




 本文介绍了使用requests、BeautifulSoup和urllib库下载网站图片到本地的步骤,包括设置开发环境、分析HTML节点、指定编码格式、获取图片链接和图片名,以及如何将图片保存到本地。
本文介绍了使用requests、BeautifulSoup和urllib库下载网站图片到本地的步骤,包括设置开发环境、分析HTML节点、指定编码格式、获取图片链接和图片名,以及如何将图片保存到本地。
这一篇主要写使用 requests + BeautifulSoup + urllib 下载图片保存到本地,下一篇写下载整站详情页的图片保存到本地(敬请期待)
爬取网络上的数据其实很简单,只要掌握基本逻辑就好了。
- 找到网站;
- 分析所需数据的 HTML 节点;
- 把数据下载到本地或者存储到数据库
那好,废话不多说,开始吧!
准备工作
- 开发环境:Windows,Pycharm,Request,BeautifulSoup,urllib
- 需要一定的 Python 爬虫、HTML 基础
开始动身
-
明确目标
本次要爬取的网站是 帅啊 网 (点开看一下,有惊喜哦~[坏笑].png)
我们需要把网站第一页所有 item 的图片下载到本地 -
制作爬虫
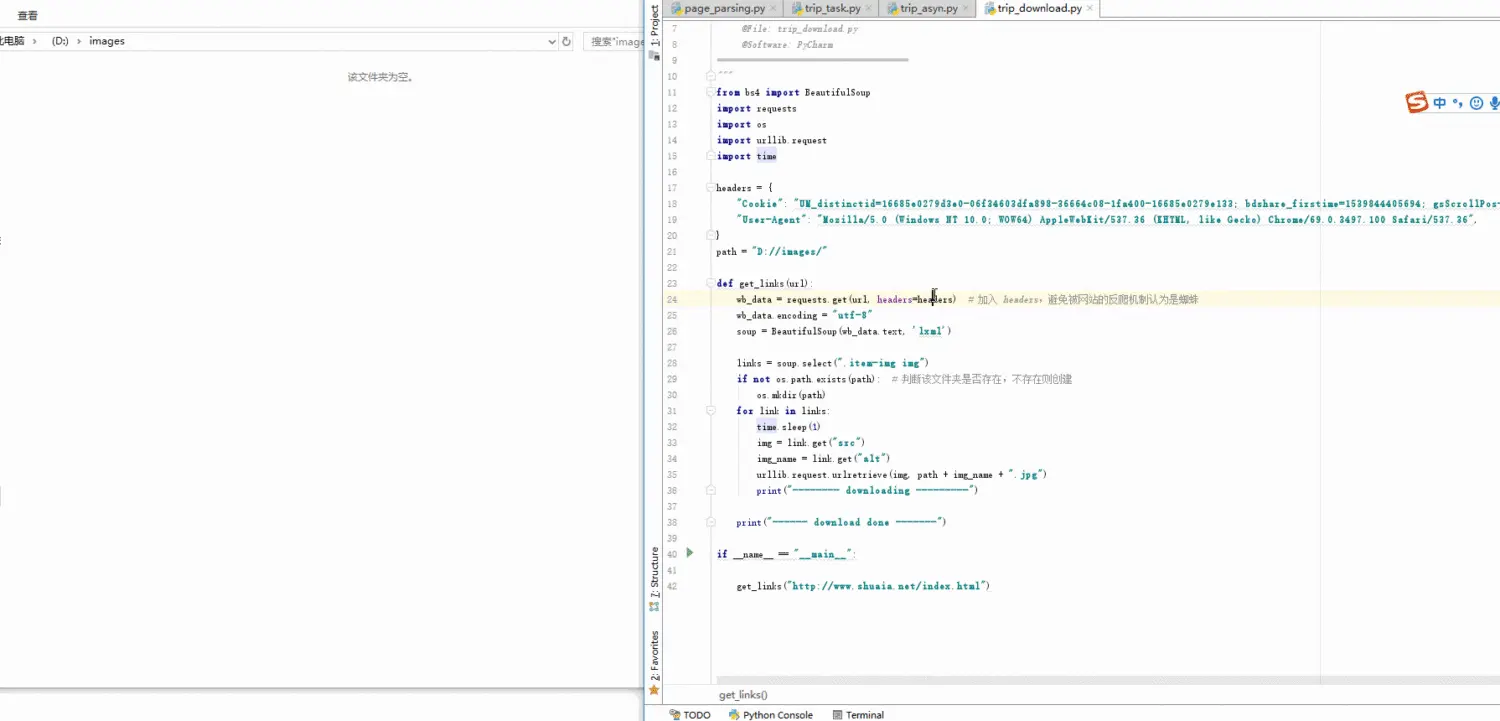
- 由于获取下来的 html 编码格式不对,所以要指定编码格式为 utf-8
- 获取页面中每个 item 的图片标签
- 循环获取标签的图片链接(src)和图片名(alt)
- 下载图片到本地
from bs4 import BeautifulSoup
import requests
import os
import urllib.request
import time
headers = {
"Cookie": "UM_distinctid=16685e0279d3e0-06f34603dfa898-36664c08-1fa400-16685e0279e133; bdshare_firstime=1539844405694; gsScrollPos-1702681410=; CNZZDATA1254092508=1744643453-1539842703-%7C1539929860; _d_id=0ba0365838c8f6569af46a1e638d05",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
}
path = "D://images/"
def get_links(url):
wb_data = requests.get(url, headers=headers) # 加入 headers,避免被网站的反爬机制认为是蜘蛛
wb_data.encoding = "utf-8"
soup = BeautifulSoup(wb_data.text, 'lxml')
links = soup.select(".item-img img")
if not os.path.exists(path): # 判断该文件夹是否存在,不存在则创建
os.mkdir(path)
for link in links:
time.sleep(1) # 暂停一秒,避免访问过快被反爬机制认为是蜘蛛
img = link.get("src")
img_name = link.get("alt")
urllib.request.urlretrieve(img, path + img_name + ".jpg")
print("-------- downloading ---------")
print("------ download done -------")
if __name__ == "__main__":
get_links("http://www.shuaia.net/index.html")
- 开始爬取

















 2103
2103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









