







本次任务使用的的上分技巧是Lora微调,实现了出图效果的一个小小飞跃,从之前的古早热血漫画,画面变得更加细腻流畅。并且还使用了ComfyUI来部署绘图工作流。ComfyUI 的工作流是模块化地搭建的,它把图像生成的过程分解成了许多小的步骤(加载模型、输入Prompt、采样、VAE解码等),这样用户就可以个性化定制自己的图像生成过程。这种模块化的工作流会是后续AI应用产品中的一种趋势,值得好好学习。
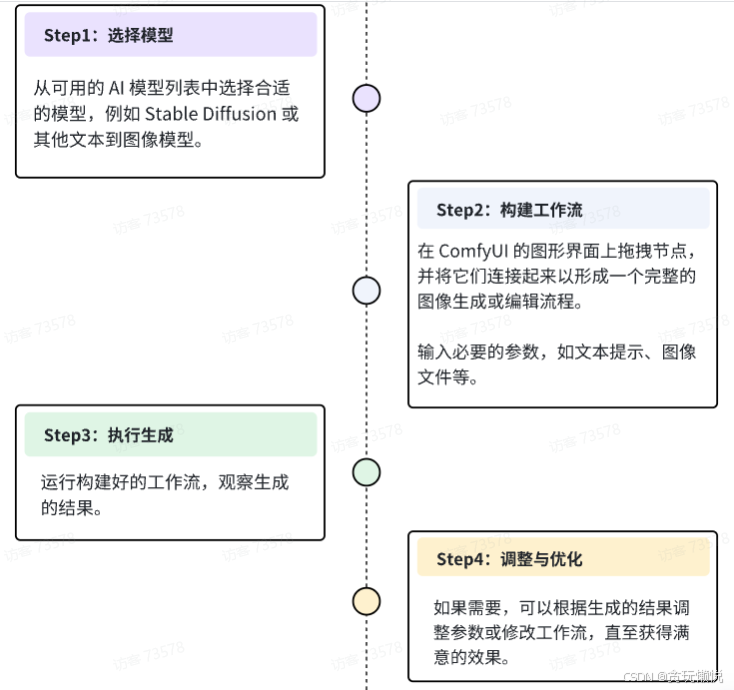
整个任务流程图如下:
- 选择并准备好使用的模型(本次使用的是用Lora微调过的可图大模型)
- 在comfyUI搭建工作流(加载模型、正负向提示词输入框、采样器、解码器…)
- 执行工作流,等待出图
- 进一步调整参数或者工作流
工作流实现成果:

一、 微调前后效果对比
微调前:

微调后:

微调前:

微调后:

二、Lora微调原理
讲得很清晰的一个链接放在这里:通俗易懂理解全量微调和Lora微调
微调本质
LoRA(Low-Rank Adaptation)是一种轻量级微调技术,微调技术的本质是在已有的预训练模型基础上进行一定的改动。
预训练模型通常在大规模数据集上进行训练,学习到了丰富的特征表示。微调则是将预训练模型的权重作为初始点,通过少量的新数据或特定任务的数据,更新部分或全部模型参数,使其在特定任务上表现更好。
举个例子,现在你有一个能识别数百种动物的AI模型,但你只关心识别猫的不同品种。为了不从头训练模型,你可以在原有的模型基础上,只用猫的图片进行少量训练,这样模型就能更好地识别猫的品种。
微调可以节省时间和资源,因为我们只是在调整模型的部分参数,而不是从零开始构建整个模型。
通俗易懂了解Lora
上面说到微调实质上是一种对模型的改动,而模型的改动实质上是模型参数的改动。从原有的参数变成现有的参数。
 从原有的参数矩阵变成现有参数矩阵的过程也可以用下面这个形式来表现:
从原有的参数矩阵变成现有参数矩阵的过程也可以用下面这个形式来表现:
W new = W old + Δ W \mathbf{W}_{\text{new}} = \mathbf{W}_{\text{old}} + \Delta \mathbf{W} Wnew=Wold+ΔW
我们可以简单地认为,本质上通过微调,我们要学习到的其实就是这个改动的量 Δ W \Delta \mathbf{W} ΔW, 在真实的训练过程中,矩阵里的参数是很多的,比如100亿个,如果用要把这些参数全部学习到,这是一个浩大的工程(全量微调),所以人们就想寻找更高效的方法,用更少量的资源进行微调。这样的一系列微调方法统称为PEFT,其中很常用的一种方法就是Lora(Low-Rank Adaptation)。
Lora为什么叫做Low-Rank呢?它利用了线性代数中的低秩矩阵分解来减少微调大模型时所需的参数量。Rank是“秩”,这是线性代数中个一个重要概念。什么是“秩”呢?可以简单地理解为一个矩阵的有效信息量。
比如看下面这个矩阵:
[ 1 2 3 2 4 6 3 4 5 ] \begin{bmatrix} 1 & 2 & 3 \\ 2 & 4 & 6 \\ 3 & 4 & 5 \end{bmatrix}
123244365
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 572
572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









