




 本文介绍了几种常用的HTML解析方法,包括使用lxml、BeautifulSoup、SGMLParser和HTMLParser等工具,适用于爬虫数据处理。重点对比了各种方法的特点与适用场景。
本文介绍了几种常用的HTML解析方法,包括使用lxml、BeautifulSoup、SGMLParser和HTMLParser等工具,适用于爬虫数据处理。重点对比了各种方法的特点与适用场景。
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
解析html是爬虫后的重要的一个处理数据的环节。一下记录解析html的几种方式。
先介绍基础的辅助函数,主要用于获取html并输入解析后的结束
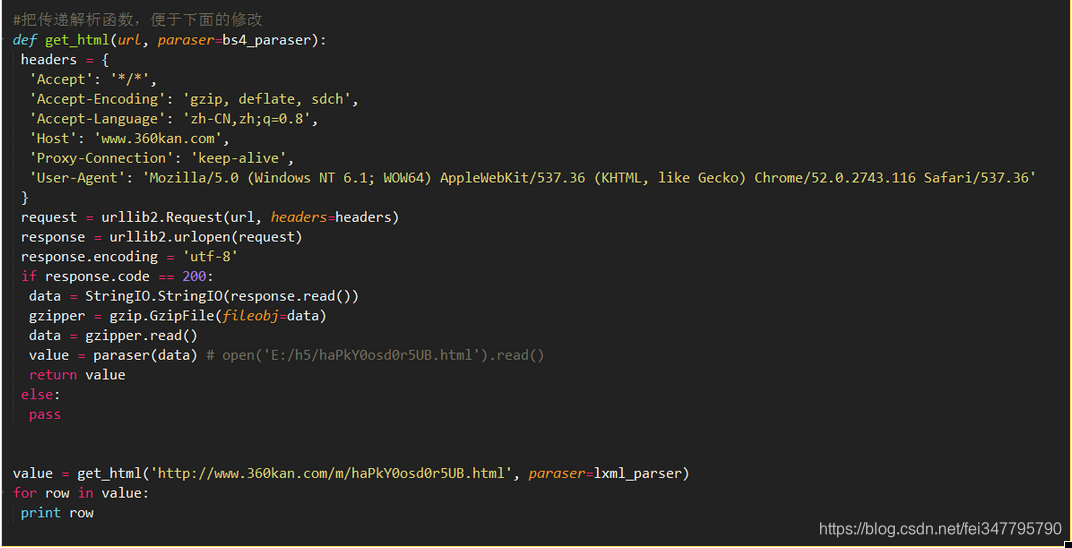
1,lxml.html的方式进行解析,
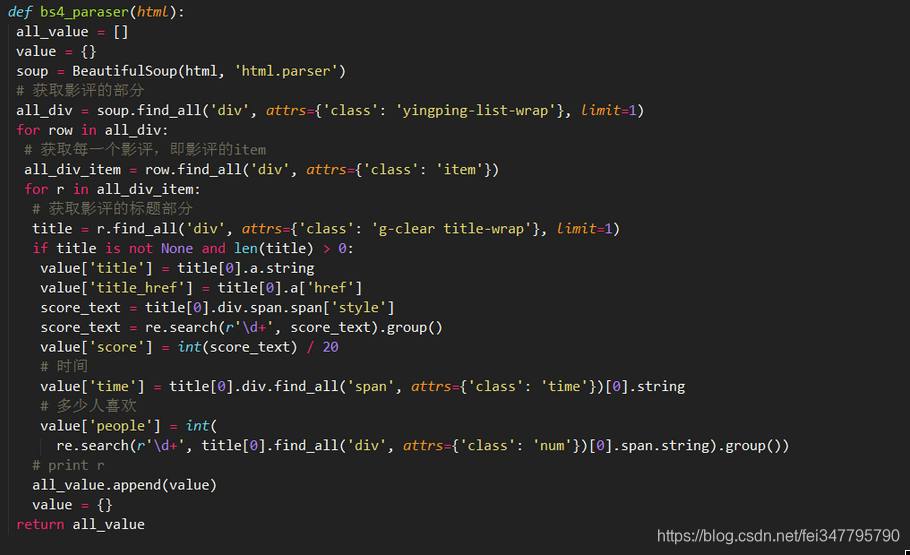
2,使用BeautifulSoup,不多说了,大家网上找资料看看
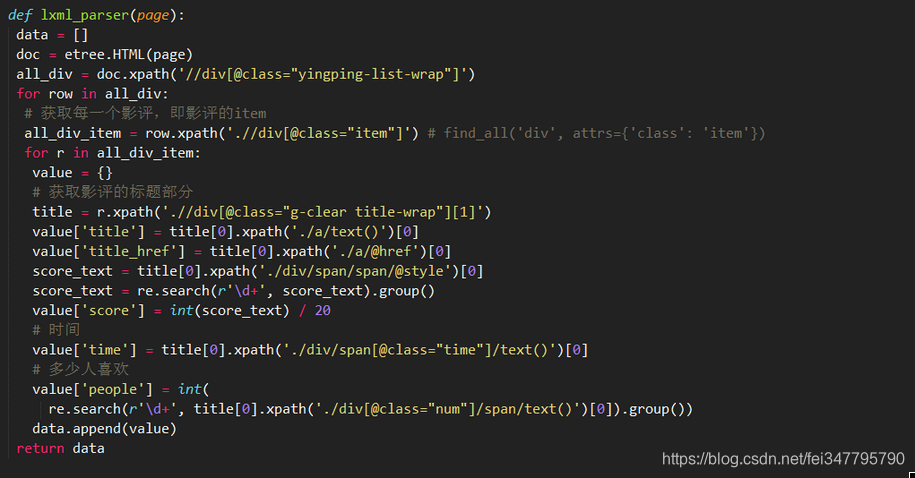
3,使用SGMLParser,主要是通过start、end tag的方式进行了,解析工程比较明朗,但是有点麻烦,而且该案例的场景不太适合该方法,(哈哈)
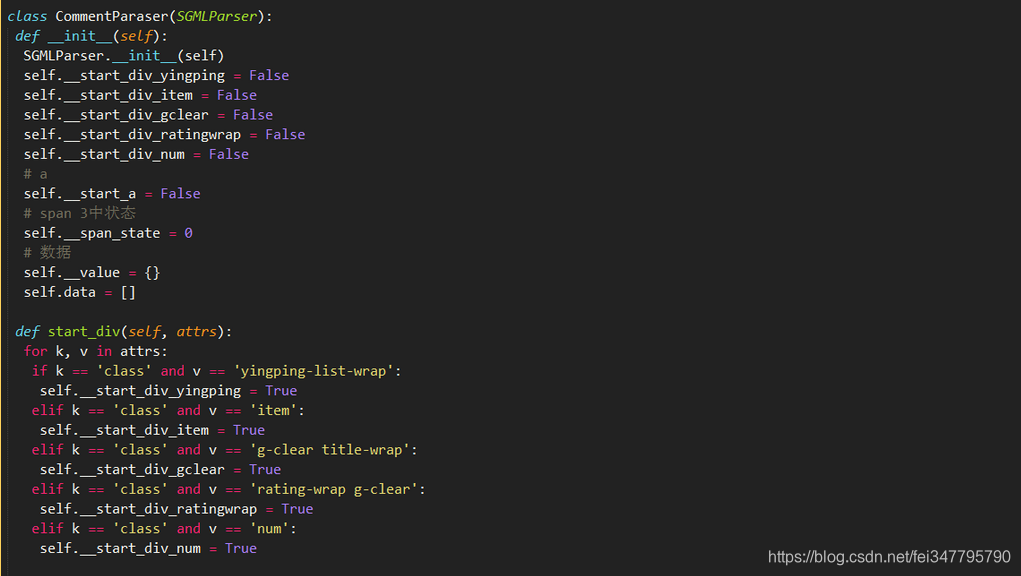
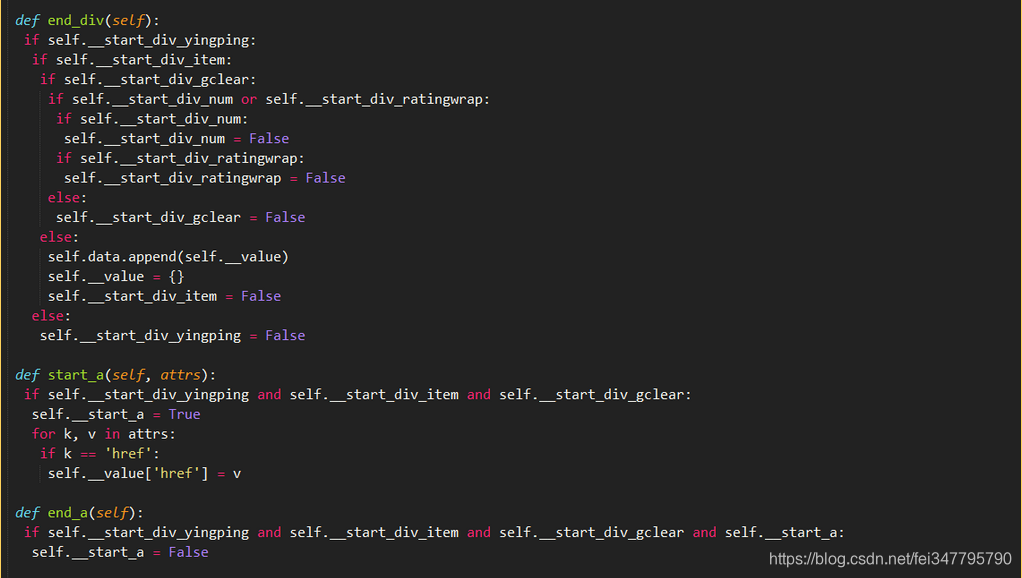
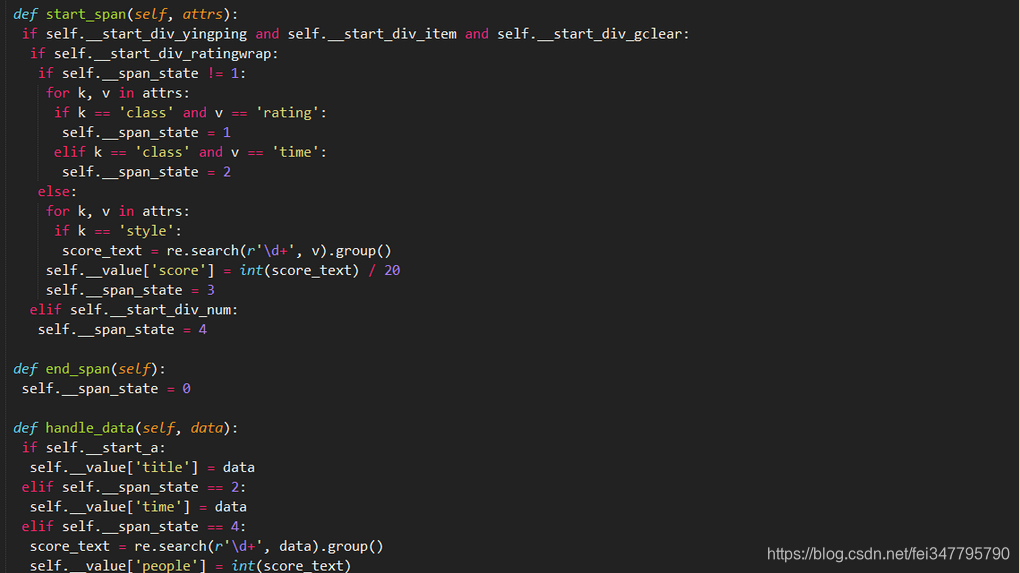
4,HTMLParaer,与3原理相识,就是调用的方法不太一样,基本上可以公用,

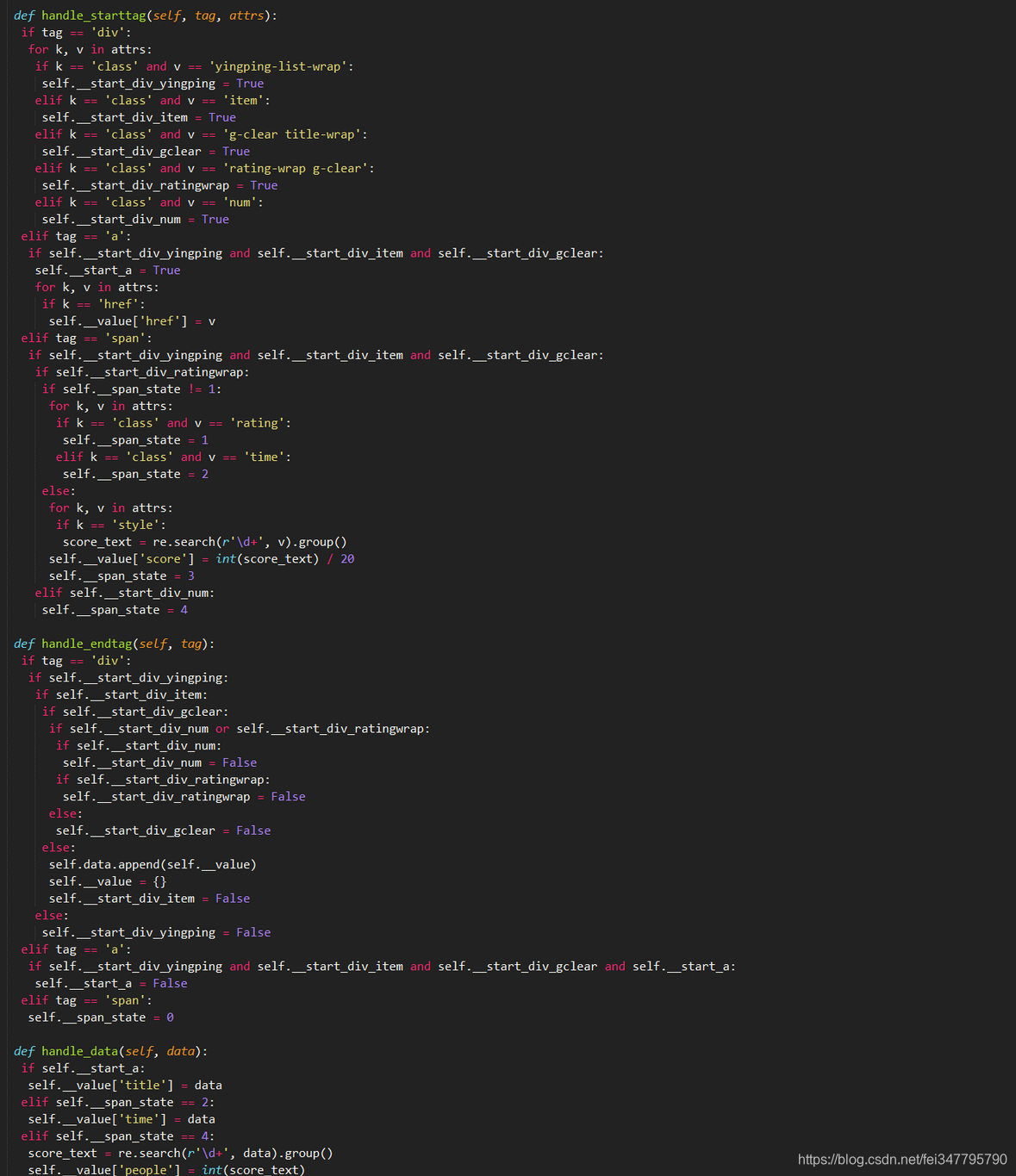

3,4对于该案例来说确实是不太适合,趁现在有空记录下来,功学习使用!

















 3921
3921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









