




之前两篇文章分别通过keras深度学习框架构建简单神经网络和卷积神经网络实现过手写数字识别实验。这篇文章分享我根据LeNet5模型构建的卷积神经网络来实现手写数字识别。
这个实验是根据LeNet5模型构建卷积神经网络,LeNet5模型的原理图如下所示:
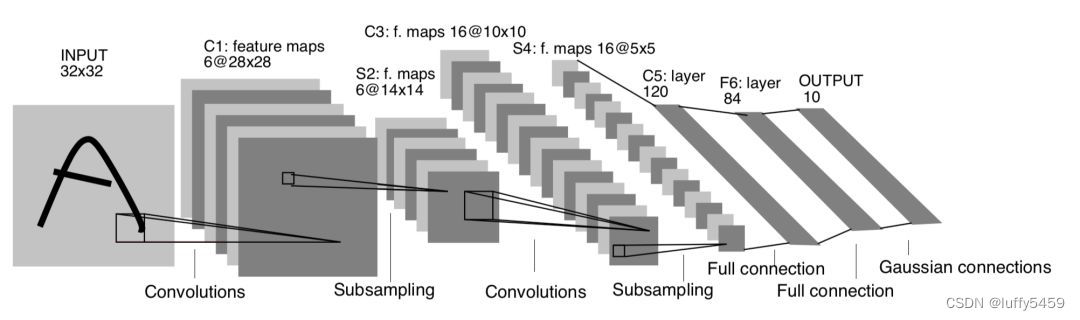
相信大家在很多地方见过这个模型,但是实际上,很多代码里面并没有严格按照这个模型来做实验。为什么?主要是手写数字识别模型数据mnist规格是28*28,而这个LeNet5模型需要的数据输入是32*32。大家为了凑合,就私自改了这个模型的参数,最后输入变为了28*28,然后经历第一次卷积之后,特征图就变成了6@24*24 ,下采样再缩小一半:6@12*12。到了全连接层的时候,特征图就变为了16@4*4。
其实这样修改,没有什么毛病,最后也能达到实验的目的,而且训练模型之后,测试准确率可以达到98%以上。
真正要按照这个LeNet5模型就需要32*32输入形状,而现如今好像只有KNN手写数字识别那个实验好像有32*32=1024规格的训练数据集trainingDigits和测试数据集testDigits,而且那个数据量比较少,训练数据集2000个,测试数据集900多个,另一个就是它的数据是文本,要得到那个数据,还需要读文本转换。
有一个折中的办法,就是我们可以通过opencv提供的resize方法把mnist数据集的28*28形状转为32*32形状,可能就是会丢失一些精度,而现在测试数据和用来预测图片数据也一样会修改,所以精度问题可以认为抵消。
其实本身这个模型也有一些模糊的地方,就是这图里面并没有给出下采样层的具体方式,是使用最大值采样,还是平均值采样,还有卷积层的激活函数,只有细看论文才能找到答案。
所以在实现中,卷积层的激活函数一般使用tanh,但是使用relu也没有问题,同理,下采样层SubSampling这里采用MaxPool2D,AveragePooling2D都行。
简单说一下这个模型:
输入图片矩阵形状 (32,32)
第一层卷积层:6个卷积核,卷积核大小5*5,所以输出特征图(feature maps)大小就是6@(32-5+1) * (32-5+1) = 6@28*28
第二层下采样(SubSampling):2*2大小,结果就是特征图大小继续减半6@14*14
第三层卷积层:16个卷积核,卷积核大小5*5,输出特征图大小:16@(14-5+1)*(14-5+1)=16@10*10
第四层下采样:2*2大小,特征图减小一半16@5*5
第五层展平层:120个神经元
第六层全连接层:84个神经元
第七层输出层:10个神经元
下面根据mnist数据集以及LeNet5数据模型搭建神经网络并训练测试,代码如下:
from keras.models import Sequential
from keras.layers import Conv2D, MaxPool2D, AveragePooling2D
from keras.layers import Dense, Flatten
import keras
from keras.datasets import mnist
from keras.utils import np_utils
from keras.utils.vis_utils import plot_model
import numpy as np
import cv2
# 加载数据
(X_train, y_train), (X_test, y_test) = mnist.load_data()
input_shape = (32, 32, 1)
train_x = []
test_x = []
for val in X_train:
img = cv2.resize(val, (input_shape[0], input_shape[1]))
train_x.append(img.reshape(input_shape))
for val_ in X_test:
img = cv2.resize(val_, (input_shape[0], input_shape[1]))
test_x.append(img.reshape(input_shape))
# 数据预处理
X_train = np.array(train_x) / 255.0
X_test = np.array(test_x) / 255.0
# to_categorical()将类别向量转换为二进制(只有0和1)的矩阵类型表示
y_train = np_utils.to_categorical(y_train, num_classes=10)
y_test = np_utils.to_categorical(y_test, num_classes=10)
model = Sequential()
model.add(Conv2D(6, kernel_size=(5, 5), activation='tanh', input_shape=input_shape))
model.add(AveragePooling2D(pool_size=(2, 2)))
model.add(Conv2D(16, kernel_size=(5, 5), activation='tanh'))
model.add(AveragePooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(120, activation='tanh'))
model.add(Dense(84, activation='tanh'))
model.add(Dense(10, activation='softmax'))
# 模型编译
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()
# 训练
model.fit(X_train, y_train, batch_size=128, epochs=10)
# 评估模型
score = model.evaluate(X_test, y_test)
print('acc', score[1])
plot_model(model, to_file='model.png', show_shapes=True)
model.save("lenet5.h5")
运行代码,打印模型参数信息如下所示:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 6) 156
average_pooling2d (AverageP (None, 14, 14, 6) 0
ooling2D)
conv2d_1 (Conv2D) (None, 10, 10, 16) 2416
average_pooling2d_1 (Averag (None, 5, 5, 16) 0
ePooling2D)
flatten (Flatten) (None, 400) 0
dense (Dense) (None, 120) 48120
dense_1 (Dense) (None, 84) 10164
dense_2 (Dense) (None, 10) 850
=================================================================
Total params: 61,706
Trainable params: 61,706
Non-trainable params: 0
训练和测试过程如下:
Epoch 1/10
2023-08-30 22:04:32.166768: I tensorflow/stream_executor/cuda/cuda_dnn.cc:368] Loaded cuDNN version 8800
469/469 [==============================] - 8s 12ms/step - loss: 0.3042 - accuracy: 0.9110
Epoch 2/10
469/469 [==============================] - 5s 10ms/step - loss: 0.1113 - accuracy: 0.9664
Epoch 3/10
469/469 [==============================] - 5s 10ms/step - loss: 0.0709 - accuracy: 0.9784
Epoch 4/10
469/469 [==============================] - 5s 11ms/step - loss: 0.0530 - accuracy: 0.9843
Epoch 5/10
469/469 [==============================] - 5s 11ms/step - loss: 0.0410 - accuracy: 0.9875
Epoch 6/10
469/469 [==============================] - 5s 11ms/step - loss: 0.0329 - accuracy: 0.9898
Epoch 7/10
469/469 [==============================] - 6s 12ms/step - loss: 0.0283 - accuracy: 0.9910
Epoch 8/10
469/469 [==============================] - 6s 12ms/step - loss: 0.0228 - accuracy: 0.9928
Epoch 9/10
469/469 [==============================] - 6s 12ms/step - loss: 0.0193 - accuracy: 0.9939
Epoch 10/10
469/469 [==============================] - 6s 13ms/step - loss: 0.0159 - accuracy: 0.9949
313/313 [==============================] - 2s 4ms/step - loss: 0.0406 - accuracy: 0.9871
acc 0.9871000051498413
测试准确率高达98.7%。
代码最后,我们还通过plot_model保存了模型图片:
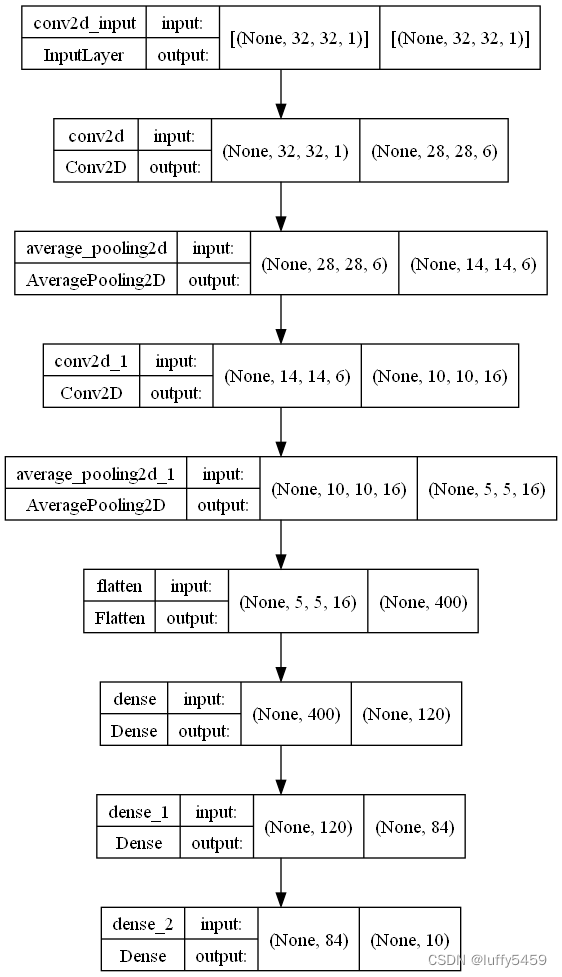
另外,为了用来预测,我们还保存了模型文件lenet5.h5。
预测,还是祖传代码,改动了图片形状32*32像素,因为预测图片还是28*28像素,黑底白字:










import keras
import numpy as np
import cv2
from keras.models import load_model
model = load_model("lenet5.h5")
def predict(img_path):
img = cv2.imread(img_path, 0)
img = cv2.resize(img, (32, 32))
img = img.astype("float32") / 255 # 0 1
img = img.reshape(1, 32, 32, 1) # 32 * 32 -> (1,32,32,1)
label = model.predict(img)
label = np.argmax(label, axis=1)
print('{} -> {}'.format(img_path, label[0]))
if __name__ == '__main__':
for _ in range(10):
predict("number_images/b_{}.png".format(_))
实验结果:
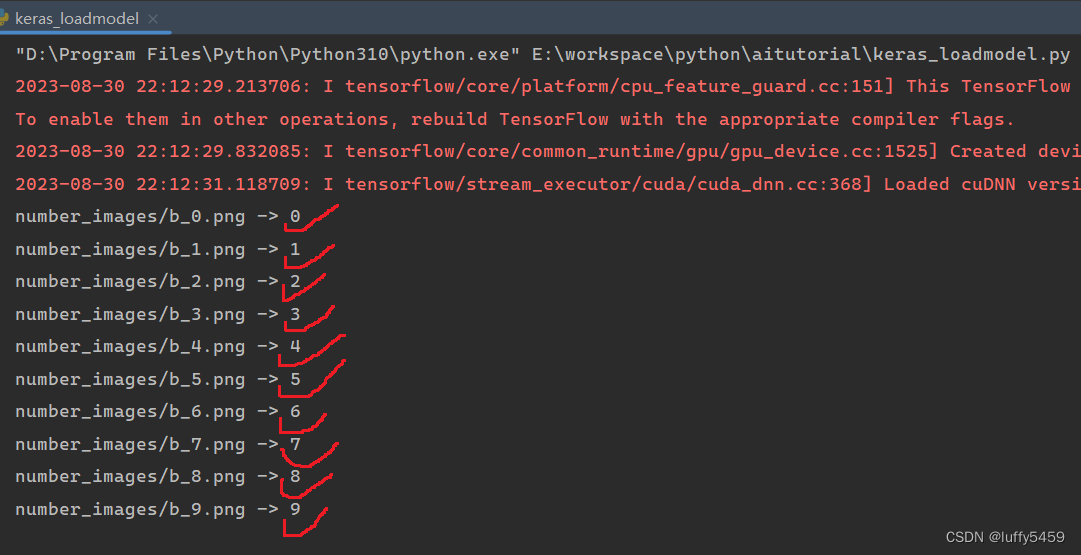
这个结果,其实并不意外,也不是因为这个模型非常牛逼,预测高达100%,其实这里预测的图片只有10个,数量不多,很多图片都是自己测试过的,所以看着好像很厉害。
这里面有很多可变的地方,第一个就是前面说过的输入大小的问题,如果我们改动32*32到28*28,那么我们在使用mnist数据集的时候,也不用修改形状。但是这个就与这个模型有出入,虽然最后也能运行出很高的测试准确率和预测准确率。再一个可变的地方就是卷积层的激活函数,这里使用的是tanh,其实使用relu也没问题,再一个就是使用MaxPool2D作为下采样也是可以的。在模型编译的时候,我们使用的是rmsprop优化器,其实adam也行。
LeNet5模型其实非常适合用来做数字识别,但是数字识别没有合适的训练数据集,而cifar10这个数据集就是32*32的,所以,从编码角度来说,这个模型最适合的还是图像分类。


















 1186
1186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











