









0.安装
1.安装tensorrt
从官网下载.deb包,要注意的是cuda版本
sudo dpkg -i nv-tensorrt-repo-ubuntu1604-cuda10.0-trt7.0.0.11-ga-20191216_1-1_amd64.deb
sudo apt update
sudo apt install tensorrtEngine plan 的兼容性依赖于GPU的compute capability 和 TensorRT 版本, 不依赖于CUDA和CUDNN版本.
2.安装opencv
sudo apt-get update
sudo apt install libopencv-devapt-get install tensorrt报错
https://github.com/NVIDIA/TensorRT/issues/792
tensorrt : Depends: libnvinfer7 (= 7.0.0-1+cuda10.0) but 7.2.2-1+cuda11.1 is to be installed
Depends: libnvinfer-plugin7 (= 7.0.0-1+cuda10.0) but 7.2.2-1+cuda11.1 is to be installed
Depends: libnvparsers7 (= 7.0.0-1+cuda10.0) but 7.2.2-1+cuda11.1 is to be installed
Depends: libnvonnxparsers7 (= 7.0.0-1+cuda10.0) but 7.2.2-1+cuda11.1 is to be installed
Depends: libnvinfer-bin (= 7.0.0-1+cuda10.0) but it is not going to be installed
Depends: libnvinfer-dev (= 7.0.0-1+cuda10.0) but 7.2.2-1+cuda11.1 is to be installed
Depends: libnvinfer-plugin-dev (= 7.0.0-1+cuda10.0) but 7.2.2-1+cuda11.1 is to be installed
Depends: libnvparsers-dev (= 7.0.0-1+cuda10.0) but 7.2.2-1+cuda11.1 is to be installed
Depends: libnvonnxparsers-dev (= 7.0.0-1+cuda10.0) but 7.2.2-1+cuda11.1 is to be installed
Depends: libnvinfer-samples (= 7.0.0-1+cuda10.0) but it is not going to be installed
Depends: libnvinfer-doc (= 7.0.0-1+cuda10.0) but it is not going to be installed

mv /etc/apt/sources.list.d/nvidia-ml.list /etc/apt/sources.list.d/nvidia-ml.list.bak
在apt-get install tensorrt 即可
1.优化流程:
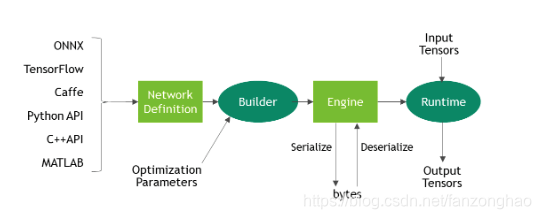
TensorRT总共有5个阶段:创建网络、构建推理Engine、序列化引擎、反序列化引擎以及执行推理Engine。
其中第1,2,3大概就是c++api写的网络结构或者其他第三方格式,经过NetworkDefinition进行定义,采用builder加载模型权重,进行一些参数的优化,然后再用engine序列化成“Plan”(流图),其不仅保存了计算时所需的网络weights也保存了Kernel执行的调度流程。。
而4,5就是推理:采用engine反序列化,创建运行环境,在进行推理即可。
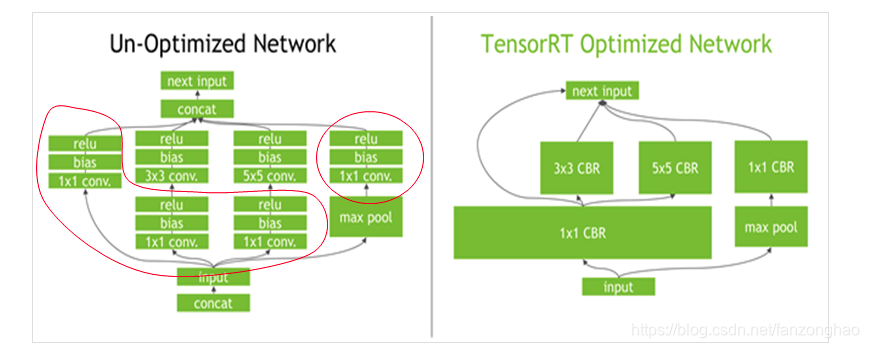
可看出TensorRT在获得网络计算流图后会针对计算流图进行优化.
深度学习框架在做推理时,会对每一层调用多个/次功能函数。而由于这样的操作都是在GPU上运行的,从而会带来多次的CUDA Kernel launch过程。相较于Kernel launch以及每层tensor data读取来说,kernel的计算是更快更轻量的,从而使得这个程序受限于显存带宽并损害了GPU利用率。
TensorRT通过以下三种方式来解决这个问题:
-
Kernel纵向融合:通过融合相同顺序的操作来减少Kernel Launch的消耗以及避免层之间的显存读写操作。如上图所示,卷积、Bias和Relu层可以融合成一个Kernel,这里称之为CBR。
-
Kernel横向融合:TensorRT会去挖掘输入数据且filter大小相同但weights不同的层,对于这些层不是使用三个不同的Kernel而是使用一个Kernel来提高效率,如上图中超宽的1x1 CBR所示,把结构相同但权重不同的层合并成更宽的层,从而减少cuda核心的使用.。
-
消除concatenation层,通过预分配输出缓存以及跳跃式的写入方式来避免这次转换。
通过这样的优化,TensorRT可以获得更小、更快、更高效的计算流图,其拥有更少层网络结构以及更少Kernel Launch次数。下表列出了常见几个网络在TensorRT优化后的网络层数量,很明显的看到TensorRT可以有效的优化网络结构、减少网络层数从而带来性能的提升。
2.torch版lenet转trt
2.1 torch版代码:
lenet.py
# coding:utf-8
import torch
from torch import nn
from torch.nn import functional as F
class Lenet5(nn.Module):
"""
for cifar10 dataset.
"""
def __init__(self):
super(Lenet5, self).__init__()
self.conv1 = nn.Conv2d(1, 6, kernel_size=5, stride=1, padding=0)
self.pool1 = nn.AvgPool2d(kernel_size=2, stride=2, padding=0)
self.conv2 = nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# print('input: ', x.shape)
x = F.relu(self.conv1(x))
# print('conv1', x.shape)
x = self.pool1(x)
# print('pool1: ', x.shape)
x = F.relu(self.conv2(x))
# print('conv2', x.shape)
x = self.pool1(x)
# print('pool2', x.shape)
x = x.view(x.size(0), -1)
# print('view: ', x.shape)
x = F.relu(self.fc1(x))
# print('fc1: ', x.shape)
x = F.relu(self.fc2(x))
x = F.softmax(self.fc3(x), dim=1)
return x
def main():
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
print('cuda device count: ', torch.cuda.device_count())
torch.manual_seed(1234)
net = Lenet5()
net = net.to('cuda:0')
net.eval()
import time
st_time = time.time()
nums = 10000
for i in range(nums):
tmp = torch.ones(1, 1, 32, 32).to('cuda:0')
out = net(tmp)
# print('lenet out shape:', out.shape)
print('lenet out:', out)
end_time = time.time()
print('==cost time{}'.format((end_time - st_time)))
torch.save(net, "lenet5.pth")
if __name__ == '__main__':
main()
将模型权重存储为.pth,并测试时间为:

2.2.pth存储为.onnx
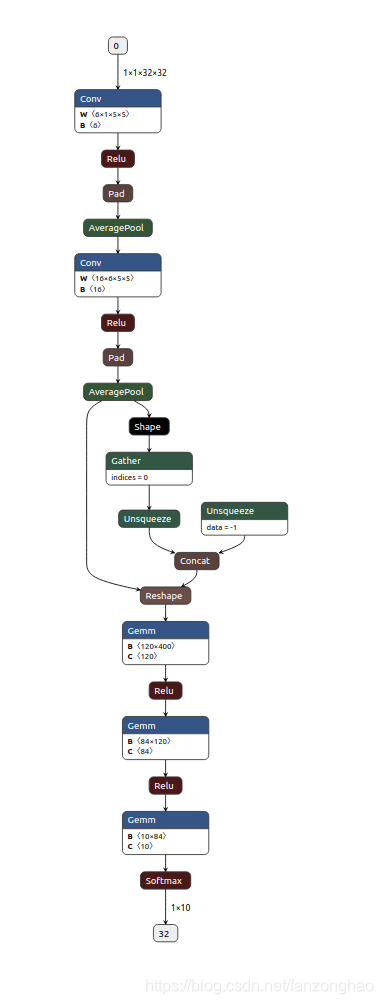
为了方便查看网络结构
# coding:utf-8
import torch
from torch import nn
from torch.nn import functional as F
class Lenet5(nn.Module):
"""
for cifar10 dataset.
"""
def __init__(self):
super(Lenet5, self).__init__()
self.conv1 = nn.Conv2d(1, 6, kernel_size=5, stride=1, padding=0)
self.pool1 = nn.AvgPool2d(kernel_size=2, stride=2, padding=0)
self.conv2 = nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# print('input: ', x.shape)
x = F.relu(self.conv1(x))
# print('conv1', x.shape)
x = self.pool1(x)
# print('pool1: ', x.shape)
x = F.relu(self.conv2(x))
# print('conv2', x.shape)
x = self.pool1(x)
# print('pool2', x.shape)
x = x.view(x.size(0), -1)
# print('view: ', x.shape)
x = F.relu(self.fc1(x))
# print('fc1: ', x.shape)
x = F.relu(self.fc2(x))
x = F.softmax(self.fc3(x), dim=1)
return x
def main():
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
print('cuda device count: ', torch.cuda.device_count())
torch.manual_seed(1234)
net = Lenet5()
net = net.to('cuda:0')
net.eval()
import time
st_time = time.time()
nums = 10000
for i in range(nums):
tmp = torch.ones(1, 1, 32, 32).to('cuda:0')
out = net(tmp)
# print('lenet out shape:', out.shape)
print('lenet out:', out)
end_time = time.time()
print('==cost time{}'.format((end_time - st_time)))
torch.save(net, "lenet5.pth")
def model_onnx():
input = torch.ones(1, 1, 32, 32, dtype=torch.float32).cuda()
model = Lenet5()
model = model.cuda()
torch.onnx.export(model, input, "./lenet.onnx", verbose=True)
if __name__ == '__main__':
# main()
model_onnx()抓换onnx,遇到好几种问题,用这种基本都解决了.
torch.onnx.export(model, # model being run
input, # model input (or a tuple for multiple inputs)
"./xxxx.onnx",
opset_version=10,
verbose=False, # store the trained parameter weights inside the model file
training=False,
do_constant_folding=True,
input_names=['input'],
output_names=['output']
)
2.3 .pth存储为.wts
将模型权重按照key,value形式存储为16进制文件, inference.py
import torch
from torch import nn
from lenet5 import Lenet5
import os
import struct
def main():
print('cuda device count: ', torch.cuda.device_count())
net = torch.load('lenet5.pth')
net = net.to('cuda:0')
net.eval()
#print('model: ', net)
#print('state dict: ', net.state_dict()['conv1.weight'])
tmp = torch.ones(1, 1, 32, 32).to('cuda:0')
#print('input: ', tmp)
out = net(tmp)
print('lenet out:', out)
f = open("lenet5.wts", 'w')
print('==net.state_dict().keys():', net.state_dict().keys())
f.write("{}\n".format(len(net.state_dict().keys())))
for k, v in net.state_dict().items():
print('key: ', k)
print('value: ', v.shape)
vr = v.reshape(-1).cpu().numpy()
f.write("{} {}".format(k, len(vr)))
for vv in vr:
# print('=vv:', vv)
f.write(" ")
# print(struct.pack(">f", float(vv)).hex())#
f.write(struct.pack(">f", float(vv)).hex())
f.write("\n")
print('==f:', f)
def test_struct():
vv = 16
print(struct.pack(">f", float(vv))) #
if __name__ == '__main__':
main()
# test_struct()
2.4 .wts转换成.engine与利用.engine推理
lenet.cpp
#include <map>
#include <chrono>
#include <fstream>
#include "NvInfer.h"
#include "logging.h"
#include "cuda_runtime_api.h"
static const int INPUT_H=32;
static const int INPUT_W=32;
static const int BATCH_SIZE=32;
static const int OUTPUT_SIZE=10;
static const int INFER_NUMS=10000;
const char* INPUT_BLOB_NAME = "data";
const char* OUTPUT_BLOB_NAME = "prob";
using namespace nvinfer1;
static Logger gLogger;
#define CHECK(status) \
do\
{\
auto ret = (status);\
if (ret != 0)\
{\
std::cerr << "Cuda failure: " << ret << std::endl;\
abort();\
}\
} while (0)
std::map<std::string, Weights> loadWeights(const std::string file)
{
std::cout << "Loading weights: " << file << std::endl;
std::map<std::string, Weights> weightMap;
// Open weights file
std::ifstream input(file);
assert(input.is_open() && "Unable to load weight file.");
// Read number of weight blobs
int32_t count;
input >> count;
assert(count > 0 && "Invalid weight map file.");
while (count--)
{
Weights wt{DataType::kFLOAT, nullptr, 0};
uint32_t size;
// Read name and type of blob
std::string name;
input >> name >> std::dec >> size;
wt.type = DataType::kFLOAT;
// Load blob
uint32_t* val = reinterpret_cast<uint32_t*>(malloc(sizeof(val) * size));
for (uint32_t x = 0, y = size; x < y; ++x)
{
input >> std::hex >> val[x];
}
wt.values = val;
wt.count = size;
weightMap[name] = wt;
}
return weightMap;
}
ICudaEngine* createLenetEngine(unsigned int maxBatchSize, IBuilder* builder, IBuilderConfig* config, DataType dt)
{
//开始定义网络 0U无符号整型0
INetworkDefinition* network = builder->createNetworkV2(0U);
ITensor* input = network->addInput(INPUT_BLOB_NAME, dt, Dims3{1, INPUT_H, INPUT_W});
assert(input);
std::map<std::string, Weights> weightMap = loadWeights("../lenet5.wts");//载入权重放入weightMap
// std::cout<<weightMap["conv1.weight"]<<std::endl;
//卷积层
IConvolutionLayer* conv1 = network->addConvolution(*input, 6, DimsHW{5, 5}, weightMap["conv1.weight"], weightMap["conv1.bias"]);
//设置步长
assert(conv1);
conv1->setStrideNd(DimsHW{1, 1});
//激活层
IActivationLayer* relu1 = network->addActivation(*conv1->getOutput(0), ActivationType::kRELU);
assert(relu1);
//pooling层
IPoolingLayer* pool1 = network->addPoolingNd(*relu1->getOutput(0), PoolingType::kAVERAGE, DimsHW{2, 2});
assert(pool1);
pool1->setStrideNd(DimsHW{2, 2});
//卷积层
IConvolutionLayer* conv2 = network->addConvolution(*pool1->getOutput(0), 16, DimsHW{5, 5}, weightMap["conv2.weight"], weightMap["conv2.bias"]);
//设置步长
assert(conv2);
conv2->setStrideNd(DimsHW{1, 1});
//激活层
IActivationLayer* relu2 = network->addActivation(*conv2->getOutput(0), ActivationType::kRELU);
assert(relu2);
//pooling层
IPoolingLayer* pool2 = network->addPoolingNd(*relu2->getOutput(0), PoolingType::kAVERAGE, DimsHW{2, 2});
assert(pool2);
pool2->setStrideNd(DimsHW{2, 2});
//全连接
IFullyConnectedLayer* fc1 = network->addFullyConnected(*pool2->getOutput(0), 120, weightMap["fc1.weight"], weightMap["fc1.bias"]);
assert(fc1);
//激活层
IActivationLayer* relu3 = network->addActivation(*fc1->getOutput(0), ActivationType::kRELU);
assert(relu3);
//全连接
IFullyConnectedLayer* fc2 = network->addFullyConnected(*relu3->getOutput(0), 84, weightMap["fc2.weight"], weightMap["fc2.bias"]);
assert(fc2);
//激活层
IActivationLayer* relu4 = network->addActivation(*fc2->getOutput(0), ActivationType::kRELU);
assert(relu4);
//全连接
IFullyConnectedLayer* fc3 = network->addFullyConnected(*relu4->getOutput(0), OUTPUT_SIZE, weightMap["fc3.weight"], weightMap["fc3.bias"]);
assert(fc3);
//分类层
ISoftMaxLayer *prob = network->addSoftMax(*fc3->getOutput(0));
assert(prob);
prob->getOutput(0)->setName(OUTPUT_BLOB_NAME);
network->markOutput(*prob->getOutput(0));
//构造engine
builder->setMaxBatchSize(maxBatchSize);
config->setMaxWorkspaceSize(1<<20);
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
//放入engine 所以network可以销毁了
network->destroy();
// 释放资源
for (auto& mem : weightMap)
{
free((void*) (mem.second.values));
}
return engine;
}
void APIToModel(unsigned int maxBatchSize, IHostMemory** modelStream)
{
//创建builder
IBuilder* builder = createInferBuilder(gLogger);//网络入口 类似pytorch的model
IBuilderConfig* config = builder->createBuilderConfig();
//创建模型 搭建网络层
ICudaEngine* engine = createLenetEngine(maxBatchSize, builder, config, DataType::kFLOAT);
assert(engine!=nullptr);
//序列化engine
(*modelStream)= engine->serialize();
//销毁对象
engine->destroy();
builder->destroy();
}
void doInference(IExecutionContext& context, float* input, float *output, int batchSize)
{
//使用传进来的context恢复engine。
const ICudaEngine& engine = context.getEngine();
//输入输出总共有两个,做一下验证
assert(engine.getNbBindings()==2);
//void
void* buffers[2];
//获取与这个engine相关的输入输出tensor的索引s
const int inputIndex = engine.getBindingIndex(INPUT_BLOB_NAME);
const int outputIndex = engine.getBindingIndex(OUTPUT_BLOB_NAME);
//为输入输出tensor开辟显存。
CHECK(cudaMalloc(&buffers[inputIndex], batchSize * INPUT_H * INPUT_W * sizeof(float)));
CHECK(cudaMalloc(&buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float)));
//创建cuda流,用于管理数据复制,存取,和计算的并发操作
cudaStream_t stream;
CHECK(cudaStreamCreate(&stream));
//从内存到显存,input是读入内存中的数据;buffers[inputIndex]是显存上的存储区域,用于存放输入数据
CHECK(cudaMemcpyAsync(buffers[inputIndex], input, batchSize * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream));
// //启动cuda核,异步执行推理计算
context.enqueue(batchSize, buffers, stream, nullptr);
//从显存到内存,buffers[outputIndex]是显存中的存储区,存放模型输出;output是内存中的数据
CHECK(cudaMemcpyAsync(output, buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));
//如果使用了多个cuda流,需要同步
cudaStreamSynchronize(stream);
// Release stream and buffers
cudaStreamDestroy(stream);
CHECK(cudaFree(buffers[inputIndex]));
CHECK(cudaFree(buffers[outputIndex]));
}
int main(int argc, char ** argv)
{
if (argc!=2)
{
std::cerr << "arguments not right!" << std::endl;
std::cerr << "./lenet -s // serialize model to plan file" << std::endl;
std::cerr << "./lenet -d // deserialize plan file and run inference" << std::endl;
return -1;
}
//序列化模型为.engine文件
if(std::string(argv[1])=="-s")
{
IHostMemory* modelStream{nullptr};//modelStream是一块内存区域,用来保存序列化文件
APIToModel(1, &modelStream);
assert(modelStream!=nullptr);
//变换为.engine文件
std::ofstream p("lenet.engine");
if (!p)
{
std::cerr<<"can not open plan file"<<std::endl;
return -1;
}
p.write(reinterpret_cast<const char *>(modelStream->data()), modelStream->size());
// p.write(reinterpret_cast<const char*>(modelStream->data()), modelStream->size());
//销毁对象
modelStream->destroy();
}
else if (std::string(argv[1])=="-d")
{
char *trtModelStream{nullptr};
size_t size{0};
std::ifstream file("lenet.engine", std::ios::binary);
if (file.good()) {
file.seekg(0, file.end);
size = file.tellg();
file.seekg(0, file.beg);
trtModelStream = new char[size];
assert(trtModelStream);
file.read(trtModelStream, size);
file.close();
}
else
{
return -1;
}
//模拟数据
float data[INPUT_H*INPUT_W];
for (int i=0;i<INPUT_W*INPUT_H;i++)
{
data[i] = 1.0;
}
//创建运行时环境IRuntime对象
IRuntime* runtime = createInferRuntime(gLogger);
assert(runtime !=nullptr);
ICudaEngine* engine = runtime->deserializeCudaEngine(trtModelStream,size,nullptr);
assert(engine !=nullptr);
//创建上下文环境,主要用与inference函数中启动cuda核
IExecutionContext* context = engine->createExecutionContext();
assert(context !=nullptr);
//开始推理, 模拟推理1000次,存储推理结果
float prob[OUTPUT_SIZE];
auto start = std::chrono::system_clock::now();//开始时间
for (int i=0;i<INFER_NUMS;i++)
{
// std::cout<<"data[i]:"<<data[i]<<std::endl;
doInference(*context, data, prob, 1);
}
auto end = std::chrono::system_clock::now();//结束时间
std::cout << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" << std::endl;
context->destroy();
engine->destroy();
runtime->destroy();
std::cout<<"prob:";
for (int i=0;i<OUTPUT_SIZE;i++)
{
std::cout<<prob[i]<<",";
}
}
else
{
return -1;
}
return 0;
}CMakeLists.txt
cmake_minimum_required(VERSION 2.6)
project(lenet)
add_definitions(-std=c++11)
set(TARGET_NAME "lenet")
option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_BUILD_TYPE Debug)
include_directories(${PROJECT_SOURCE_DIR}/include)
# include and link dirs of cuda and tensorrt, you need adapt them if yours are different
# cuda
include_directories(/usr/local/cuda/include)
link_directories(/usr/local/cuda/lib64)
# tensorrt
include_directories(/usr/include/x86_64-linux-gnu)
link_directories(/usr/lib/x86_64-linux-gnu)
#tar包 tensorrt
#include_directories(/red_detection/tensorrt_learn/software/TensorRT-7.0.0.11/include)
#link_directories(/red_detection/tensorrt_learn/software/TensorRT-7.0.0.11/lib)
FILE(GLOB SRC_FILES ${PROJECT_SOURCE_DIR}/lenet.cpp ${PROJECT_SOURCE_DIR}/include/*.h)
add_executable(${TARGET_NAME} ${SRC_FILES})
target_link_libraries(${TARGET_NAME} nvinfer)
target_link_libraries(${TARGET_NAME} cudart)
add_definitions(-O2 -pthread)
./lenet -s 转换成 .engine文件
./lenet -d 进行推理
推理时间:
![]()
可看出时间和torch的相比加快了至少4倍,而结果却差不多。
一些很不错的仓库:

















 46万+
46万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









