




1、官网下载Hadoop(此处就不细讲了,这里我用的是hadoop-2.6.1.tar.gz版本)
2、将下载下来的hadoop上传到Linux的的当前用户文件夹中
3、复制hadoop到/usr文件夹中
cp hadoop-2.6.1.tar /usr
4、在/usr中解压,(解压后得到文件夹hadoop-2.6.1),并重命名为hadoop
tar -xzvf hadoop-2.6.1.tar.gz
mv hadoop-2.6.1 hadoop
5、进入到hadoop文件夹中进行配置
cd etc/hadoop(注意这个命令的前提是当前文件夹为/etc/hadoop)
6、开始配置hadoop
1)配置hadoop-env.sh
vi hadoop-env.sh
添加JDK路径,即
2)配置core-site.xml
vi core-site.xml

3)配置hdfs-site.xml
vi hdfs-siet.xml
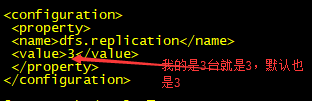
4)配置mapred-site.xml
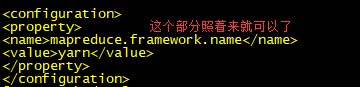
5)配置yarn-site.xml
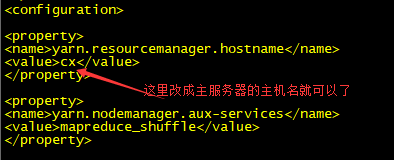
6)配置slave文件(就是将原来文件里面的内容删除,然后添加3台虚拟机的主机名)

7、然后到/usr/hadoop/bin下,执行hadoop格式化
hdfs namenode -format
8、将Hadoop添加到环境变量中:vi /etc/profile

9、加载配置文件(否则在后面输入hdfs命令时,会提示没有这个命令,或者命令找不到)
source /etc/profile
10、将hadoop和p配置文件分发到另外两台机上
scp -r /usr/hadoop cx1:/usr
scp -r /usr/hadoop cx2/usr
scp /etc/profile cx1:/etc
scp /etc/profile cx2/etc
11、一定记得在另外两台机上source一下分发过去的配置文件
source /etc/perofile
12、启动HDFS
start-dfs.sh
13、然后分别在三台服务器上输入命令jps,表明安装成功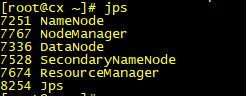
Linux中如何安装配置Hadoop?
最新推荐文章于 2025-10-04 11:27:22 发布
 本文详细介绍了在Linux系统中安装配置Hadoop的步骤,包括下载Hadoop、上传到Linux、解压、配置环境变量、配置相关XML文件、格式化HDFS、分发配置到多台机器以及启动HDFS的过程。
本文详细介绍了在Linux系统中安装配置Hadoop的步骤,包括下载Hadoop、上传到Linux、解压、配置环境变量、配置相关XML文件、格式化HDFS、分发配置到多台机器以及启动HDFS的过程。
部署运行你感兴趣的模型镜像
您可能感兴趣的与本文相关的镜像

Python3.10
Conda
Python
Python 是一种高级、解释型、通用的编程语言,以其简洁易读的语法而闻名,适用于广泛的应用,包括Web开发、数据分析、人工智能和自动化脚本

















 3007
3007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









