







 本文精选了多道经典的编程题目并提供了详细的Python及C++解答方案,涵盖了整数转罗马数字、电话号码的字母组合、有效的数独判断、字母异位词分组等典型算法问题。
本文精选了多道经典的编程题目并提供了详细的Python及C++解答方案,涵盖了整数转罗马数字、电话号码的字母组合、有效的数独判断、字母异位词分组等典型算法问题。
1.整数转罗马数字

python:
class Solution:
def intToRoman(self, num: int) -> str:
dict_ = {1000:'M', 900:'CM', 500:'D', 400:'CD', 100:'C', 90:'XC', 50:'L', 40:'XL', 10:'X', 9:'IX', 5:'V', 4:'IV', 1:'I'}
res = ''
for key in dict_:
count = num // key
res += count * dict_[key]
num %= key
return resc++:
class Solution {
public:
string intToRoman(int num) {
int value[] = {1000, 900, 500, 400, 100, 90, 50, 40, 10, 9, 5, 4, 1};
string str_[] = {"M", "CM", "D", "CD", "C", "XC", "L", "XL", "X", "IX", "V", "IV", "I"};
string res;
for(int i = 0; i < 13; i++){
while(num >= value[i]){
num -= value[i];
res += str_[i];
}
}
return res;
}
};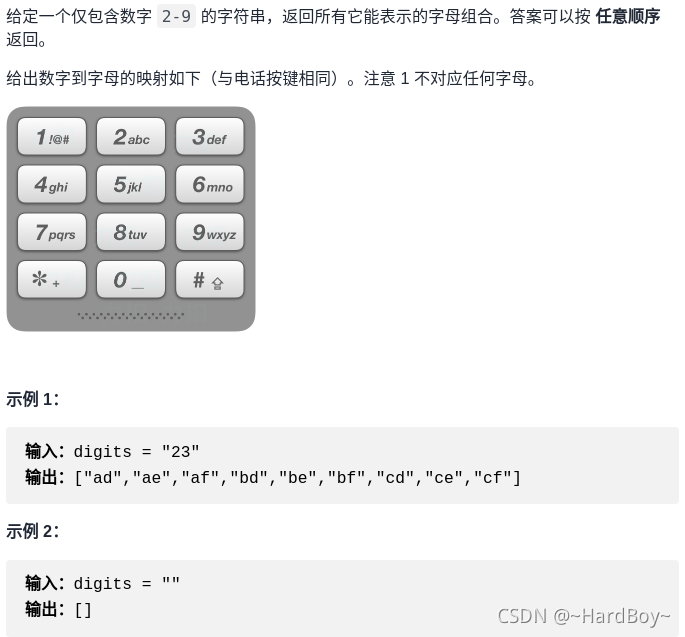
python:
class Solution:
def help(self, digits, track):
if len(digits)==0:
self.res.append(''.join(track))
return
for letter in self.dict_[digits[0]]:
# store = track.copy()
track.append(letter)
self.help(digits[1:], track)
# track.pop()
track = store
def letterCombinations(self, digits: str) -> List[str]:
if len(digits)==0:
return []
self.dict_={"2":"abc","3":"def","4":"ghi","5":"jkl","6":"mno","7":"pqrs","8":"tuv","9":"wxyz"}
self.res = []
self.help(digits, [])
return self.resc++:
class Solution {
public:
vector<string> res;
// unordered_map<char, string> phoneMap;
void help(string digits, vector<char> track, unordered_map<char, string> phoneMap){
if(digits.empty()){
string str(track.begin(), track.end());
res.push_back(str);
}
for(int i=0; i < phoneMap[digits[0]].size(); i++){
track.push_back(phoneMap[digits[0]][i]);
help(digits.substr(1, digits.size() - 1), track, phoneMap);
track.pop_back();
}
}
vector<string> letterCombinations(string digits) {
if (digits.empty()) {
return res;
}
unordered_map<char, string> phoneMap{
{'2', "abc"},
{'3', "def"},
{'4', "ghi"},
{'5', "jkl"},
{'6', "mno"},
{'7', "pqrs"},
{'8', "tuv"},
{'9', "wxyz"}
};
vector<char> track;
help(digits, track, phoneMap);
return res;
}
};3.有效的数独

思路用三个hash 记录即可
python:
class Solution:
def isValidSudoku(self, board: List[List[str]]) -> bool:
rows = [{i:0} for i in range(9)]
# print(rows)
cols = [{i:0} for i in range(9)]
boxs = [{i:0} for i in range(9)]
for i in range(9):
for j in range(9):
box_index = (i // 3) * 3 + j // 3
if board[i][j] != '.':
num = int(board[i][j])
rows[i][num] = rows[i].get(num, 0) + 1
cols[j][num] = cols[j].get(num, 0) + 1
boxs[box_index][num] = boxs[box_index].get(num, 0) + 1
# print(rows)
# print('==i', i)
# print('==num', num)
if rows[i][num] > 1 or cols[j][num] > 1 or boxs[box_index][num] > 1:
return False
return Truec++:
class Solution {
public:
bool isValidSudoku(vector<vector<char>>& board) {
vector<vector<int>> rows(9, vector<int>(9, 0));
vector<vector<int>> cols(9, vector<int>(9, 0));
vector<vector<int>> boxs(9, vector<int>(9, 0));
for(int i = 0; i < 9; i++){
for(int j = 0; j < 9; j++){
if (board[i][j] == '.') continue;
int num = board[i][j] - '1';
int box_index = (i / 3) * 3 + j / 3;
rows[i][num]++;
cols[j][num]++;
boxs[box_index][num]++;
if(rows[i][num] > 1 || cols[j][num] > 1 || boxs[box_index][num] > 1){
return false;
}
}
}
return true;
}
};4.字母异位词分组

python:
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
dict_={}
for i in range(len(strs)):
str_ = ''.join(sorted(strs[i]))
if str_ in dict_:
dict_[str_].append(strs[i])
else:
dict_[str_] = [strs[i]]
# print(dict_.values())
return list(dict_.values())c++:
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
vector<vector<string>> result;
map<string, vector<string>> dict_;
for(int i = 0; i < strs.size(); i++){
string s = strs[i];
sort(s.begin(), s.end());
dict_[s].push_back(strs[i]);
}
map<string, vector<string>> ::iterator it;
for(it = dict_.begin(); it != dict_.end(); it++){
result.push_back(it->second);
}
// for(auto x:dict_){
// result.push_back(x.second);
// }
return result;
}
};5.矩阵置零
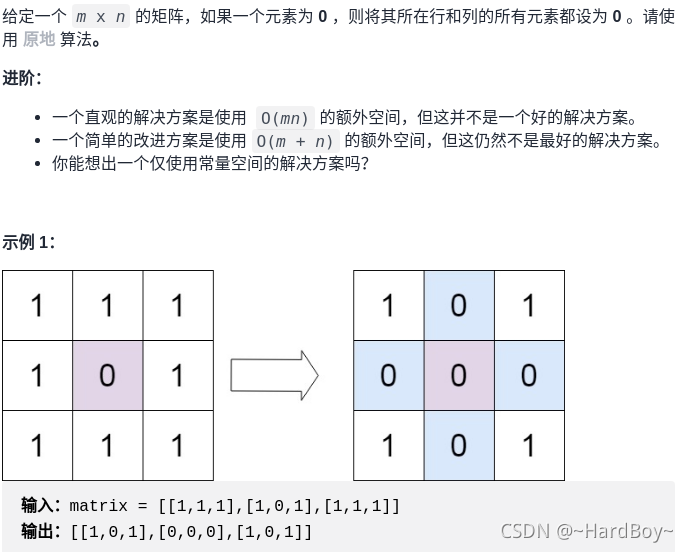
python:
class Solution:
def setZeroes(self, matrix: List[List[int]]) -> None:
"""
Do not return anything, modify matrix in-place instead.
"""
m, n = len(matrix), len(matrix[0])
row, col = [False] * m, [False] * n
for i in range(m):
for j in range(n):
if matrix[i][j] == 0:
row[i] = col[j] = True
for i in range(m):
for j in range(n):
if row[i] or col[j]:
matrix[i][j] = 0c++:
class Solution {
public:
void setZeroes(vector<vector<int>>& matrix) {
int m = matrix.size();
int n = matrix[0].size();
vector<int> row(m, 0), col(n, 0);
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (!matrix[i][j]) {
row[i] = col[j] = 1;
}
}
}
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (row[i] || col[j]) {
matrix[i][j] = 0;
}
}
}
}
};
6.最小覆盖子串

思路:滑动窗口
python:
class Solution:
def minWindow(self, s: str, t: str) -> str:
dict_ = {}
for i in t:
dict_[i] = dict_.get(i, 0)+1
# print('dict_:', dict_)
n = len(s)
left, right = 0,0
remain = 0
res = ''
minlen = float('inf')
while right < n:#向右边拓展
if s[right] in dict_:
if dict_[s[right]]>0:#大于0这个时候加才有效否则是重复字符
remain+=1
dict_[s[right]]-=1
while remain == len(t):#left 要拓展了 也就是左边要压缩
if (right - left) < minlen:
minlen = right-left
res = s[left:right+1]
# print('==res:', res)
left+=1
if s[left-1] in dict_:#注意这里left已经加1了 要用前一个字符也就是s[left-1]
dict_[s[left - 1]] += 1
if dict_[s[left-1]]>0:#大于0这个时候减去才有效否则是重复字符
remain -= 1
right += 1#放后面进行向右拓展
# print('==res:', res)
return res7.单词接龙 II

思路:构建图 然后bfs
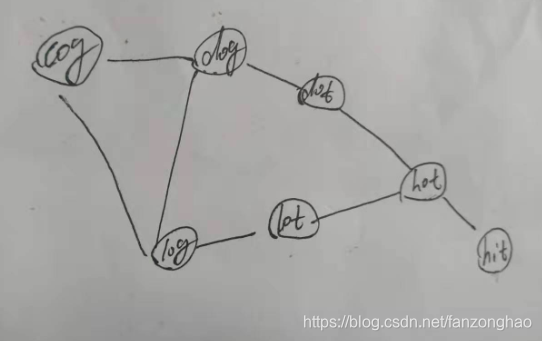
python:
class Solution:
def findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]:
cost = {}
for word in wordList:
cost[word] = float("inf")
cost[beginWord] = 0
# print('==cost:', cost)
# neighbors = collections.defaultdict(list)
neighbors = {}
ans = []
#构建图
for word in wordList:
for i in range(len(word)):
key = word[:i] + "*" + word[i + 1:]
if key not in neighbors:
neighbors[key] = []
neighbors[key].append(word)
else:
neighbors[key].append(word)
# print('==neighbors:', neighbors)
q = [[beginWord]]
# print('====q:', q)
#bfs
while q:
path = q.pop(0)
# print('===path:', path)
cur = path[-1]
if cur == endWord:
ans.append(path.copy())
else:
for i in range(len(cur)):
new_key = cur[:i] + "*" + cur[i + 1:]
if new_key not in neighbors:
continue
for neighbor in neighbors[new_key]:
# print('==cost[cur] + 1, cost[neighbor]:', cost[cur] + 1, cost[neighbor])
if cost[cur] + 1 <= cost[neighbor]:
q.append(path + [neighbor])
cost[neighbor] = cost[cur] + 1
# print('==ans:', ans)
# print(cost)
return ans8.最长连续序列

python:
class Solution:
def longestConsecutive(self, nums: List[int]) -> int:
temp = 1
long_length = 0
nums = set(nums)
for num in nums:
if num - 1 in nums:
continue
while num + 1 in nums:
temp += 1
num += 1
long_length = max(long_length, temp)
temp = 1
return long_lengthc++:
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
unordered_set<int> unums;
for(int num:nums){
unums.insert(num);
}
int LongLength = 0, temp = 1;
for(int num: unums){
if(unums.count(num - 1)){
continue;
}
while(unums.count(num + 1)){
temp++;
num++;
}
LongLength = max(LongLength, temp);
temp = 1;
}
return LongLength;
}
};9-1. 单词拆分

思路1:动态规划
#动态规划 dp[i]表示 s 的前 i 位是否可以用 wordDict 中的单词表示,
#
class Solution:
def wordBreak(self, s, wordDict):
n = len(s)
dp = [False] * (n + 1)
dp[0] = True
for i in range(n):
for j in range(i+1, n+1):
if dp[i] and (s[i:j] in wordDict):
dp[j] = True
print('==dp:', dp)
return dp[-1]
s = "leetcode"
wordDict = ["leet", "code"]
sol = Solution()
res= sol.wordBreak(s, wordDict)
print('==res:', res)
c++实现:
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict) {
int n = s.size();
unordered_set<string> wordDictSet;
for (auto word: wordDict) {
wordDictSet.insert(word);
}
vector<bool> dp(n+1, false);
dp[0] = true;
for(int i = 0; i < n; i++){
for(int j = i+1; j < n+1; j++){
if(dp[i] && wordDictSet.find(s.substr(i, j - i)) != wordDictSet.end()) {
// cout<<"s.substr(i, j - i):"<<s.substr(i, j - i)<<endl;
dp[j] = true;
}
}
}
return dp[n];
}
};思路2:回溯加缓存
#递归 lru_cache用于缓存 将数据缓存下来 加快后续的数据获取 相同参数调用时直接返回上一次的结果
import functools
class Solution:
@functools.lru_cache()
def helper(self, s):
if len(s) == 0:
return True
res = False
for i in range(1, len(s)+1):
if s[:i] in self.wordDict:
res = self.helper(s[i:]) or res
return res
def wordBreak(self, s, wordDict):
self.wordDict = wordDict
return self.helper(s)
s = "leetcode"
wordDict = ["leet", "code"]
# s = "aaaaaaa"
# wordDict = ["aaaa", "aaa"]
# s= "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaab"
# wordDict = ["a","aa","aaa","aaaa","aaaaa","aaaaaa","aaaaaaa","aaaaaaaa","aaaaaaaaa","aaaaaaaaaa"]
sol = Solution()
res= sol.wordBreak(s, wordDict)
print('==res:', res)

思路:递归
class Solution:
def helper(self, s, wordDict, memo):
if s in memo:#递归终止条件
return memo[s]
if s=='':#递归终止条件
return []
res = []
for word in wordDict:
if not s.startswith(word):
continue
if len(word)==len(s):#匹配上刚好相等
res.append(word)
else:#匹配上 但是字符还没到最后
rest = self.helper(s[len(word):], wordDict, memo)
for tmp in rest:
tmp = word+ " "+ tmp
res.append(tmp)
print('==res:', res)
print('==memo:', memo)
memo[s] = res
return res
def wordBreak(self, s, wordDict):
if s=='':
return []
return self.helper(s, wordDict, memo={})
s = "catsanddog"
wordDict = ["and", "cat", "cats", "sand", "dog"]
# s = "cat"
# wordDict = ["cat"]
sol = Solution()
res = sol.wordBreak(s, wordDict)
print(res)
c++:
class Solution {
public:
vector<string> helper(string s, vector<string>& wordDict){
vector<string> res;
for(int i = 0; i < wordDict.size(); i++){
string word = wordDict[i];
if(s.find(word) != 0){
continue;
}
if(word == s){
res.push_back(word);
}
else{
vector<string> temp;
temp = helper(s.substr(word.size(), s.size()), wordDict);
for(string temp_:temp){
res.push_back(word + " "+temp_);
}
}
}
return res;
}
vector<string> wordBreak(string s, vector<string>& wordDict) {
if (s.size()==0){
return {};
}
return helper(s, wordDict);
}
};
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
def hasCycle(self, head: ListNode) -> bool:
#快慢指针 人追人
slow,fast = head,head
while fast and fast.next:
fast = fast.next.next
slow = slow.next
if slow==fast:
return True
return Falsec++实现:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
bool hasCycle(ListNode *head) {
ListNode* slow = head;
ListNode* fast = head;
while(fast && fast->next){
slow = slow->next;
fast = fast->next->next;
if(slow == fast){
return true;
}
}
return false;
}
};10-2.给定一个有环链表,实现一个算法返回环路的开头节点。

假设有两个指针,分别为快慢指针fast和slow, 快指针每次走两步,慢指针每次前进一步,如果有环则两个指针必定相遇;
反证法:假设快指针真的 越过 了慢指针,且快指针处于位置 i+1,而慢指针处于位置 i,那么在前一步,快指针处于位置 i-1,慢指针也处于位置 i-1,它们相遇了。
A:链表起点
B:环起点
C:相遇点
X:环起点到相遇点距离
Y:链表起点到环起点距离
R:环的长度
S:第一次相遇时走过的路程
1.慢指针slow第一次相遇走过的路程 S1 = Y + X;(11)
快指针fast第一次相遇走过的路程 S2=2S1 = Y + X + NR;(2)
说明:快指针的速度是慢指针的两倍,相同时间内路程应该是慢指针的两倍,Y + X + NR是因为快指针可能经过N圈后两者才相遇;
把(1)式代入(2)式得:Y = NR -X;
2..在将慢指针回到A点,满指针和快指针同时走,在B点相遇,此处就是环节点.
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
def detectCycle(self, head: ListNode) -> ListNode:
slow = head
fast = head;
while fast:
if fast and fast.next:
slow = slow.next
fast = fast.next.next
else:
return None
if slow==fast:
break
if fast ==None or fast.next==None:
return None
slow= head
while slow!=fast:
slow = slow.next
fast = fast.next
return slowc++实现:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
ListNode* slow = head;
ListNode* fast = head;
while(fast){
if(fast && fast->next){
slow = slow->next;
fast = fast->next->next;
}
else{
return NULL;
}
if(slow==fast){
break;
}
}
if(!fast || !fast->next){
return NULL;
}
slow = head;
while(slow!=fast){
slow = slow->next;
fast = fast->next;
}
return slow;
}
};
python:
class Solution:
def findRepeatedDnaSequences(self, s: str) -> List[str]:
length = 10
res = list()
temp = dict()
for i in range(len(s) - length + 1):
temp[s[i:i+length]] = temp.get(s[i:i+length], 0) + 1
if temp[s[i:i+length]] == 2:
res.append(s[i:i+length])
return resc++:
class Solution {
public:
vector<string> findRepeatedDnaSequences(string s) {
if(s.size() < 10){
return {};
}
vector<string> res;
map<string, int> temp;
int length=10;
for(size_t i = 0; i < s.size() - length + 1; i++){
string str_ = s.substr(i, length);
temp[str_]++;
// cout<<str_<<endl;
// cout<<temp[str_]<<endl;
if(temp[str_] == 2){
res.push_back(str_);
}
}
return res;
}
};12.快乐数

python:
class Solution:
def nextN(self, n):
sum_ = 0
while n > 0:
digit = n % 10
n = n//10
sum_ += digit**2
return sum_
def isHappy(self, n: int) -> bool:
visit = set()
while n!=1 and n not in visit:
visit.add(n)
n = self.nextN(n)
return n==1c++
class Solution {
public:
int nextN(int n){
int sum_ = 0;
while(n > 0){
sum_ += (n % 10) * (n % 10);
n /= 10;
}
return sum_;
}
bool isHappy(int n) {
unordered_set<int> visit;
while(n != 1 && visit.find(n) == visit.end()){
visit.insert(n);
n = nextN(n);
}
// cout<<n;
return n == 1;
}
};
13.同构字符串

python:
class Solution:
def isIsomorphic(self, s: str, t: str) -> bool:
if len(s) != len(t):
return False
dict_ = dict()
for i in range(len(s)):
if s[i] in dict_:
if dict_[s[i]] != t[i]:
return False
else:
if t[i] in dict_.values():
return False
dict_[s[i]] = t[i]
return Trueclass Solution:
def isIsomorphic(self, s: str, t: str) -> bool:
if len(s) != len(t):
return False
dict_1 = dict()
dict_2 = dict()
for i in range(len(s)):
if (s[i] in dict_1 and dict_1[s[i]] != t[i]) or (t[i] in dict_2 and dict_2[t[i]] != s[i]):
return False
dict_1[s[i]] = t[i]
dict_2[t[i]] = s[i]
return Truec++:
class Solution {
public:
bool isIsomorphic(string s, string t) {
map<char, char> s2t;
map<char, char> t2s;
for (int i = 0; i < s.size(); ++i) {
char x = s[i], y = t[i];
if ((s2t.count(x) && s2t[x] != y) || (t2s.count(y) && t2s[y] != x)) {
return false;
}
s2t[x] = y;
t2s[y] = x;
}
return true;
}
};14.求众数 II

python:
class Solution:
def majorityElement(self, nums: List[int]) -> List[int]:
length = len(nums) // 3 + 1
dict_ = {}
for num in nums:
dict_[num] = dict_.get(num, 0) + 1
res = []
for key in dict_:
if dict_[key] >= length:
res.append(key)
return resc++:
class Solution {
public:
vector<int> majorityElement(vector<int>& nums) {
map<int, int> dict_;
vector<int> res;
int length = nums.size()/3 + 1;
for(int &num:nums){
dict_[num]++;
}
for(auto &iter:dict_){
if(iter.second >= length){
res.push_back(iter.first);
}
}
return res;
}
};15.丑数 II

python:
class Solution:
def nthUglyNumber(self, n: int) -> int:
dp = [1]*n
index_two = 0
index_three = 0
index_five = 0
for i in range(1, n):
two = dp[index_two]*2
three = dp[index_three]*3
five = dp[index_five]*5
dp[i] = min(two, three, five)
if dp[i] == two:
index_two += 1
if dp[i] == three:
index_three += 1
if dp[i] == five:
index_five += 1
# print(dp)
return dp[-1]c++:
class Solution {
public:
int nthUglyNumber(int n) {
vector<int>dp(n, 1);
int index_two = 0, index_three = 0, index_five = 0;
for(int i = 1; i < n; i++){
int two = dp[index_two]*2;
int three = dp[index_three]*3;
int five = dp[index_five]*5;
dp[i] = min(min(three, two), five);
if(two == dp[i]){
index_two++;
}
if(three == dp[i]){
index_three++;
}
if(five == dp[i]){
index_five++;
}
}
return dp[n-1];
}
};

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









