




 本文介绍使用Scrapy抓取企业名录网站约22万条企业信息,并保存到MySQL数据库的方法。具体步骤包括在item中定义抓取字段、定义spider抓取逻辑、在setting里打通保存管道、在pipelines中定义存储。还提供Python学习资料获取途径。
本文介绍使用Scrapy抓取企业名录网站约22万条企业信息,并保存到MySQL数据库的方法。具体步骤包括在item中定义抓取字段、定义spider抓取逻辑、在setting里打通保存管道、在pipelines中定义存储。还提供Python学习资料获取途径。
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
我们要用scrapy抓取企业名录网站的企业信息,并且保存在mysql数据库中,数据大概是22万条,我们用scrapy抓取。
第一步,现在item中定义好要抓取的字段

第二步,定义spider的抓取逻辑。
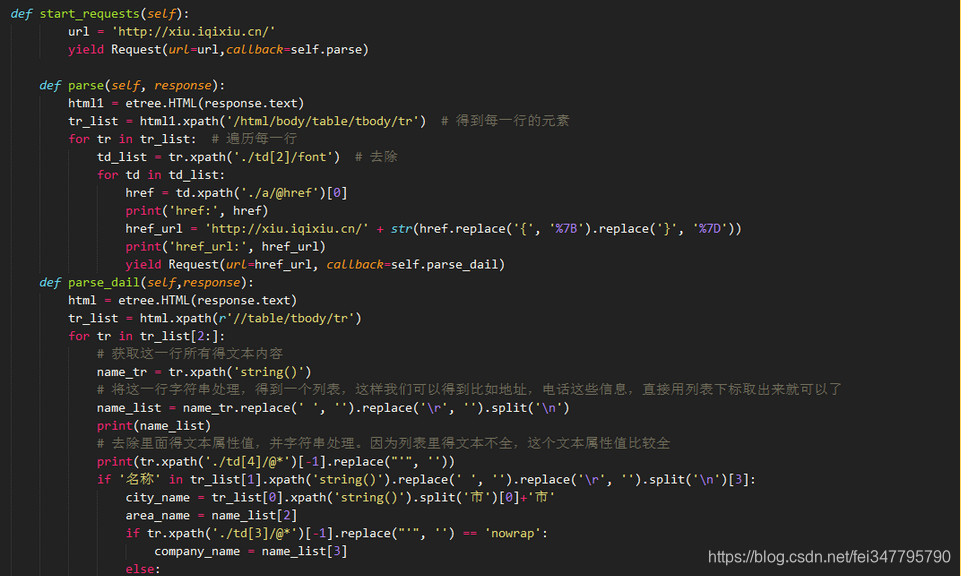
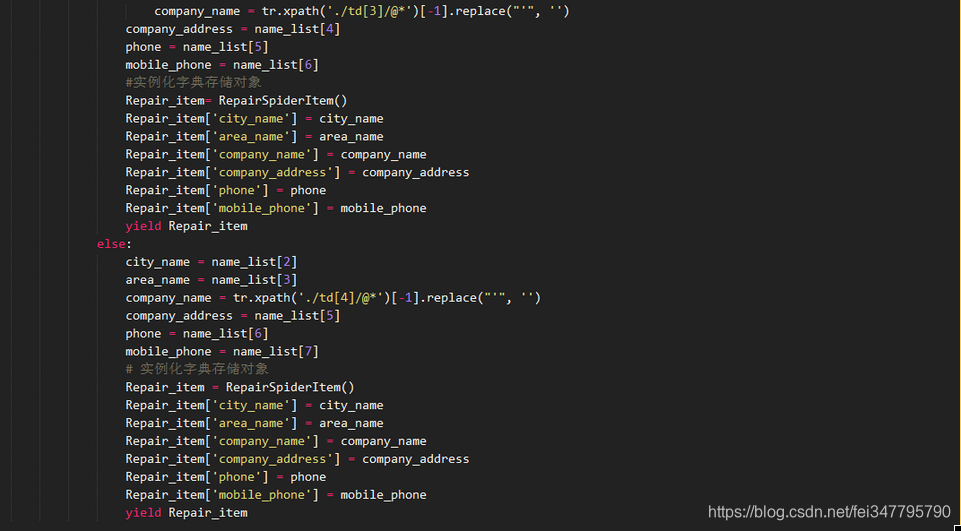
第三步,在setting里把保存的管道打通。也就是把默认的67,68行被注释的给解开
ITEM_PIPELINES = {
'repair_spider.pipelines.RepairSpiderPipeline': 300,
}
第四步,在pipelines中定义存储
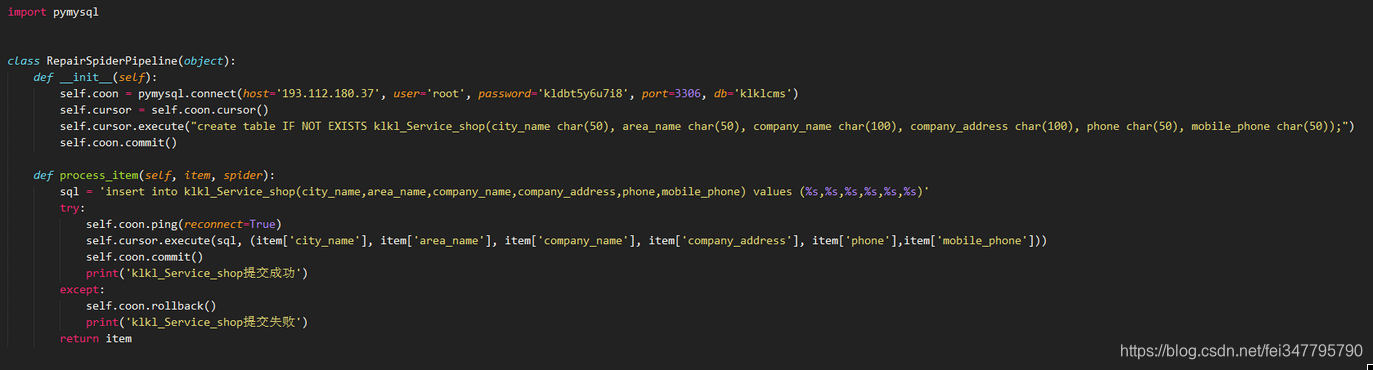

















 798
798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









