




 文章详细解释了中断在设备通信中的作用,特别是DMA操作中中断的使用,以及MSI和MSIX中断的核心结构。作者通过NVMe驱动中的request_irq函数和native_compose_msi_msg函数展示了中断处理流程,包括IRQ的分配、消息构建和向CPU传递的过程。
文章详细解释了中断在设备通信中的作用,特别是DMA操作中中断的使用,以及MSI和MSIX中断的核心结构。作者通过NVMe驱动中的request_irq函数和native_compose_msi_msg函数展示了中断处理流程,包括IRQ的分配、消息构建和向CPU传递的过程。
记录一下,如有不对感谢指正,本文章只关注于大部分情况,小部分例外不考虑。
中断是设备用来通知cpu的,一般来说,内核准备好一块空间,通知设备进行dma操作,接着cpu就去干其它事情去了,直到设备完成dma操作后,就会中断通知cpu,说我的工作完成了,别干其它事情了,这时候cpu就会转而处理,处理的函数是设备驱动注册的这么一个函数,例如在nvme驱动里面,有这么一个函数:
static int queue_request_irq(struct nvme_queue *nvmeq)
{
if (use_threaded_interrupts)
return request_threaded_irq(nvmeq_irq(nvmeq), nvme_irq_check,
nvme_irq, IRQF_SHARED, nvmeq->irqname, nvmeq);
else
return request_irq(nvmeq_irq(nvmeq), nvme_irq, IRQF_SHARED,
nvmeq->irqname, nvmeq);
}
其中 request_threaded_irq声明如下:
int request_threaded_irq(unsigned int irq, irq_handler_t handler,
irq_handler_t thread_fn, unsigned long irqflags,
const char *devname, void *dev_id)大体可以理解为,这个函数就把一个irq (int 整数) 和 handler , thread_fn关联起来了,handler 与 thread_fn 都是函数,为什么有两个,这个之后再说。
也就是对于cpu来说,它需要判断产生中断的是哪个irq,从而知道运行哪个处理函数,逻辑就是这么简单。
又绕回来的是,如果判断一个msix 中断对应的是哪个irq,先说结论,msix中断核心的内容就两个,address 和 data,这两个组成了一个叫做msg的结构体,代表一个msix中断。设备想产生中断,就往这个地址写这个数据,就可以了,这个address和data内容如下
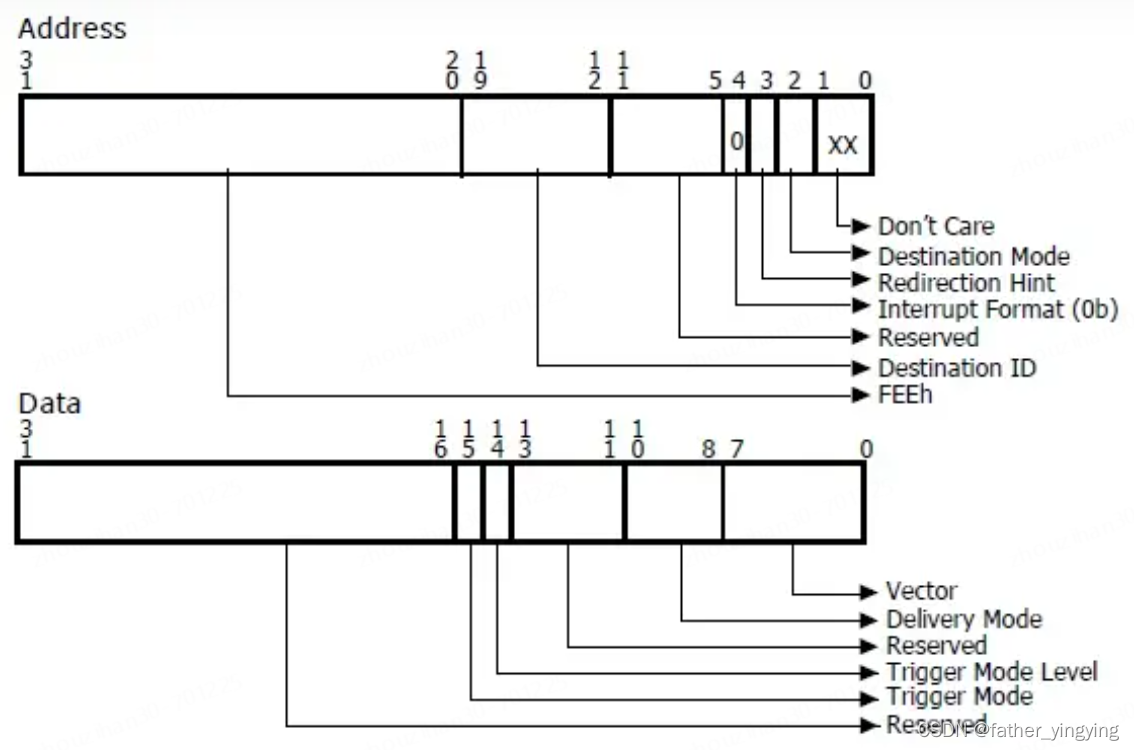
这时不得不说了,全都看不懂啊,还是看产生这些信息的函数最为合适:
void native_compose_msi_msg(struct pci_dev *pdev,
unsigned int irq, unsigned int dest,
struct msi_msg *msg, u8 hpet_id)
{
struct irq_cfg *cfg = irq_cfg(irq);
msg->address_hi = MSI_ADDR_BASE_HI;
if (x2apic_enabled())
msg->address_hi |= MSI_ADDR_EXT_DEST_ID(dest);
msg->address_lo =
MSI_ADDR_BASE_LO |
((apic->irq_dest_mode == 0) ?
MSI_ADDR_DEST_MODE_PHYSICAL:
MSI_ADDR_DEST_MODE_LOGICAL) |
((apic->irq_delivery_mode != dest_LowestPrio) ?
MSI_ADDR_REDIRECTION_CPU:
MSI_ADDR_REDIRECTION_LOWPRI) |
MSI_ADDR_DEST_ID(dest); //有apicid ,就有对应的地址!!!
msg->data =
MSI_DATA_TRIGGER_EDGE |
MSI_DATA_LEVEL_ASSERT |
((apic->irq_delivery_mode != dest_LowestPrio) ?
MSI_DATA_DELIVERY_FIXED:
MSI_DATA_DELIVERY_LOWPRI) |
MSI_DATA_VECTOR(cfg->vector);
}这样是不是清晰了很多,可以看出来,msg的address 里面核心内容就一个dest(对应图中的destination id), 而data里面核心内容就一个vector, 这俩还全是整数,接着就可以倒推这俩是怎么来的
先看 dest,不知大家有没有看到过 LAPIC (Local Advanced Programmable Interrupt Controller) 这个东西,简而言之就是一个cpu里面有一个,写msix中断其实就是往它身上写,至于怎么往它身上写,自然就是靠的这个dest值:
err = apic->cpu_mask_to_apicid_and(cfg->domain,
apic->target_cpus(), &dest);这个函数的逻辑,大体就是通过这个中断往哪个cpu上传,得到其对应的apic标识id,也就是dest,当产生msix中断时,根据msg中的address(核心内容是dest),就可以传到对应的lapic,也就是传到对应的cpu上去了。
一般中断,只需要通知到一个cpu就可以了!例如一台8核机器,运行cat /proc/interrupts

这里只截取了部分中断,这是一个nvme盘,共有8个io队列和1个ctl队列,8个io队列是均匀绑在8个cpu上的,这并不是巧合(有的地方为0,只是因为还没产生中断)
看一下nvme的驱动,处理中断的地方:(只看8个io队列就好了,ctl队列较为特殊)
static int nvme_setup_io_queues(struct nvme_dev *dev)
{
......
result = pci_alloc_irq_vectors_affinity(pdev, 1, nr_io_queues + 1,
PCI_IRQ_ALL_TYPES | PCI_IRQ_AFFINITY, &affd);
......
return nvme_create_io_queues(dev);
}其中在nvme_create_io_queues(dev);中有request irq的操作,也就是绑定irq和handle,但是在这之前需要先申请irq,因为irq自然不是自己随便设个值就能用的,是需要内核进行管理,也就是pci_alloc_irq_vectors_affinity要做的事情,这个函数做的事情有很多,大体上可以总结为,分配好irq, 每个irq对应一个msg,或者叫 entry ,比如申请了8个中断,就把这些msg信息一项一项写到pci设备对应的bar里面,这些信息的头一般叫做 msix table。
pci的bar又是啥,专业一点叫做基地址寄存器,pci设备一般最多有6个,每一个只是放着一个地址,而这个地址指向的又是设备专有的空间,所以一般说bar,就是在说这个空间。
普通设备的bar不大,除非是那种有显存的,例如显卡,它们的bar可以上百G,自然是对应着其显存,往那个bar里读写相当于就读写到显存身上去了,不过一般设备有一两M就够了。下图是一个nvme设备的具体信息,可以看到region 0 (bar 0) 才 16k
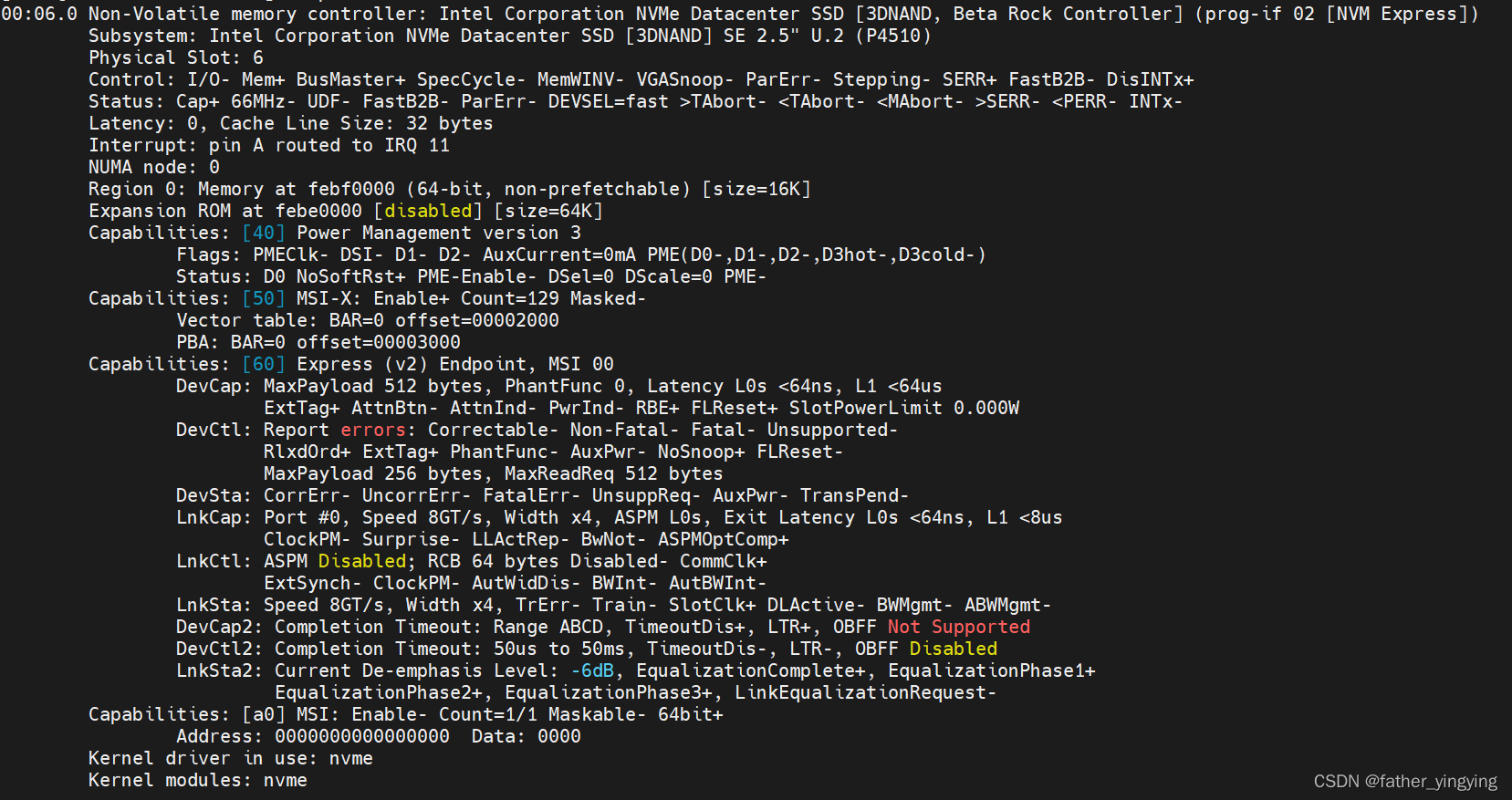
仔细看这里

这里面一个table,里面就放着一堆msg,即8个address 8个data(忘掉ctl queue),地址就在bar 0的offset 00002000,内核需要访问时,就通过bar里面的地址,+ 00002000,就知道table在哪里了!
上面大体说完了dest,接着还有vector
err = assign_irq_vector(irq, cfg, apic->target_cpus());
......
for_each_cpu_and(new_cpu, tmp_mask, cpu_online_mask)
per_cpu(vector_irq, new_cpu)[vector] = irq; //通过vector 找到对应的irq核心内容就在这里,per_cpu代表着这个数据每个cpu一个,换句话说,每个cpu都有一份vector到irq的索引,这就是为什么vector只有8位,256个可能,但是msix中断却可以有上千个。因为一个msix中断是靠着cpu(dest) 和vector来表示的!
简单捋一下,设备中断处理包含申请中断号(关联irq和 msg),以及申请中断(关联irq和handle),msg是在第一步处理的,下面的文章会更详细的讲解第一步的处理函数pci_alloc_irq_vectors_affinity

















 42
42

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









