C
k
∣
∣
D
∣
∗
l
o
g
2
∣
C
k
∣
∣
D
∣
H(D)=-\sum\limits_{k=1}^{K}\frac{|C_k|}{|D|}*log_2\frac{|C_k|}{|D|}
H(D)=−k=1∑K∣D∣∣Ck∣∗log2∣D∣∣Ck∣
2)计算特征A对数据集D的经验条件熵:
H
(
D
∣
A
)
=
∑
i
=
1
n
∣
D
i
∣
∣
D
∣
∗
H
i
(
D
)
=
∑
i
=
1
n
∣
D
i
∣
∣
D
∣
∗
(
−
∑
k
=
1
K
∣
D
i
k
∣
∣
D
i
∣
l
o
g
2
∣
D
i
k
∣
∣
D
i
∣
)
H(D|A)=\sum\limits_{i=1}^{n}\frac{|D_i|}{|D|}*H_i(D)=\sum\limits_{i=1}^{n}\frac{|D_i|}{|D|}*(-\sum\limits_{k=1}^{K}\frac{|D_ik|}{|D_i|}log_2\frac{|D_ik|}{|D_i|})
H(D∣A)=i=1∑n∣D∣∣Di∣∗Hi(D)=i=1∑n∣D∣∣Di∣∗(−k=1∑K∣Di∣∣Dik∣log2∣Di∣∣Dik∣)
3)计算信息增益:
g
(
D
,
A
)
=
H
(
D
)
−
H
(
D
∣
A
)
g(D,A)=H(D)-H(D|A)
g(D,A)=H(D)−H(D∣A)
对所有特征分别按上述步骤计算信息增益后,选择信息增益最大的特征,根据该特征拥有的值向下分别生成子节点。之后重复上述步骤,直到没有新节点生成或子节点中的所有样本的标签相同,此时视为叶节点。
可以设置信息增益的阈值ϵ,小于该阈值时就停止继续生成树;或叶节点最少样本量。
3、C4.5
C4.5是对ID3的改进,使用信息增益比来选择特征构建树。
优点:使用基尼指数作为划分准则;能够处理连续特征(离散化);可以对有缺失的数据进行处理(样本权重);考虑了剪枝。
缺点:可以用于连续特征,但不能用于连续标签;无法进行回归。参考
改进一、对连续特征,通过离散化来处理:
对连续特征A,从小到大排列为
a
1
,
a
2
,
.
.
.
,
a
m
a_1,a_2,...,a_m
a1,a2,...,am,依次取相邻两样本值的平均数进行m-1次划分划分点,其中第i个划分点
T
i
T_i
Ti表示为:
T
i
=
f
r
a
c
a
i
+
a
i
+
1
2
T_i=frac{a_i+a_i+1}{2}
Ti=fracai+ai+12。按照二元分类数据分别计算各划分点的信息增益比。选择信息增益比最大的点作为该连续特征的二元离散分类点来建树。如果当前节点为连续属性,则该属性后面还可以参与子节点的产生选择过程;而离散数据则不参与后续过程。
改进二、对缺失值的处理:分为两种类,1)在样本某些特征缺失的情况下属性的选择划分;2)选定了划分属性,对于在该属性上缺失特征的样本的处理。
1)对每个样本设置一个权重(初始可以都为1)。对有缺失值的特征A,然后将数据分成两部分:一部分是有特征值A的数据
D
1
D_1
D1,另一部分是没有特征A的数据
D
2
D_2
D2。对于A特征没有缺失值的
D
1
D_1
D1,计算该数据集的信息增益比,最后乘以该数据集样本量占总数据集的比例$\frac{|D_1|}{D}(即特征A无缺失的比重),以此作为特征A的信息增益比:
g
(
D
,
a
)
=
ρ
∗
g
(
D
~
,
A
)
g(D,a)=\rho*g(\tilde{D},A)
g(D,a)=ρ∗g(D~,A),其中
ρ
\rho
ρ是属性A中无缺失值样本所占比例,
D
~
\tilde{D}
D~是属性A中无缺失值的样本集。
2)将缺失特征的样本同时划分入所有的子节点,不过将该样本的权重按各个子节点样本的数量比例来分配。比如特征A有3个特征值A1、A2、A3,个数分别为2,3,4,另有以样本a缺少特征A。先将个样本权重设置为1。选定以特征A进行节点生成时,先将无缺失值的样本分别划入各节点(2、3、4)。再将a同时划分入A1、A2、A3,并将样本a的权重分别设置为2/9、3/9、4/9;无缺失值的样本划入子节点时权重仍为1。从而之后某一子节点的特征选择公式变为:
g
(
D
,
a
)
=
ρ
∗
g
(
D
~
,
A
)
=
ρ
∗
(
H
(
D
~
)
−
∑
i
=
1
m
γ
i
~
)
H
(
D
~
i
)
g(D,a)=\rho*g(\tilde{D},A)=\rho*(H(\tilde{D})-\sum\limits_{i=1}^{m}\tilde{\gamma_i})H(\tilde{D}^i)
g(D,a)=ρ∗g(D~,A)=ρ∗(H(D~)−i=1∑mγi~)H(D~i),其中
H
(
D
~
=
−
∑
k
=
1
∣
Y
∣
p
k
~
l
o
g
2
p
k
~
H(\tilde{D}=-\sum_{k=1}^{|Y|}\tilde{p_k}log_2{\tilde{p_k}}
H(D~=−∑k=1∣Y∣pk~log2pk~,
ρ
=
该
子
节
点
中
无
缺
失
样
本
权
重
和
该
子
节
点
样
本
权
重
和
\rho=\frac{该子节点中无缺失样本权重和}{该子节点样本权重和}
ρ=该子节点样本权重和该子节点中无缺失样本权重和,
p
k
~
\tilde{p_k}
pk~是该子节点中标签为k的无缺失值权重和占该子节点中无缺失值权重和的比例。
γ
i
~
\tilde{\gamma_i}
γi~是该子节点中无缺失值样本中属性为A值为i的权重和占该子节点中无缺失值权重和的比例。
4、CART(分类和回归树Classfier and regression tree)
参考
特点:使用基尼系数选择特征,计算简单。将数据全部转化为二分类问题进行处理。需要生成整棵树后再进行剪枝。
对连续特征A:从小到大排列为
a
1
,
a
2
,
.
.
.
,
a
m
a_1,a_2,...,a_m
a1,a2,...,am,依次取相邻两样本值的平均数进行m-1次划分划分点,其中第i个划分点
T
i
T_i
Ti表示为:
T
i
=
a
i
+
a
i
+
1
2
T_i=\frac{a_i+a_i+1}{2}
Ti=2ai+ai+1。按照二元分类数据分别计算各划分点的均方误差,选择均方误差最小的点作为该连续特征的二元离散分类点来建树(各分支的各样本与对应分支的均值的差的平方和:
m
i
n
⏟
A
,
s
[
m
i
n
⏟
c
1
∑
x
i
∈
D
1
(
A
,
s
)
(
y
i
−
c
1
)
2
+
m
i
n
⏟
c
2
∑
x
i
∈
D
2
(
A
,
s
)
(
y
i
−
c
2
)
2
]
\underbrace{min}_{A,s}\Bigg[\underbrace{min}_{c_1}\sum\limits_{x_i \in D_1(A,s)}(y_i - c_1)^2 + \underbrace{min}_{c_2}\sum\limits_{x_i \in D_2(A,s)}(y_i - c_2)^2\Bigg]
A,s
min[c1
minxi∈D1(A,s)∑(yi−c1)2+c2
minxi∈D2(A,s)∑(yi−c2)2])。如果当前节点为连续属性,则该属性后面还可以参与子节点的产生选择过程;而离散数据则不参与后续过程。
对离散特征A:按照二分类方式将A的各值作为切分点,依次计算出不同值的基尼指数,选择基尼指数最小的点作为该连续特征的二元离散分类点来建树。
分类树具体过程:
算法输入是训练集D,基尼系数的阈值,样本个数阈值。输出是决策树T。从根节点开始,用训练集递归的建立CART树。
- 对于当前节点的数据集为D,如果样本个数小于阈值或者没有特征,则返回决策子树,当前节点停止递归。
- 计算样本集D的基尼系数,如果基尼系数小于阈值,则返回决策树子树,当前节点停止递归。
- 计算当前节点现有的各个特征的各个特征值对数据集D的基尼系数,对于离散值和连续值的处理方法和基尼系数的计算见第二节。缺失值的处理方法和上篇的C4.5算法里描述的相同。
- 在计算出来的各个特征的各个特征值对数据集D的基尼系数中,选择基尼系数最小的特征A和对应的特征值a。根据这个最优特征和最优特征值,把数据集划分成两部分D1和D2,同时建立当前节点的左右节点,做节点的数据集D为D1,右节点的数据集D为D2.
- 对左右的子节点递归的调用1-4步,生成决策树。
对于生成的决策树做预测的时候,假如测试集里的样本A落到了某个叶子节点,而节点里有多个训练样本。则对于A的类别预测采用的是这个叶子节点里概率最大的类别。
回归树具体过程:
CART回归树和CART分类树的建立算法大部分是类似的,以下仅说明CART回归树和CART分类树的不同之处:
回归树的样本输出是连续值。
1)选择特征的依据不同,不在使用基尼指数,而是用最小均方误差和:
m i n ⏟ A , s [ m i n ⏟ c 1 ∑ x i ∈ D 1 ( A , s ) ( y i − a v g ( c 1 ) ) 2 + m i n ⏟ c 2 ∑ x i ∈ D 2 ( A , s ) ( y i − a v g ( c 2 ) ) 2 ] \underbrace{min}_{A,s}\Bigg[\underbrace{min}_{c_1}\sum\limits_{x_i \in D_1(A,s)}(y_i - avg(c_1))^2 + \underbrace{min}_{c_2}\sum\limits_{x_i \in D_2(A,s)}(y_i - avg(c_2))^2\Bigg] A,s min[c1 minxi∈D1(A,s)∑(yi−avg(c1))2+c2 minxi∈D2(A,s)∑(yi−avg(c2))2]
c 1 、 c 2 c_1、c_2 c1、c2分别是由切分点生成的两个节点中的样本,$ avg(c_1)、 avg(c_2)$是两节点中样本标签的均值。
2)决策树建立后做预测时使用最终叶节点的均值或中位数来预测结果。
5、剪枝
后剪枝时考虑的损失函数:
C
α
(
T
)
=
∑
t
=
1
∣
T
∣
N
t
H
t
(
T
)
+
α
∣
T
∣
=
C
(
T
)
+
α
∣
T
t
∣
C_{\alpha}(T) =\sum\limits_{t=1}^{|T|}N_tH_t(T)+\alpha|T|=C(T) + \alpha |T_t|
Cα(T)=t=1∑∣T∣NtHt(T)+α∣T∣=C(T)+α∣Tt∣,其中
∣
T
∣
|T|
∣T∣是树T的叶节点个数,t是树T的叶节点,该叶节点有
N
t
N_t
Nt个样本点,其中k类的样本点有
N
t
k
N_tk
Ntk个,
H
t
(
T
)
H_t(T)
Ht(T)是叶节点t上的经验熵,
α
\alpha
α是对树节点大小的惩罚项。
C
(
T
)
C(T)
C(T)表示生成整个决策树时的损失函数,
C
(
T
)
=
∑
l
e
a
f
N
t
⋅
H
(
t
)
C(T)=\sum_{leaf}N_t·H(t)
C(T)=∑leafNt⋅H(t),
H
(
t
)
H(t)
H(t)是叶子节点的熵,以叶子节点样本量
N
t
N_t
Nt为权重。。
决策树的生成只考虑了提高信息增益、信息增益比或基尼指数来提高拟合度来学习局部模型;剪枝则通过优化损失函数(减小模型复杂度)来学习整体模型。
剪枝有预剪枝和后剪枝两种:预剪枝是通过设定准则的阈值来确定是否继续生成子节点;后剪枝是通过自底向上判断生成子节点是否能够带来决策树的泛化性能提升来确定剪枝。
CART采用的办法是后剪枝法:第一步是从原始决策树生成各种剪枝效果的决策树,第二步是用交叉验证来检验剪枝后的预测能力,选择泛化预测能力最好的剪枝后的数作为最终的CART树。分类树是用基尼系数度量衡量总体拟合程度,回归树是均方误差度量衡量总体拟合程度
| 算法 | 支持模型 | 树结构 | 特征选择 | 连续值处理 | 缺失值处理 | 剪枝 |
|---|---|---|---|---|---|---|
| ID3 | 分类 | 多叉树 | 信息增益 | 不支持 | 不支持 | 不支持 |
| C4.5 | 分类 | 多叉树 | 信息增益比 | 支持 | 支持 | 支持 |
| CART | 分类,回归 | 二叉树 | 基尼系数,均方差 | 支持 | 支持 | 支持 |
以上决策树都是基于单个特征作为分类决策的,可用OC1方法实现多变量决策树,实现多变量选择特征
6、多输出任务
多输出任务是对一个输入样本会输出多个目标值。以回归为例,对单输出任务是求解 θ \theta θ使得 X θ = Y X\theta=Y Xθ=Y,二多输出任务是求解 θ = ( θ 1 , θ 2 ) \theta=(\theta_1,\theta_2) θ=(θ1,θ2)使得 X ( θ 1 , θ 2 ) = ( Y 1 , Y 2 ) X(\theta_1,\theta_2)=(Y_1,Y_2) X(θ1,θ2)=(Y1,Y2)。对多输出任务,若各输出间相互独立,则多输出效果同多个单输出任务效果相似;但若各输出间有关联,则结果会不同与单输出任务的组合。
Python
from sklearn import tree
多用决策树的可视化,先限制决策树的深度,观察树的初步拟合情况后逐步拓展树。
scikitlearn中用的是CART树,且仅能用先剪枝法,特征数组用的是numpy的float32类型,不是这样的格式会自动copy后再运行。若样本矩阵是稀疏的,最好在拟合前调用csc_matrix稀疏化。可用feature_extraction.DictVector() 转换成数值型数组。
1、CART分类树
tree.DecisionTreeClassifier(criterion="gini", splitter="best", max_depth=None, min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None,
random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0,
class_weight=None, presort=False)
criterion指定选择特征的标准,"gini"基尼指数、"entropy"信息增益;信息熵因需要计算对数会比基尼系数缓慢一些;另外信息熵对不纯度更加敏感,决策树的生长会更加“精细”,因此对于高维数据或者噪音很多的数据,信息熵易过拟合,基尼系数会好一些。splitter指定特征划分点的方法,"best"在特征所有划分点中找出最优划分点、"random"随机的在排名靠前的特征中找到最优划分点(样本量大时用)。max_depth决策树的最大深度,为None(直到所有节点全部同类或小于min_samples_split个样本)或整数(大数据多样本时可设10-100,根节点为第0层),数据量少时可不用限制。min_samples_split内部节点再划分时的最少样本量,小于该值时不再生成子节点,整数(样本量)或小数(比例)。min_samples_leaf叶节点最少样本量,小于该值时将不再进行划分,整数(样本量)或小数(比例),如10W数据限制5。max_features划分时考虑的最大特征个数,整数、小数(特征数的比例)、None(所有特征)、“sqrt”(特征数的开方根个)、“log2”,特征数小于50时一般不用选择。random_state随机种子。max_leaf_nodes最大叶节点个数,防止过拟合,设置时会生成在最大叶节点数内的最优决策树(特征较多时可通过交叉验证设置)。min_impurity_decrease节点划分时的信息增益(不纯度)减少的最小值,若生成子节点时信息增益变化小于该值,则不再生成
N
t
N
∗
(
i
m
p
u
r
i
t
y
−
N
t
R
N
t
∗
r
i
g
h
t
i
m
p
u
r
i
t
y
−
N
t
L
N
t
∗
l
e
f
t
i
m
p
u
r
i
t
y
)
\frac{N_t}{N} * (impurity - \frac{N_tR}{N_t * right_impurity} - \frac{N_tL}{N_t * left_impurity})
NNt∗(impurity−Nt∗rightimpurityNtR−Nt∗leftimpurityNtL) 。class_weight以字典{label:weight}或字典的列表(顺序同y,每个元素都是一个二分类)表示的各分类的权重,“balanced”(用类别个数自动计算权重)或None表示等权重。min_weight_fraction_leaf叶节点最小样本权重和,小于该值时和兄弟节点一起被剪枝(适用于有较多缺失值或样本分布类别偏差较大时),0时不考虑权重。presort是否在拟合模型前对数据进行排序以便提高查找拆分点的速度(适用于小数据量)
属性:classes_分类结果数组,对多输出任务是数组列表,每个数组表示一个输出任务。n_classes_输出的类别数,对单输出是一个整数,对多输出是列表,每个元素是一个输出的类别数。
feature_importances_特征重要性数组,值越大越重要,通常是一个特征在多次分枝中产生的信息增益的综合。
tree_输出二叉树结构,通过属性表示对应的信息,每个属性都是数组,第i个元素表示对应节点i的信息(可以通过_tree.pxd获取详细信息);属性有node_count整棵树的所有节点量、capacity树的容量(>=node_count)、max_depth树的最大深度、children_left左节点数组、children_right右节点数组、feature各节点的切分特征、threshold各节点的切分点、value每个节点的预测值、impurity每个节点的不纯度(对应切分准则的值)、n_node_samples训练集到达每个节点的样本量、weighted_n_node_samples每个节点样本权重。
可以通过"参数名+下滑线"形式获得对应参数的设置,如: max_features_返回max_features参数的值。 n_features_返回测试集的特征数 n_outputs_返回测试集的输出任务数(是否多数出任务)
方法:fit(X, y, sample_weight=None, check_input=True, X_idx_sorted)X是训练集的特征(类型是np.float32,否则会被自动复制边转换为此),若X为稀疏矩阵,则应用csc_matrix()进行数据转换。y是训练集的标签,是整数或字符串。sample_weight样本全镇数组。check_input是否进行输入检测(最好不要动)。X_idx_sorted排序后的训练集数据索引矩阵(一般不用)。
predict(X, check_input=True)对测试集X进行预测(所进入到的叶节点的最多类)。
predict_proba(X)对测试集X计算其在对应叶节点中的占比,返回的类别顺序同属性classes_中的顺序。
predict_log_proba(X)对测试集X计算其在对应叶节点中的占比的对数值,返回的类别顺序同属性classes_中的顺序。
score(X, y, sample_weight=None)返回训练集X预测后的标签与其真实标签y间的准确率。sample_weight是样本权重。
apply(X, check_input=True)返回测试集X各样本的分类预测结果所对应的叶节点的索引
get_params() set_params()
2、CART回归树
tree.DecisionTreeRegressor(criterion='mse', splitter='best', max_depth=None, min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None,
random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, presort=False)
criterion指定选择特征的标准,"mse"均方误差(父节点和叶子节点间的均方误差差额作为标准,通过使用叶子节点的均值来最小化L2损失)、"mae"绝对平均误差(使用叶子节点的中值来最小化L1损失)、"friedman_mse"费尔德曼均方误差(针对潜在分支中的问题改进了均方误差)。splitter指定特征划分点的方法,"best"在特征所有划分点中找出最优划分点、"random"随机的在部分划分点中找到局部最优划分点(样本量大时用)。max_depth决策树的最大深度,为None(直到所有节点全部同类或小于min_samples_split个样本)或整数(大数据多样本时可设10-100),数据量少时可不用限制。min_samples_split内部节点再划分时的最少样本量,小于该值时不再生成子节点,整数(样本量)或小数(比例)。min_samples_leaf叶节点最少样本量,小于该值时和兄弟节点一起被剪枝,整数(样本量)或小数(比例)。min_weight_fraction_leaf叶节点最小样本权重和,小于该值时和兄弟节点一起被剪枝(适用于有较多缺失值或样本分布类别偏差较大时),0时不考虑权重。max_leaf_nodes最大叶节点个数,防止过拟合,设置时会生成在最大叶节点数内的最优决策树(特征较多时可通过交叉验证设置)。max_features划分时考虑的最大特征个数,整数、小数(特征数的比例)、None(所有特征)、“sqrt”(特征数的开方根个)、“log2”,特征数小于50时一般不用选择。random_state随机种子。min_impurity_decrease节点划分时的不纯度减小的最小值(对应切分准则的值),若生成子节点时不纯度变化小于该值,则不再生成(N_t / N * (impurity - N_t_R / N_t * right_impurity - N_t_L / N_t * left_impurity))。presort是否在拟合模型是先排序以提高查找拆分点的速度(适用于小数据量)
默认score()是
R
2
=
1
−
残
差
平
方
和
总
平
方
和
=
1
−
∑
(
f
i
−
y
i
)
2
∑
(
y
i
−
y
ˉ
)
2
R^2=1-\frac{残差平方和}{总平方和}=1-\frac{\sum(f_i-y_i)^2}{\sum(y_i-\bar y)^2}
R2=1−总平方和残差平方和=1−∑(yi−yˉ)2∑(fi−yi)2
3、通过DOT格式输出树
from sklearn import tree
tree.export_graphviz(decision_tree, out_file="tree.dot", max_depth=None, feature_names=None,
class_names=None, label='all', filled=False, leaves_parallel=False, impurity=True,
node_ids=False, proportion=False, rotate=False, rounded=False,
special_characters=False, precision=3)
生成GraphViz(下载下载msi文件,安装后将bin路径添加到环境变量里)可识别的树图数据,之后通过命令行生成PDF树图,或用pydotplus库来操作。若找不到graphviz,可添加os.environ[“PATH”] += os.pathsep + ‘C:/Program Files (x86)/Graphviz2.38/bin/’(路径自己定义)
decision_tree决策树拟合的模型。out_file输出图形文件名,也可以是输出句柄,为None时将结果以字符串返回。max_depth展现的最大树深度。feature_names以列表指定的各特征的别名(用来显示)。class_names以列表指定的各分类的别名(用于显示,升序),对多输出无效,为True时用符号表示各类,也可以用字典分别指定{0:“名称0”, 1:“名称1”}。label是否用标签显示各节点的不纯度,有"all"所有节点、"root"仅根节点、"none"不显示。filled是否用填充色区分各分类。leaves_parallel是否将叶节点并排在最下方。impurity是否显示各节点的不纯度。node_ids是否显示各节点的ID。proportion是否显示对应的比例。rotate是否将树表示成从左到右,而不是从上到下。rounded节点是否做圆角边框。special_characters是否忽略特殊字符以便适应PostScript。precision不纯度显示值的精确程度。
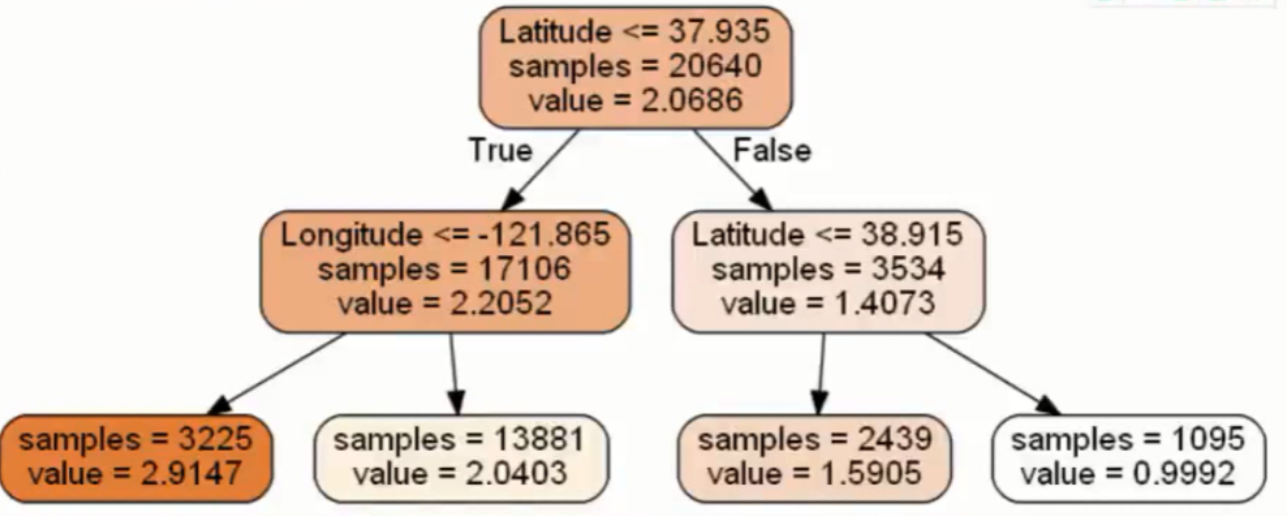
图形说明:value是各类别对应的样本数量,类别通过索引与class_保持一致。entroy是切分准则对应的值。samples是该节点处所包含的样本量。
生成图片:方法一:在命令行中用dot -Tpdf tree.dot -o tree.pdf将生成的.dot文件转为pdf。
方法二:用pydotplus将tree.export_graphviz()的返回对象转换为pdf:
import pydotplus
dot_data = tree.export_graphviz(clf, out_file=None) #对有中文的,找到graphviz的安装路径,将/fonts/fonts.conf文件中<!--Font directory list--后的><dir>C:\WINDOWS\Fonts</dir>设置为<div>~/.fonts</div>可打开输出文件,然后将开头处的node [shape=box]调整为node [shape=box fontname="'Microsoft YaHei'"]并保存utf-8文件即可。另有FangSong等字体
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("iris.pdf")
# graph.write_png("iris.png")
方法三:用IPython库生成在IPython的notebook中生成图片(内部调用Graphviz)(推荐使用)
from IPython.display import Image
dot_data = tree.export_graphviz(clf, out_file=None, feature_names=iris.feature_names,
class_names=iris.target_names, filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.get_nodes()[7].set_fillcolor('#FFF2DD')
Image(graph.create_png())
调参
决策树树深15就已经比较高了。
- 对高纬度数据,可以设置spliter=‘random’, random_seed=10
- 先确定max_depth,通常先从3开始。
- 将min_samples_leaf或min_samples_split与max_depth结合使用。过小时容易造成过拟合,通常从5开始
- 设置max_features和min_impurity_descrease。max_features的设置可能造成拟合不足。
- 对于非均衡样本,可以设置class_weight。此时可用min_weight_fraction_leaf基于权重剪枝。
- 绘制参数学习参数,结合得分选择最优参数
R语言
library(C50) #C5.0算法
查看精细调节模型的细节:?C5.0Control
创建分类器:
C5.0(x, y, trials=1, rules=FALSE, weights=NULL, control=C5.0Cnontrol(), costs=NULL, …)
C5.0(formula, data, weights, subset, na.action=na.pass, …)
x是特征值的数据框或矩阵。y是标记的因子向量。trials用于控制自适应算法法循环的次数(默认1)。costs是各种类型错误相对应的成本矩阵,行列数同标记的因子个数。
进行预测:
predict(object, newdata=NULL, trials=ogject$trials[“Actual”], type=“class”, na.action=na.pass, …)
type有"class"和"prob",用于表示预测是最可能的类别值或是原始预测概率。
输出结果解读:summary(object)
显示各分割下形成的分枝特征,其中的混淆矩阵是一交叉列联表,表示模型对训练数据错误分类的记录数,其列为被分类种类,行为真是种类。
回归树
适用对象:适用于具有许多特征或者特征和结果之间有许多复杂、非线性关系的任务。
优缺点:优点:拟合某些类型的数据可能比线性回归好得多;不要求用统计的知识来解释模型;不需要事先指定模型。
缺点:不像线性回归常用;需要大量训练样本;难以确定单个特征对结果的总体净影响;结果较回归更难解释。
思想:决策树用于数值预测有两类:1、回归树,回归树并没有使用线性回归的方法,而是基于到大也节点的案例的平均值作出预测。2、模型树,模型树和回归树以大致相同的方式生长,但是在每个叶节点会根据到达该节点的案例建立多元线性回归模型,根据叶结点的数目,一个模型树可能会建立几十甚至几百个这样的模型,结果难于理解但更加精确,有M5算法等。
从根节点开始,按照特征使用分而治之的策略对数据尽心瓜分,在一次分割后会导致结果最大化地均匀增长,通过统计量(方差、标准差或平均绝对偏差)来度量一致性,从而确定分割点(分类决策书中用熵)。
分割标准:1、标准偏差减少SDR=sd(T) - sum(|Ti| / |T| * sd(Ti) ) ,其中T是样本的一个特征,Ti是该特征根据分割点分割后的子集。SDR本质是从原始值的标准差减去分割后加权的标准差,从而得到标准差的减少量。选择SDR变化大的特征作为分类特征。若无法分割,将进行预测,预测值是一落入某一划分的案例均值作为预测的。回归树将到此为止,而模型树将多走一步,使用落入各分割的案例分别使用该特征进行回归,可用任一回归结果作为预测值。
2、平均绝对误差MAE=1/n * sum(|ei|)。MAE本质是误差绝对值的均值。
建立回归树:library(rpart) #使用递归划分,建立CART分类回归树
rpart(formula, data, weights, subset, na.action=na.rpart, method, model=FALSE, x=FALSE, y=TRUE, parms, control, cost, …)
formula是y~x形式。
进行预测:predict(object, test, type=“vector”)
type指定返回的预测值类型,"vector"预测数值型数据、"class"预测类别、"prob"预测类别的概率
建立模型树:library(RWeka) #M5’算法
M5P(formula, data, subset, na.action, control=Wika_control(), options=NULL)
formula是y~x形式。
进行预测:predict(object, test)
可视化决策树
library(rpart.plot)
rpart.plot(object, type=3, extra=“auto”, under=FALSE, fallen.leves=TRUE, digits=3, varlen=0, faclen=0, cex=NULL, tweak=1, snip=FALSE, box.palette=“auto”, shadow.col=0, …)
digits控制数字位数。fallen.leves强制叶节点与图的底部对齐。type和extra影响决策和节点被标记的方式。
规则学习:
决策树会给任务带来一组特定的偏差,而规则学习可以通过直接识别规则而避免偏差。
规则学习分类算法通常应用于以名义特征为主或全部是名义特征的问题。规则学习擅长识别偶发性事件,即使偶发事件只是因为特征之间非常特殊的相互作用才发生的。
规则学习使用了独立而至的探索方法,该过程包括确定训练数据中覆盖的一个案例子集的规则,然后再从剩余的数据中分理处该分区;随着规则的增加,更多的数据子集会被分离,直到整个数据集都被覆盖,不再有案例参与。对数据的利用是基于先到先得的思想。
library(RWeka)#基于Java的R能够使用的机器学习算法函数集合,具体参考http://www.cs.waikato.ac.nz/~m1/weka/
单规则算法(1R算法):
创建分类器:OneR(class~predictors, data, subset, na.action, control=Weka_control(), options=NULL)
class是data中需要预测的那一列。predictors是用来进行预测的特征。
进行预测:predict(object, test)
评估模型性能:summary(object)
混淆矩阵会给出评价对错的案例个数。
RIPPER规则学习算法:
创建分类器:JRip(class~predictors, data, subset, na.action, control=Weka_control(), options=NULL)
进行预测:predict(object, test)

















 646
646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









