



一、前言
在数据获取与分析领域,网络爬虫技术扮演着重要角色。本文将带领大家使用Python实现一个功能完整的电影数据爬虫,通过Ajax请求、正则表达式和BeautifulSoup三种方式解析豆瓣电影Top250数据,并对数据进行可视化分析。
1.1什么是网络爬虫
网络爬虫的概念
网络爬虫(Web Crawler)又称网络蜘蛛、网络机器人,它是一种按照一定规则,自动浏览万维网的程序或脚本。通俗地讲,网络爬虫就是一个模拟真人浏览万维网行为的程序,这个程序可以代替真人自动请求万维网,并接收从万维网返回的数据。与真人浏览万维网相比,网络爬虫能够浏览的信息量更大,效率也更高。
网络爬虫的分类
网络爬虫历经几十年的发展,技术变得更加多样化,并结合不同的需求衍生出类型众多的网络爬虫。网络爬虫按照系统结构和实现技术大致可以分为4种类型,分别是通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫。

通用爬虫
通用网络爬虫(General Purpose Web Crawler)又称全网爬虫(Scalable Web Crawler),是指访问全互联网资源的网络爬虫。通用网络爬虫是“互联网时代”早期出现的传统网络爬虫,它是搜索引擎(如百度、谷歌、雅虎等)抓取系统的重要组成部分,主要用于将互联网中的网页下载到本地,形成一个互联网内容的镜像备份。
聚焦网络爬虫
聚焦网络爬虫(Focused Crawler)又称主题网络爬虫(Topical Crawler),是指有选择性地访问那些与预定主题相关网页的网络爬虫,它根据预先定义好的目标,有选择性地访问与目标主题相关的网页,获取所需要的数据。
与通用网络爬虫相比,聚焦网络爬虫只需要访问与预定主题相关的网页,这不仅减少了访问和保存的页面数量,而且提高了网页的更新速度,可见,聚焦网络爬虫在一定程度度节省了网络资源,能满足一些特定人群采集特定领域数据的需求。
增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler)是指对已下载的网页采取增量式更新,只抓取新产生或者已经发生变化的网页的网络爬虫。
增量式网络爬虫只会抓取新产生的或内容变化的网页,并不会重新抓取内容未发生变化的网页,这样可以有效地减少网页的下载量,减少访问时间和存储空间的耗费,但是增加了网页抓取算法的复杂度和实现难度。
深层网络爬虫
深层网络爬虫(Deep Web Crawler)是指抓取深层网页的网络爬虫,它要抓取的网页层次比较深,需要通过一定的附加策略才能够自动抓取,实现难度较大。
表层网页与深层网页
网页按存在方式可以分为表层网页(Surface Web)和深层网页(Deep Web),关于这两类网页的介绍如下。
● 表层网页是指传统搜索引擎可以索引的页面,主要以超链接可以到达的静态网页构成的网页。
● 深层网页是指大部分内容无法通过静态链接获取的,只能通过用户提交一些关键词才能获取的网页,如用户注册后内容才可见的网页。
1.2 网络爬虫的应用场景
随着互联网信息的"爆炸",网络爬虫渐渐为人们所熟知,并被应用到了社会生活的众多领域。作为一种自动采集网页数据的技术,很多人其实并不清楚网络爬虫具体能应用到什么场景。事实上,大多数依赖数据支撑的应用场景都离不开网络爬虫,包括搜索引擎、舆情分析与监测、聚合平台、出行类软件等。
搜索引擎
搜索引擎是通用网络爬虫最重要的应用场景之一,它会将网络爬虫作为最基础的部分——互联网信息的采集器,让网络爬虫自动到互联网中抓取数据。例如,谷歌、百度、必应等搜索引擎都是利用网络爬虫技术从互联网上采集海量的数据。
舆情分析与监测
政府或企业通过网络爬虫技术自动采集论坛评论、在线博客、新闻媒体或微博等网站中的海量数据,采用数据挖掘的相关方法(如词频统计、文本情感计算、主题识别等)发掘舆情热点,跟踪目标话题,并根据一定的标准采取相应的舆情控制与引导措施。例如,百度热点排行榜、微博热搜排行榜。
聚合平台
如今出现的很多聚合平台,如返利网、慢慢买等,也是网络爬虫技术的常见的应用场景,这些平台就是运用网络爬虫技术对一些电商平台上的商品信息进行采集,将所有的商品信息放到自己的平台上展示,并提供横向数据的比较,帮助用户寻找实惠的商品价格。例如,用户在慢慢买平台搜索华为智能手表后,平台上展示了很多款华为智能手表的价格分析及价格走势等信息。
出行类软件
出行类软件,比如飞猪、携程、去哪儿等,也是网络爬虫应用比较多的场景。这类应用运用网络爬虫技术,不断地访问交通出行的官方售票网站刷新余票,一旦发现有新的余票便会通知用户付款买票。不过,官方售票网站并不欢迎网络爬虫的这种行为,因为高频率地访问网页极易造成网站出现瘫痪的情况。
1.3 网络爬虫合法性研究
网络爬虫在访问网站时,需要遵循"有礼貌"的原则,这样才能与更多的网站建立友好关系。即便如此,网络爬虫的爬行行为仍会给网站增加不小的压力,严重时甚至可能会影响网站的正常访问。为了约束网络爬虫的恶意行为,网站内部加入了一些防爬虫措施来阻止网络爬虫。与此同时,网络爬虫也研究了防爬虫措施的应对策略。
Robots协议
Robots协议又称爬虫协议,它是国际互联网界通行的道德规范,用于保护网站数据和敏感信息,确保网站用户的个人信息和隐私不受侵犯。为了让网络爬虫了解网站的访问范围,网站管理员通常会在网站的根目录下放置一个符合Robots协议的robots.txt文件,通过这个文件告知网络爬虫在抓取该网站时存在哪些限制,哪些网页是允许被抓取的,哪些网页是禁止被抓取的。
robots.txt文件
当网络爬虫访问网站时,应先检查该网站的根目录下是否存在robots.txt文件。若robots.txt文件不存在,则网络爬虫会访问该网站上所有被口令保护的页面;若robots.txt文件存在,则网络爬虫会按照该文件的内容确定访问网站的范围。
robots.txt文件中的内容有着一套通用的写作规范。下面以豆瓣网站根目录下的robots.txt文件为例,分析robots.txt文件的语法规则。
豆瓣网站robots.txt文件
User-agent: *
Disallow: /subject_search
Disallow: /share/
Allow: /ads.txt
Sitemap: https://www.douban.com/sitemap_index.xml
Sitemap:
https://www.douban.com/sitemap_updated_index.xml
# Crawl-delay: 5
User-agent: Wandoujia Spider
Disallow: /
User-agent: Mediapartners-Google
robots.txt文件选项说明
●User-agent:用于指定网络爬虫的名称。若该选项的值为"*",则说明robots.txt文件对任何网络爬虫均有效。带有"*"号的User-agent选项只能出现一次。例如,示例的第一条语句User-agent: *。
●Disallow:用于指定网络爬虫禁止访问的目录。若Disallow选项的内容为空,说明网站的任何内容都是被允许访问的。在robots.txt文件中,至少要有一个包含Disallow选项的语句。例如,Disallow: /subject_search禁止网络爬虫访问目录/subject_search。
robots.txt文件选项说明
● Allow:用于指定网络爬虫允许访问的目录。例如,Allow:/ads.txt表示允许网络爬虫访问目录/ads.txt。
● Sitemap:用于告知网络爬虫网站地图的路径。例如,Sitemap:https://www.douban.com/sitemap_index.xml和https://www.douban.com/sitemap_updated_index.xml这两个路径都是网站地图,主要说明网站更新时间、更新频率、网址重要程度等信息。
注意:
Robots协议只是一个网站与网络爬虫之间达成的"君子"协议,它并不是计算机中的防火墙,没有实际的约束力。如果把网站比作私人花园,那么robots.txt文件便是私人花园门口的告示牌,这个告示牌上写有是否可以进入花园,以及进入花园后应该遵守的规则,但告示牌并不是高高的围栏,它只对遵守协议的"君子"有用,对于违背协议的人而言并没有太大的作用。
尽管Robots协议没有一定的强制约束力,但网络爬虫仍然要遵守协议,违背协议可能会存在一定的法律风险。
技术栈:
- 请求库:requests
- 解析库:BeautifulSoup、re
- 数据处理:pandas
- 可视化:matplotlib、pyecharts
https://img9.doubanio.com/view/photo/s_ratio_poster/public/p480747492.webp
一、前言
在数据获取与分析领域,网络爬虫技术扮演着重要角色。本文将带领大家使用Python实现一个功能完整的电影数据爬虫,通过Ajax请求、正则表达式和BeautifulSoup三种方式解析豆瓣电影Top250数据,并对数据进行可视化分析。
技术栈:
- 请求库:requests
- 解析库:BeautifulSoup、re
- 数据处理:pandas
- 可视化:matplotlib、pyecharts
二、项目准备
2.1 安装必要库
pip install requests beautifulsoup4 pandas matplotlib pyecharts
2.2 目标分析
豆瓣电影Top250页面特点:
- 分页加载(每页25条,共10页)
- 包含静态HTML和动态Ajax数据
- 反爬机制:请求频率限制、User-Agent检测
三、三种解析方式实战
3.1 BeautifulSoup解析静态页面
import requests
from bs4 import BeautifulSoup
import pandas as pd
def bs4_parser(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
movies = []
for item in soup.find_all('div', class_='item'):
title = item.find('span', class_='title').get_text()
rating = item.find('span', class_='rating_num').get_text()
# 其他字段提取...
movies.append({'title': title, 'rating': rating})
return pd.DataFrame(movies)
# 示例使用
df = bs4_parser("https://movie.douban.com/top250?start=0")
3.2 正则表达式提取关键数据
import re
def regex_parser(html):
pattern = re.compile(
r'<span class="title">([^<]+)</span>.*?'
r'<span class="rating_num".*?>([^<]+)</span>.*?'
r'<span>([\d,]+)人评价</span>', re.S
)
items = re.findall(pattern, html)
return pd.DataFrame(items, columns=['title', 'rating', 'votes'])
# 示例使用
html = requests.get(url, headers=headers).text
df = regex_parser(html)
3.3 Ajax动态数据抓取
def ajax_crawler():
base_url = "https://movie.douban.com/j/chart/top_list?"
params = {
'type': '5',
'interval_id': '100:90',
'action': '',
'start': '0',
'limit': '20'
}
response = requests.get(base_url, headers=headers, params=params)
data = response.json()
movies = []
for item in data:
movies.append({
'title': item['title'],
'rating': item['score'],
'votes': item['vote_count']
})
return pd.DataFrame(movies)
四、完整爬虫实现
import time
import random
from tqdm import tqdm
def douban_top250_crawler():
base_url = "https://movie.douban.com/top250?start={}"
all_data = []
for page in tqdm(range(0, 250, 25)):
url = base_url.format(page)
try:
# 三种解析方式结合使用
html = requests.get(url, headers=headers).text
bs4_data = bs4_parser(url)
regex_data = regex_parser(html)
# 数据合并与去重
merged = pd.merge(bs4_data, regex_data, on='title')
all_data.append(merged)
time.sleep(random.uniform(1, 3))
except Exception as e:
print(f"第{page//25+1}页爬取失败:", e)
return pd.concat(all_data).drop_duplicates()
五、数据可视化分析
5.1 评分分布直方图
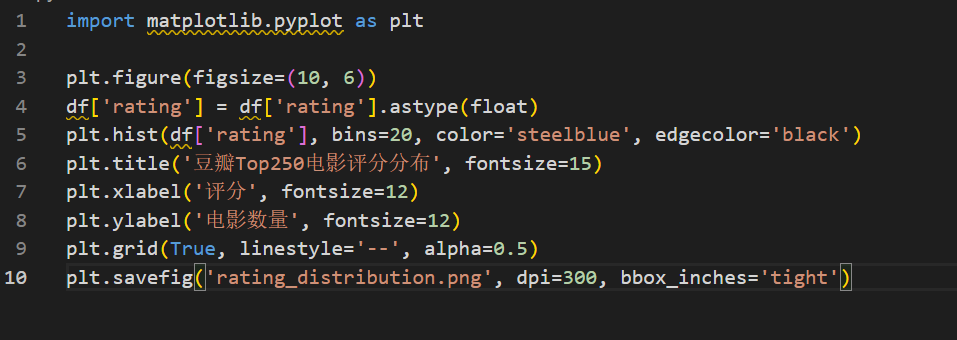
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
df['rating'] = df['rating'].astype(float)
plt.hist(df['rating'], bins=20, color='steelblue', edgecolor='black')
plt.title('豆瓣Top250电影评分分布', fontsize=15)
plt.xlabel('评分', fontsize=12)
plt.ylabel('电影数量', fontsize=12)
plt.grid(True, linestyle='--', alpha=0.5)
plt.savefig('rating_distribution.png', dpi=300, bbox_inches='tight')
5.2 评分与评价人数关系图
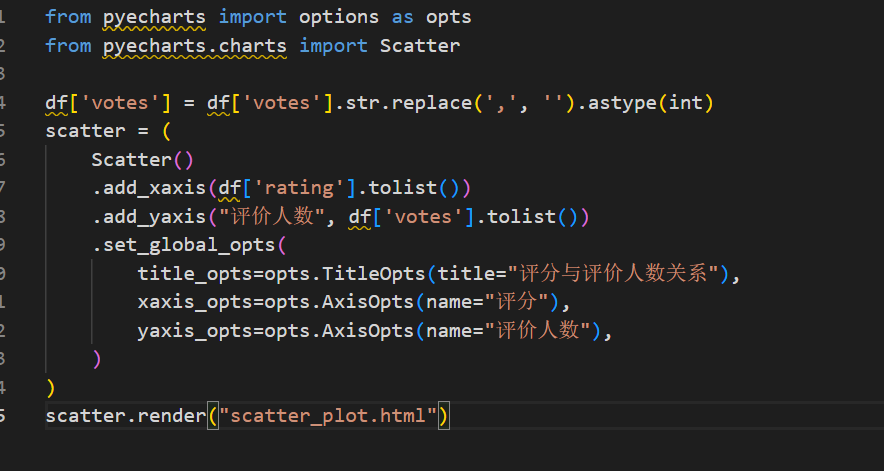
from pyecharts import options as opts
from pyecharts.charts import Scatter
df['votes'] = df['votes'].str.replace(',', '').astype(int)
scatter = (
Scatter()
.add_xaxis(df['rating'].tolist())
.add_yaxis("评价人数", df['votes'].tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title="评分与评价人数关系"),
xaxis_opts=opts.AxisOpts(name="评分"),
yaxis_opts=opts.AxisOpts(name="评价人数"),
)
)
scatter.render("scatter_plot.html")
六、反爬策略与优化
6.1 请求头伪装

headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Referer': 'https://movie.douban.com/',
'Cookie': '你的cookie'
}
6.2 IP代理池
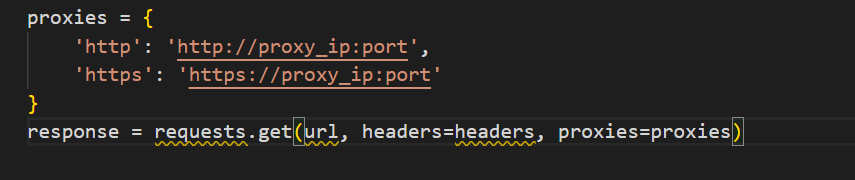
proxies = {
'http': 'http://proxy_ip:port',
'https': 'https://proxy_ip:port'
}
response = requests.get(url, headers=headers, proxies=proxies)
6.3 异常处理机制
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status()
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
return None
七、总结
本文通过三种技术方案实现了豆瓣电影数据的抓取:
- BeautifulSoup:适合结构化HTML解析
- 正则表达式:高效提取特定模式数据
- Ajax请求:处理动态加载内容
完整代码:
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
import time
import random
import matplotlib.pyplot as plt
from pyecharts.charts import Scatter
from pyecharts import options as opts
from tqdm import tqdm
# 1. 基础设置
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Referer': 'https://movie.douban.com/'
}
# 2. BeautifulSoup解析器
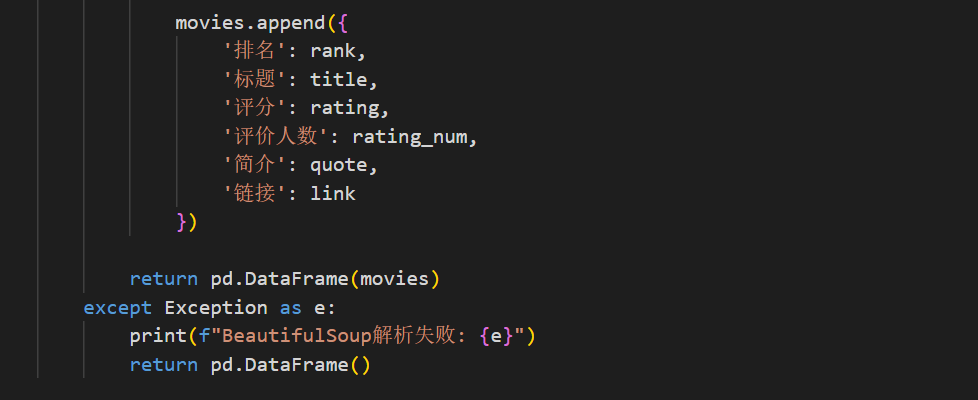
def bs4_parser(url):
try:
response = requests.get(url, headers=HEADERS)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
movies = []
for item in soup.find_all('div', class_='item'):
rank = item.find('em').get_text()
title = item.find('span', class_='title').get_text()
rating = item.find('span', class_='rating_num').get_text()
rating_num = item.find('div', class_='star').find_all('span')[-1].get_text()[:-3]
quote = item.find('span', class_='inq').get_text() if item.find('span', class_='inq') else ''
link = item.find('a')['href']
movies.append({
'排名': rank,
'标题': title,
'评分': rating,
'评价人数': rating_num,
'简介': quote,
'链接': link
})
return pd.DataFrame(movies)
except Exception as e:
print(f"BeautifulSoup解析失败: {e}")
return pd.DataFrame()
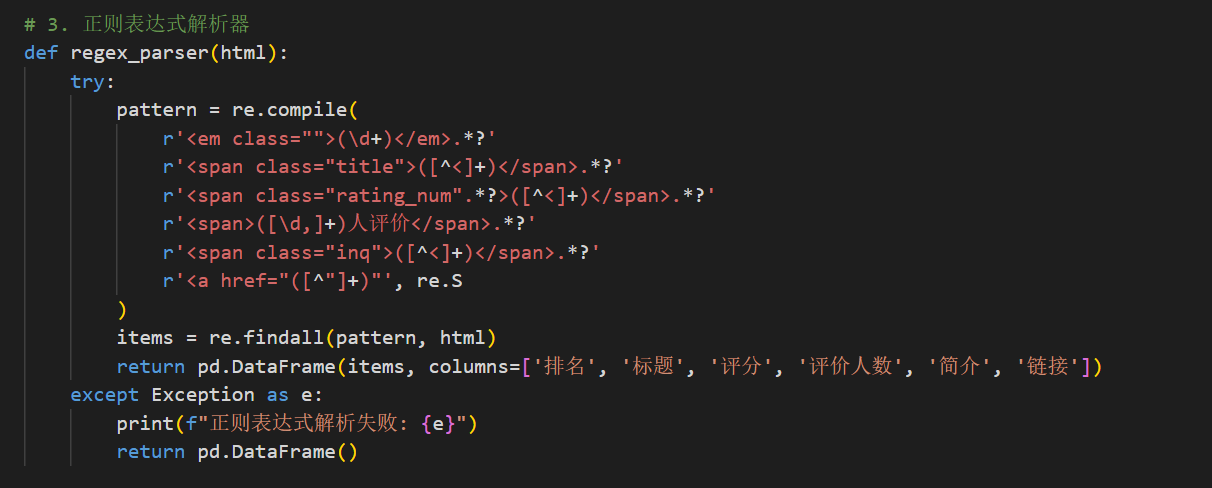
# 3. 正则表达式解析器
def regex_parser(html):
try:
pattern = re.compile(
r'<em class="">(\d+)</em>.*?'
r'<span class="title">([^<]+)</span>.*?'
r'<span class="rating_num".*?>([^<]+)</span>.*?'
r'<span>([\d,]+)人评价</span>.*?'
r'<span class="inq">([^<]+)</span>.*?'
r'<a href="([^"]+)"', re.S
)
items = re.findall(pattern, html)
return pd.DataFrame(items, columns=['排名', '标题', '评分', '评价人数', '简介', '链接'])
except Exception as e:
print(f"正则表达式解析失败: {e}")
return pd.DataFrame()
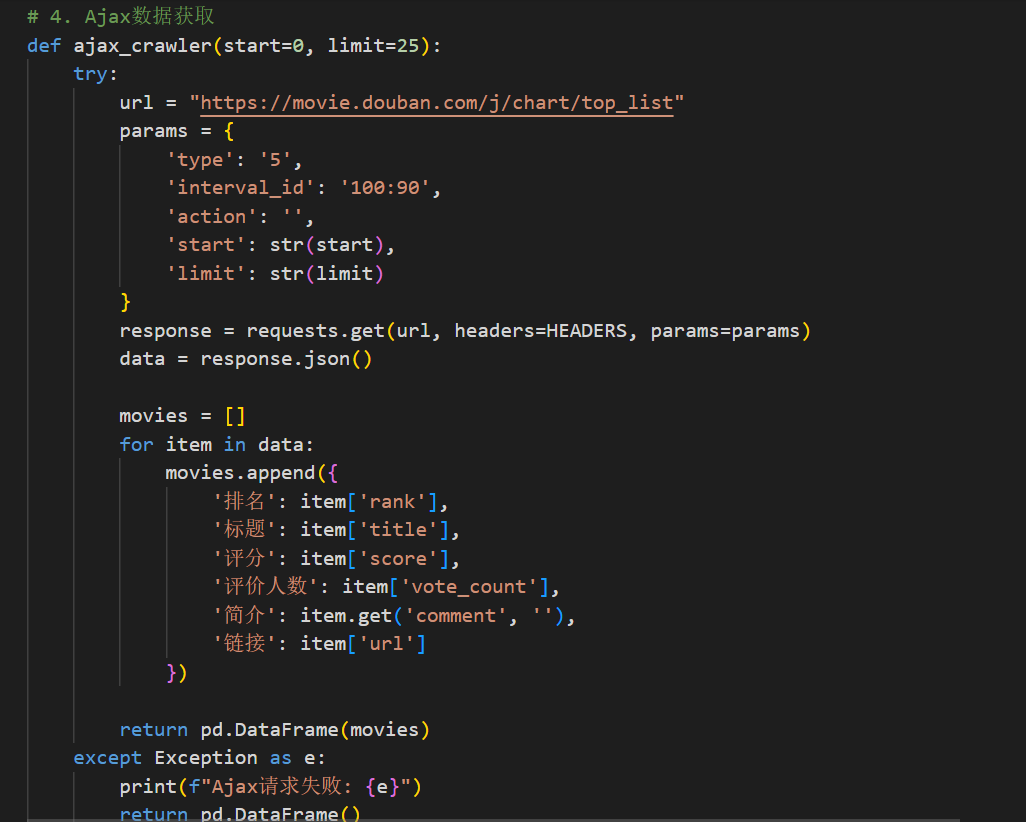
# 4. Ajax数据获取
def ajax_crawler(start=0, limit=25):
try:
url = "https://movie.douban.com/j/chart/top_list"
params = {
'type': '5',
'interval_id': '100:90',
'action': '',
'start': str(start),
'limit': str(limit)
}
response = requests.get(url, headers=HEADERS, params=params)
data = response.json()
movies = []
for item in data:
movies.append({
'排名': item['rank'],
'标题': item['title'],
'评分': item['score'],
'评价人数': item['vote_count'],
'简介': item.get('comment', ''),
'链接': item['url']
})
return pd.DataFrame(movies)
except Exception as e:
print(f"Ajax请求失败: {e}")
return pd.DataFrame()
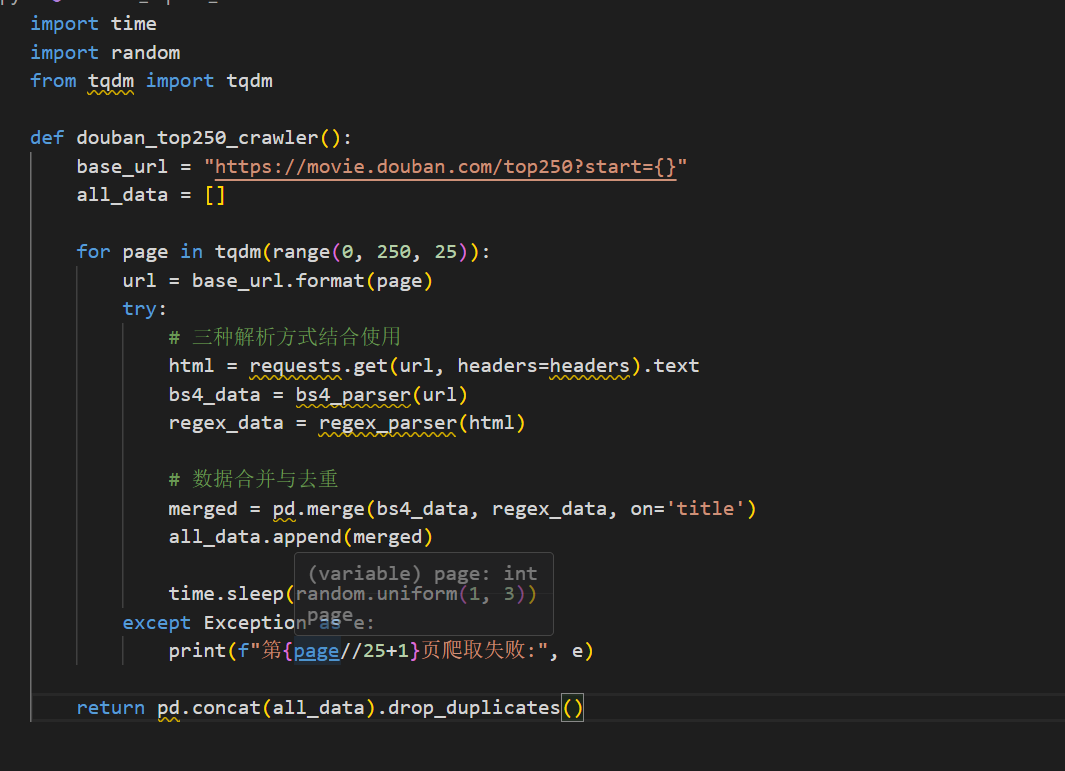
# 5. 完整爬虫主函数
def douban_top250_crawler():
base_url = "https://movie.douban.com/top250?start={}"
all_data = []
for page in tqdm(range(0, 250, 25), desc="爬取进度"):
url = base_url.format(page)
try:
# 获取HTML内容
response = requests.get(url, headers=HEADERS)
html = response.text
# 三种方式解析
bs4_data = bs4_parser(url)
regex_data = regex_parser(html)
ajax_data = ajax_crawler(page, 25)
# 合并数据(优先使用BeautifulSoup结果)
merged = bs4_data.combine_first(regex_data).combine_first(ajax_data)
all_data.append(merged)
time.sleep(random.uniform(2, 4))
except Exception as e:
print(f"第{page//25+1}页爬取失败: {e}")
# 合并所有数据
final_df = pd.concat(all_data).drop_duplicates(subset=['标题'])
final_df['排名'] = pd.to_numeric(final_df['排名'])
final_df = final_df.sort_values('排名').reset_index(drop=True)
return final_df
# 6. 数据可视化
def visualize_data(df):
# 数据清洗
df['评分'] = df['评分'].astype(float)
df['评价人数'] = df['评价人数'].str.replace(',', '').astype(int)
# 1. 评分分布直方图
plt.figure(figsize=(12, 6))
plt.hist(df['评分'], bins=20, color='#3498db', edgecolor='black', alpha=0.7)
plt.title('豆瓣Top250电影评分分布', fontsize=15)
plt.xlabel('评分', fontsize=12)
plt.ylabel('电影数量', fontsize=12)
plt.grid(True, linestyle='--', alpha=0.5)
plt.savefig('rating_distribution.png', dpi=300, bbox_inches='tight')
plt.show()
# 2. 评分与评价人数关系图
scatter = (
Scatter()
.add_xaxis(df['评分'].tolist())
.add_yaxis("评价人数", df['评价人数'].tolist(),
symbol_size=8,
label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title="评分与评价人数关系"),
xaxis_opts=opts.AxisOpts(name="评分"),
yaxis_opts=opts.AxisOpts(name="评价人数"),
tooltip_opts=opts.TooltipOpts(
formatter="{a}: {b}分<br/>{c}人评价")
)
)
scatter.render("scatter_plot.html")
# 3. 排名与评分关系
plt.figure(figsize=(12, 6))
plt.scatter(df['排名'], df['评分'], c='#e74c3c', alpha=0.6)
plt.title('电影排名与评分关系', fontsize=15)
plt.xlabel('排名', fontsize=12)
plt.ylabel('评分', fontsize=12)
plt.grid(True, linestyle='--', alpha=0.3)
plt.savefig('rank_rating.png', dpi=300, bbox_inches='tight')
plt.show()
# 7. 主程序
if __name__ == "__main__":
print("开始爬取豆瓣电影Top250数据...")
movie_data = douban_top250_crawler()
# 保存数据
movie_data.to_csv('douban_top250.csv', index=False, encoding='utf_8_sig')
print(f"爬取完成,共获取{len(movie_data)}条数据,已保存到douban_top250.csv")
# 数据可视化
print("开始生成可视化图表...")
visualize_data(movie_data)
print("可视化完成,请查看当前目录下的图片和HTML文件")
注意事项:
- 控制爬取频率,建议≥3秒/次
- 数据仅用于学习研究
- 遵守豆瓣robots.txt规定

















 199
199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









