






 本文详细介绍了MySQL数据库的基础知识,包括数据库的概念、数据库管理系统(DBMS)和数据库应用系统的定义。重点讲解了MySQL的安装、SQL语言的六大部分、表的创建、查询、约束以及数据操作。还涉及到数据的备份与恢复、索引、视图和事务处理,深入浅出地阐述了MySQL的使用和管理。
本文详细介绍了MySQL数据库的基础知识,包括数据库的概念、数据库管理系统(DBMS)和数据库应用系统的定义。重点讲解了MySQL的安装、SQL语言的六大部分、表的创建、查询、约束以及数据操作。还涉及到数据的备份与恢复、索引、视图和事务处理,深入浅出地阐述了MySQL的使用和管理。
MySQL
mysql具体安装方法请百度
- MySQL介绍
①数据库(Database,简称DB)
是按照数据结构来组织、存储和管理数据的仓库.保存有组织的数据的容器(通常是一个文件或一组文件)
②数据库管理系统(Database Management System,简称DBMS)
① 专门用于管理数据库的计算机系统软件;
② 能够为数据库提供数据的定义、建立、维护、查询和统计等操作功能,并对数据完整性、安全性进行控制;
- 我们一般说的数据库,就是指的DBMS,例如我们马上学习的MySQL就是其中之一;
③数据库应用系统(Database Application System)
使用数据库技术的系统,基本上所有的信息系统都是数据库应用系统,它通常由软件、数据库和数据管理员组成。我们开发一款软件,然后这款软件能使用到数据库(和数据库有关系,有通信),那么,这一款软件我们就可以称之为数据库应用系统。
关系数据库技术阶段;
经典的里程碑阶段。代表DBMS:Oracle、DB2、MySQL、SQL Server、SyBase等。
SQL:结构化查询语言(Structured Query Language),是关系数据库的标准语言,它的特点是:简单、灵活、功能强大。它具体包含以下6个部分:
1、数据查询语言(DQL):查询数据
2、数据操作语言(DML):对数据库操作添加,修改,删除
3、事务处理语言(TPL):
4、数据控制语言(DCL):
5、数据定义语言(DDL):创建删除修改数据库(表,列...) 【数据定义】
6、指针控制语言(CCL):
SQL的书写规范:
1. 在MySQL数据库中,SQL语句大小写不敏感
2. SQL语句可单行或多行书写
3. 在SQL语句中,关键字不能跨多行或缩写
4. 为了提高可读性,一般关键字大写,其他小写
5. 空格和缩进使程序易读
启动MySQL服务
- 命令的方式:
-
- 启动MySQL服务 : net start MySQL
- 关闭MySQL服务 : net stop MySQL
-
连接MySQL
- 在运行窗口或者命令提示符窗口输入如下的命令:
-
- mysql -uroot -padmin -hlocalhost -P3306
-
或者:mysql -uroot -padmin -h127.0.0.1 -P3306
或者:mysql -uroot -padmin -h192.168.1.100 -P3306
localhost 和 127.0.0.1 都代表的本机
-
-
- 3306,可以这样简写:
-
mysql -uroot -padmin
mysql -uroot -p
弹出界面再输入密码就是****
- 直接在开始 > 程序 > MySQL 中点开MySQL的命令提示符窗口, 然后输入密码即可
MySQL的日期与时间类型

创建表
语法:
1. 先进入某一个数据库: use database_name;
2. 输入建表的SQL命令:
CREATE TABLE 表名(
列名1 列的类型 [约束],
列名2 列的类型 [约束],
....
列名N 列的类型 约束
);
查看表结构和删除表
SHOW TABLES; 查看数据库中存在哪些表:
DESC table_name; 查看表结构:
SHOW CREATE TABLE table_name; 查看表的详细定义(定义表的SQL语句)
DROP TABLE table_name; 删除表
表的约束
表的约束(针对于某一列):
1.非空约束(NK):NOT NULL,不允许某列的内容为空。
2.设置列的默认值:DEFAULT。
2.查询
简单数据查询
语法:
SELECT {*, column [alias],...}
FROM table_name;
说明:
SELECT 选择查询列表
FROM 提供数据源(表、视图或其他的数据源)
如果为 * 和创建表时的顺序一致。
可以自己调整顺序,在select后边加上要查询的列名。
需求:
查询所有货品信息
查询所有货品的id,productName,salePrice
5.1.2 消除结果中重复的数据。只对某一列有效
需求: 查询商品的分类编号。
语法: SELECT DISTINCT 列名,..
5.1.3 实现数学运算查询:
对NUMBER型数据可以使用算数操作符创建表达式(+ - * /)
对DATE型数据可以使用部分算数操作符创建表达式 (+ -)
运算符优先级:
1. 乘法和除法的优先级高于加法和减法
2. 同级运算的顺序是从左到右
3. 表达式中使用"括号"可强行改变优先级的运算顺序
需求:
查询所有货品的id,名称和批发价(批发价=卖价*折扣)
查询所有货品的id,名称,和各进50个的成本价(成本=costPrice)
查询所有货品的id,名称,各进50个,并且每个运费1元的成本
5.1.4 设置列名的别名
1、改变列的标题头;
2、用于表示计算结果的含义;
3、作为列的别名;
4、如果别名中使用特殊字符,或者是强制大小写敏感,或有空格时,都需加单引号;--->英文单词
需求:查询所有货品的id,名称,各进50个,并且每个运费1元的成本(使用别名)
5.1.5 设置显示格式:
为方便用户浏览查询的结果数据,有时需要设置显示格式,可以使用CONCAT函数来连接字符串。
需求:查询商品的名字和零售价。
格式:xxx商品的零售价为:xxx
SELECT CONCAT(productName,'商品的零售价为:',salePrice) AS productSalePrice FROM product;
5.2 过滤查询
5.2.1 比较运算符
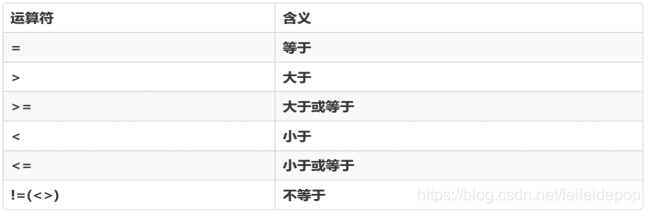
语法
SELECT <selectList>
FROM table_name
WHERE 条件1 AND/OR 条件2;
需求:
查询货品零售价为119的所有货品信息.
查询货品名为罗技G9X的所有货品信息.
查询货品名 不为 罗技G9X的所有货品信息.
查询分类编号不等于2的货品信息
查询货品名称,零售价小于等于200的货品
查询id,货品名称,批发价大于350的货品
思考:使用where后面使用别名不行,总结select和where的执行顺序
注意:字符串和日期要用单引号扩起来.
要让MySQL查询区分大小写,可以:
SELECT * FROM table_name WHERE BINARY productName='g9x'
SELECT * FROM table_name WHERE BINARY productName='G9X'
5.2.2 逻辑运算

需求:
选择id,货品名称,批发价在300-400之间的货品
选择id,货品名称,分类编号为2,4的所有货品
选择id,货品名词,分类编号不为2的所有商品
选择id,货品名称,分类编号的货品零售价大于等于250或者是成本大于等于200
5.2.3 优先级规则

注意: () 小括号跨越所有运算符优先级
5.2.4 范围查询-BETWEEN AND
使用BETWEEN运算符显示某一值域范围的记录,这个操作符最常见的使用在数字类型数据的范围上,但对于字符类型数据和日期类型数据同样可用。
语法:
SELECT <selectList>
FROM table_name
WHERE 列名 BETWEEN minvalue AND maxvalue:闭区间。
需求:
选择id,货品名称,批发价在300-400之间的货品
选择id,货品名称,批发价不在300-400之间的货品
5.2.5 集合查询- IN
使用IN运算符,判断列的值是否在指定的集合中。
语法:
SELECT <selectList>
FROM table_name
WHERE 列名 IN (值1,值2....);
需求:
选择id,货品名称,分类编号为2,4的所有货品
选择id,货品名称,分类编号不为2,4的所有货品
5.2.6 空值查询 IS NULL IFNULL
IS NULL:判断列的值是否为空。
语法:WHERE 列名 IS NULL;
需求: 查询商品名为NULL的所有商品信息。
注意 : 列的值是 null 和空字符串不一样,如果是空字符串 应该 = ""
ISNULL(expr)
IFNULL语法和isnull一样,is中expr传入的是判断值是否为真,IFNULL中传入两个值是判断expr1是否为真,true就返回expr2中的值,false返回expr1当前值
IFNULL(expr1,expr2)
5.2.7 模糊查询 LIKE
使用LIKE运算符执行通配查询,查询条件可包含文字字符或数字:
%:通配符:可表示零或多个任意的字符。
_:通配符:可表示任意的一个字符。
通配符:用来实现匹配部分值得特殊字符。
-----------------------------------------------------
需求:
查询id,货品名称,货品名称匹配'%罗技M9_'
查询id,货品名称,分类编号,零售价大于等于200并且货品名称匹配'%罗技M1__'
5.3 结果排序
使用ORDER BY子句将结果的记录排序:
ASC : 升序,缺省。
DESC: 降序。
ORDER BY 语句出现在SELECT语句的最后。
语法:
SELECT <selectList>
FROM table_name
WHERE 条件
ORDER BY 列名1 [ASC/DESC],列名2 [ASC/DESC]...;
需求:
选择id,货品名称,分类编号,零售价并且按零售价降序排序
选择id,货品名称,分类编号,零售价先按分类编号排序,再按零售价排序
查询M系列并按照批发价排序(加上别名)
查询分类为2并按照批发价排序(加上别名)
注意:别名不能使用引号括起来,否则不能排序。
SELECT语句执行顺序:
先执行FROM--->接着执行WHERE--->再执行SELECT--->最后执行ORDER BY
5.4 分页查询 LIMIT
分页设计:
假分页(逻辑分页): 把数据全部查询出来,存在于内存中,翻页的时候,直接从内存中去截取.
真分页(物理分页): 每次翻页都去数据库中去查询数据.
假分页: 翻页比较快,但是第一次查询很慢,若数据过大,可能导致内存溢出.
真分页: 翻页比较慢,若数据过大,不会导致内存溢出.
语法:
SELECT * FROM table_name LIMIT ?,?;
SELECT * FROM table_name LIMIT beginIndex,pageSize;
beginIndex = (currentPage-1) * pageSize;
第一个?: 表示本页,开始索引(从0开始).
第二个?: 每页显示的条数
规定:每页显示3条数据. pageSize = 3
第一页: SELECT * FROM `product` LIMIT 0, 3
第二页: SELECT * FROM `product` LIMIT 3, 3
第三页: SELECT * FROM `product` LIMIT 6, 3
第 N页: SELECT * FROM `product` LIMIT (N-1)*3, 3
5.5 聚集函数
定义:聚集函数作用于一组数据,并对一组数据返回一个值。
COUNT:统计结果记录数
MAX: 统计计算最大值
MIN: 统计计算最小值
SUM: 统计计算求和
AVG: 统计计算平均值
需求:
查询所有商品平均零售价
查询商品总记录数(注意在Java中必须使用long接收)
查询分类为2的商品总数
查询商品的最小零售价,最高零售价,以及所有商品零售价总和
5.6 分组查询 GROUP BY
可以使用GROUP BY 子句将表中的数据分成若干组,再对分组之后的数据做统计计算,一般使用聚集函数才使用GROUP BY.
语法格式:
SELECT <selectList>,聚集函数
FROM table_name
WHERE 条件
GROUP BY 列名
HAVING 分组之后的条件;
注意:GROUP BY 后面的列名的值要有重复性分组才有意义;
使用HAVING字句,对分组之后的结果作筛选;
不能在 WHERE 子句中使用组函数(注意);
可以在 HAVING 子句中使用组函数;
需求:
查询每个商品分类编号和每个商品分类各自的平均零售价
查询每个商品分类编号和每个商品分类各自的商品总数。
查询每个商品分类编号和每个商品分类中零售价大于100的商品总数:
查询零售价总和大于1500的商品分类编号以及总零售价和:

3.多表查询
迪卡尔积
1. 没有连接条件的表关系返回的结果。
2. 多表查询会产生笛卡尔积:
假设集合A={a,b},集合B={0,1,2},则两个集合的笛卡尔积为{(a,0),(a,1),(a,2),(b,0),(b,1),(b,2)}
3. 实际运行环境下,应避免使用全笛卡尔集。
4. 我们应该怎么去避免笛卡尔集?
在WHERE加入有效的连接条件---->等值连接
注意:连接 n张表,至少需要 n-1个连接条件。
外键约束
主键约束(PRIMARY KEY): 约束在当前表中,指定列的值非空且唯一.
外键约束(FOREIGN KEY): A表中的外键列. A表中的外键列的值必须参照于B表中的某一列(B表主键).
注意:
1. 在MySQL中,InnoDB支持事务和外键.
修改表的存储引擎为InnDB:
ALTER TABLE 表名 ENGINE='InnoDB';
2. 现有有些系统设计就是不用外键
内连接查询(显式与隐式)
内连接查询:是相对于外连接。
内连接分为:隐式内连接、显示内连接,其查询效果相同。
-----------------------------------------------
隐式内连接:
SELECT <selectList>
FROM A ,B WHERE A.列 = B.列
-----------------------------------------------
显示内连接(推荐写法):.
SELECT <selectList>
FROM A [INNER] JOIN B ON A.列 = B.列
外连接
外连接查询:
左外连接:查询出JOIN左边表的全部数据查询出来,JOIN右边的表不匹配的数据使用NULL来填充数据.
右外连接:查询出JOIN右边表的全部数据查询出来,JOIN左边的表不匹配的数据使用NULL来填充数据.
语法格式
SELECT <selectList>
FROM A LEFT/RIGHT OUTER JOIN B
ON (A.column_name = B.column_name)];
左连接:
SELECT * FROM product p LEFT JOIN productdir pd ON p.dir_id = pd.id
右连接:
SELECT * FROM product p RIGHT JOIN productdir pd ON p.dir_id = pd.id
思考:查询每种商品分类的名称和包含的的商品总数:
注意:这里有一个ifnull
自连接查询
自连接查询:
把一张表看成两张来做查询.一定要取别名...
需求: 查询每个商品分类的名称和父分类名称(所属分类的名称):
隐式内连接:
SELECT sub.dirName,super.dirName
FROM productdir super,productdir sub
WHERE sub.parent_id = super.id
显示内连接:
SELECT sub.dirName,super.dirName
FROM productdir super JOIN productdir sub
ON sub.parent_id = super.id
子查询
什么是子查询(嵌套查询):一个查询语句嵌套在另一个查询语句中,内层查询的结果可以作为外层查询条件。
一般的,嵌套在WHERE或者FROM字句中。
为什么使用子查询:
多表连接查询过程:
1):两张表做笛卡尔积。
2):筛选匹配条件的数据记录。
若,笛卡尔积记录数比较大,可能造成服务器崩溃。
插入数据(添加)
插入语句:一次插入操作只插入一行.
INSERT INTO table_name (column1,column2,column3...)
VALUES (value1,value2,value3...);
INSERT INTO table_name VALUES (value1,value2,value3...);
-------------------------------------------
1.插入完整数据记录
2.插入数据记录一部分
3.插入多条数据记录(MySQL特有)
INSERT INTO table_name (column1,column2,column3...)
VALUES (value1,value2,value3...),
(value1,value2,value3...),
(value1,value2,value3...)..;
4.插入查询结果
INSERT INTO table_name (column1,column2,column3...)
SELECT (column1,column2,column3...)
FROM table_name
INSERT INTO productdir (dirName,parent_id)
SELECT dirName,parent_id FROM productdir
修改数据
UPDATE table_name
SET columnName = value [, columnName = value] …
[WHERE condition];
如果省略了where子句,则全表的数据都会被修改。注意:没有FROM
-----------------------------------------------------------------
需求:将零售价大于300的货品零售价上调0.2倍
UPDATE product SET salePrice = salePrice * 1.2 WHERE salePrice > 300
需求:将零售价大于300的有线鼠标的货品零售价上调0.1倍
UPDATE product p
JOIN productdir pd ON p.dir_id = pd.id
SET p.salePrice = p.salePrice * 1.1
WHERE salePrice > 300 AND pd.dirName ="有线鼠标"
删除数据
DELETE FROM tablename
[WHERE condition];
如果省略了where子句,则全表的数据都会被删除
执行完毕,表框架还在。
数据的备份与恢复
MySql自身的数据库维护
通过cmd命令进入dos窗口:
1.导出:mysqldump -u账户 -p密码 数据库名称>脚本文件存储地址
mysqldump -uroot -padmin jdbcdemo> C:/shop_bak.sql
2.导入:mysql -u账户 -p密码 数据库名称< 脚本文件存储地址
mysql -uroot -padmin jdbcdemo< C:/shop_bak.sql
使用Navicat导入导出
Navicat工具的导入和导出/Navicat工具的备份和还原
Union联合基本语法
作用:Union可以把两组结构相同的数据合并。
1,合并的数据结构必须结构相等
2,union(不允许重复值)和union all(允许重复值,性能高)
UNION联合查询注意点
- UNION联合查询返回的列名是由第一个SELECT查询的字段名确定。
- 所有的SELECT查询的字段数量必须一致,类型不做要求。
- 有排序需求时,每个SELECT语句需要使用()和LIMIT子句。
小结
UNION联合查询可以把多个SELECT查询结果合并到一起。
索引
使用索引的注意点
- 索引也是数据库中的数据库对象;
- 在数据库中用来加速对表的查询;
- 通过使用快速路径访问方法快速定位数据,减少了磁盘的I/O;
- 与表独立存放(还会占用一定的存储空间)。空间换时间;
- 但是并不是所有字段都加上索引好,索引的维护(添删改)是比较耗费性能的;
- 怎么确定加不加索引:
根据查询与添删改的的频率来确定,一般经常查询,不经常修改的列,这个列中的重复数据比较多的情况,可以加索引。一般来说,外键往往伴随着索引
- 常见索引失效的情况:
like的”nihao%”这种形式以外的其他形式都会导致索引失效(因此查询的速度是非常慢的)
Select * from sss where 1=1 :索引失效、
视图(VIEW)(掌握)
什么是视图
视图是由SELECT语句组成的虚拟表
为什么要使用视图
- 简化复杂的查询。常用的、比较复杂的SELECT语句,创建一个视图,就能方便以后多次调用。
- 安全原因。比如,只想让权限低的用户看到一个表的部分字段,而隐藏机密的部分。
视图应用场景
视图主要使用在查询的场景中。一般不使用视图进行增删改的操作
注意:
如果视图包含下述结构中的任何一种,那么它就是不可更新的:
(1)聚合函数;
(2)DISTINCT关键字;
(3)GROUP BY子句;
(4)ORDER BY子句;
(5)HAVING子句;
(6)UNION运算符;
(7)位于选择列表中的子查询;
(8)FROM子句中包含多个表;
(9)SELECT语句中引用了不可更新视图;
(10)WHERE子句中的子查询,引用FROM子句中的表;
(11)ALGORITHM 选项指定为TEMPTABLE(使用临时表总会使视图成为不可更新的)。
创建视图
语法如下:
create view 视图名 as select 查询语句;
举例:创建一个视图,包含商品信息、商品分类、库存信息
create view view_product as
SQL语句
查询视图语法如下:
Select 字段名 from 视图名 where 子句 ...;
例子:从视图view_stu_class中查询中账户值大于5000的数据并且按照账户值逆序输出。
select *
from view_stu_class
where money > 5000
order by money desc;
修改视图
语法如下:
alter view 视图名 as select 查询语句;
删除视图
语法如下:
drop view 视图名;
视图注意点
-
-
-
- 视图的名字必须唯一,不能和其他表或视图重名。
- 视图可以嵌套使用,也就是视图里面可以再次调用视图。
- 视图的创建和删除只影响视图本身,不影响所使用的基本表,
-
-
小结
-
-
-
- 视图是由SELECT查询组成的虚拟表,是逻辑表,不是真正存在的实表。
- 使用视图,可以简化复杂查询逻辑。
- 使用视图,可以隐藏真实的表结构。起到安全的作用。
-
-
事务(TRANSACTION)(掌握)
什么是事务
事务是一组连续不可分割的SQL,要求要么全部成功要么全部撤销。
注意:
MySQL的表类型必须是InnoDB,才能支持事务。
事务特性
事务是数据库商用最基本最重要的特点。
事务是保证数据库数据完整性和安全性最重要的技术。
事务是要求一组连续的SQL语句要么全部成功执行,要么数据返回到开启事务前的状态。不允许部分SQL语句成功,部分不成功。
事务使用场景
- 操作步骤需要回滚的。比如,银行转账、购物下单等。
- 遇到异常情况,数据需要回滚的。比如,断电、磁盘坏死等。
事务的基本语法
语法如下;
start transaction;
insert 语句
delete 语句
update 语句
select 语句
commit;
事务要求满足4点(简称ACID)
1.原子性(Atomicity):事务中的多个操作,不可分割,要么都成功,要么都失败。
2.一致性(Consistency): 事务操作之后, 数据库所处的状态和业务规则是一致的; 比如a,b账户相互转账之后,总金额不变。
3.隔离性(Isolation):事务必须与其他事务进行的数据更改相隔离。这意味着没有其他操作可以改变中间态(没有提交的)的数据。为了避免中间态数据被更改,事务必须要么等待来自其他事务的更改被提交,要么只能查看到处于上一个提交状态的数据。
4.持久性(Durability):在事务完成,更改的数据将永久存在。
表的关系(套路)
一对一 :QQ与QQ空间 居民与身份证
多对一 :商品与商品类别 员工与部门 (一个员工是属于一个部门,一个部门可以包含多个员工)
一对多 :商品类别与商品 部门与员工
多对多 :老师与学生 一个老师会教多个学生,一个学生有多个老师教
一个车牌和一辆车:一个车牌对应一个车 一个车对应一个车牌 一对一的关系
做表设计时:首先分析对象之间的关系,然后去套用我们讲的三种关系的表的设计。

















 772
772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









