




 本文详细介绍了Spark中的RDD算子,包括RDD的输入、运行和输出过程,以及RDD的Transformation和Action算子。Transformation算子如map、filter和flatMap用于数据转换,而Action算子如collect、count和reduce则触发实际计算并返回结果或保存到文件系统。
本文详细介绍了Spark中的RDD算子,包括RDD的输入、运行和输出过程,以及RDD的Transformation和Action算子。Transformation算子如map、filter和flatMap用于数据转换,而Action算子如collect、count和reduce则触发实际计算并返回结果或保存到文件系统。
一、RDD算子简介
提供一优秀RDD讲解链接:https://blog.youkuaiyun.com/fortuna_i/article/details/81170565
spark在运行过程中通过算子对RDD进行计算,算子是RDD中定义的函数,可以对RDD中数据进行转换和操作,如下图
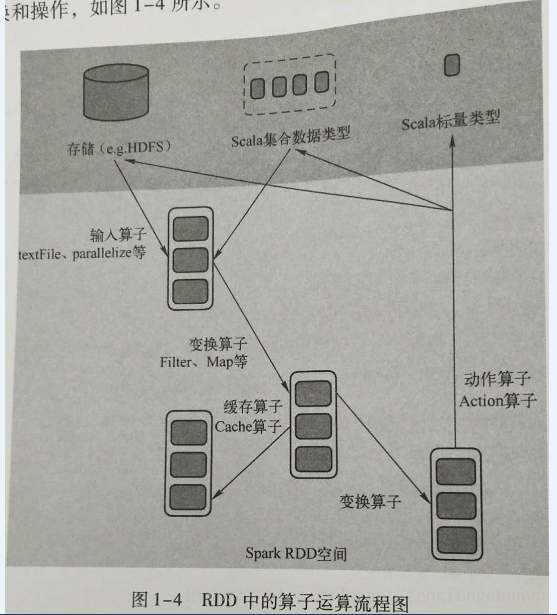
输入:spark程序中数据从外部数据空间输入到spark中的数据块,通过BlockManager进行管理
运行:在spark数据形成RDD后,可以通过变换算子,如filter等对数据进行操作,并将RDD转换为新的RDD,通过Action算子,触发Spark提交作业。如果数据复用,可以通过cache算子将数据缓存到内存中。
输出:程序运行结束后数据会输出Spark运行时的空间,存在到分布式存在结构(如:saveAsTextFile输出到HDFS)或者scala的数据集合中。
Spark将常用的大数据操作都转化成RDD的子类,Spark操作数据模型图如下;
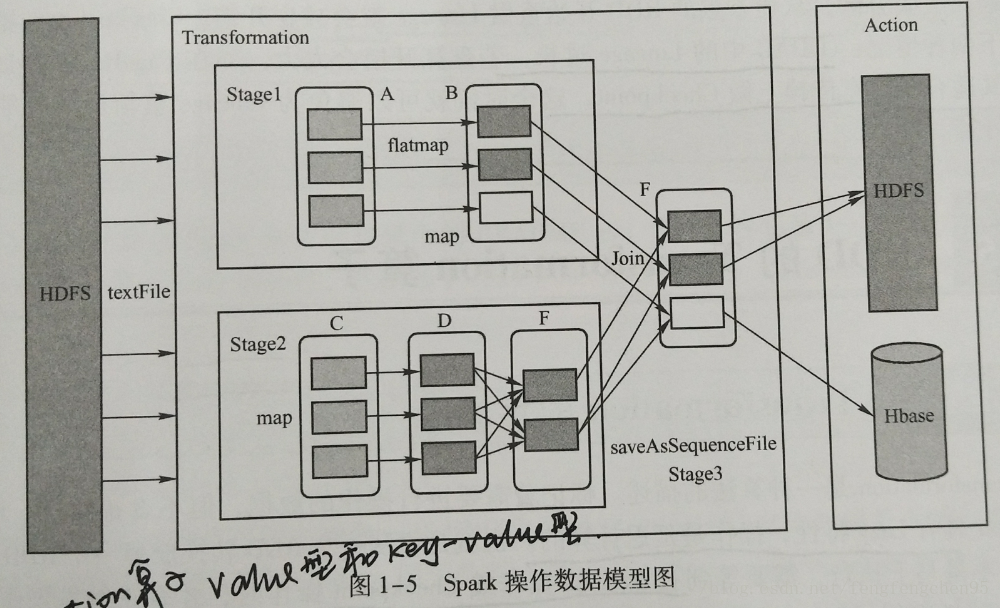
二、SparkRDD中的算子分类。
1.Value数据类型的Transformation算子,这种变化并不触发提供作业,针对处理的数据项是Value型的数据。
2.Key-Value类型的Transformati
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 606
606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









