



参考网址:https://blog.youkuaiyun.com/qq_20901397/article/details/79982679
一、基础
js排序:
1、冒泡法(当数据庞大时不适用可以使用快速排序法)
function(arr){
for(var i=0;i<arr.length-1;i++){ //决定比较的轮数,数组有n个数,就比较n-1次
for(var j=0;j<arr.length-i-1;j++){//每一轮中如果前一个数比后一个数大,则交换位置,这个之所以-1是因为使用了j+1,不超过数组的最后一项。,这里为什么是arr.length-i-1,因为每冒泡一次就会选出一个最大值,然后下一次冒泡就不用再去比较前一趟所冒泡的最大值了所以长度就会减去i
if(arr[j]>arr[j+1]){
var temp;
temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
return arr;
}
例如arr=[21,33,1,2,34];
第一轮:i=0,arr[i]=21
arr[j]=21;arr[j+1]=33;
arr[j]=33;arr[j+1]=1;
arr[j]=33;arr[j+1]=2;
arr[j]=33;arr[j+1]=34;
这一轮下来arr=[21,1,2,33,34];
第二轮:i=1,arr[i]=1;
arr[j]=21;arr[j+1]=1;
arr[j]=21;arr[j+1]=2;
arr[j]=21;arr[j+1]=33;
arr[j]=33;arr[j+1]=34;
第二轮下来arr=[1,2,21,33,34];
…一共length-1次比较轮数
最后一轮是i=length-2,j=0;j<1的时候比较arr[0]与arr[1]的比较
冒泡法的优化:
2、快速排序(对冒泡法的改进)
3、html与xml的区别:
html与xml的语法类似,都是以开始、结束配对的标记符来标识信息。但是两者功能不同,html是用来显示数据的(html超文本标记语言,网页构成的主要语言,通俗的来说就是描述网页长什么样子,网页上有什么内容的文本。我们看到的网页就是浏览器解析html文本出现的结果);xml是用来描述数据的性质和结构,存储、传递数据的。
二者语法上的区别:
1.html 不区分大小写,xml严格区分大小写
2.html 标签都是预定义的,xml 标签都是自定义,可扩展的
xml与json的对比:
两者都是前后端数据交互语言。xml解析困难,带宽大,
(7).数据体积方面。
JSON相对于XML来讲,数据的体积小,传递的速度更快些。
(8).数据交互方面。
JSON与JavaScript的交互更加方便,更容易解析处理,更好的数据交互。
(9).数据描述方面。
JSON对数据的描述性比XML较差。
(10).传输速度方面。
JSON的速度要远远快于XML
<?xml version="1.0" encoding="utf-8" ?>
<country>
<name>中国</name>
<province>
<name>黑龙江</name>
<citys>
<city>哈尔滨</city>
<city>大庆</city>
</citys>
</province>
</country>
var country =
{
name: "中国",
provinces: [
{ name: "黑龙江", citys: { city: ["哈尔滨", "大庆"]} },
{ name: "广东", citys: { city: ["广州", "深圳", "珠海"]} }
]
}
4、DTD(document type defination 文档类型定义)
实际是asc||码的文本文件,后缀是 .dtd,是一套关于标记符的语法规则,对文档(xml、html)的规范声明。
dtd的作用:通过在文档中使用url引入对应的dtd文件,dtd书写方式来影响浏览器的渲染模式(标准、混杂、近似标准)。浏览器根据dtd中的规定的文档类型来检查页面的有效性并采取相应措施。
html4规定了三种文档类型:严格、过渡、框架
xhtml1.0规定了三种:strict、transitional、frameset
html5只规定了一种:doctype
(html5不需要引用dtd的原因:html4是基于SGML,dtd规定了SGML的语法规则,而html5并不基于通用标记语言SGML)
DTD的不同导致渲染模式的不同
①XHTML文档包含形式完整的DOCTYPE,一般以标准模式呈现。
②HTML4.01文档,包含严格DTD的文档,一般也以标准模式呈现。
③含过渡DTD和URI的DOCTYPE,一般以标准模式呈现。
④含过渡DTD但没有URI的DOCTYPE,会以混杂模式呈现。
⑤DOCTYPE不存在或不正确会导致HTML和XHTML文档以混杂模式呈现。
5、http请求方法
8个http请求方法:get、post、delete、put、head(查看服务器上的某个资源是否存在,测试超链接的有效性)、options(获取url支持的方法)、trace、connect
get与head的区别:get是发送请求获取某一资源,后者不含有呈现数据,只是http头信息
post与put的区别:都是向数据库提供数据,但是put会指定资源的存放位置。例如post实现添加的业务场景;put实现编辑的业务场景,会在url中增加一个id指定位置
get和post的区别:
a、get请求数据,post发送数据
b、get是url传参(格式:http://127.0.0.1/Test/login.action?name=admin&password=admin)用户可见,post请求体传参,用户不可见
c、get数据量小,效率高,post量大
d、post比get安全
e、get仅支持只支持ASCII码传值,中文可能乱码。post支持标准字符集

6、http与https
http:www服务器传输超文本到本地浏览器的网络传输协议,客户端与服务器端请求和应答的标准
OSI网络协议有五层:物理层(光纤)、数据链路层(wifi)、网络层(路由)、传输层(tcp/ip协议:如何在网络中传输)、(会话层、表示层)、应用层(http协议:如何包装数据、ftp等,交互发生地),端口号:80
https:在http(明文传输)基础上加了一层ssl(secure sockets layer),端口号:443
两者区别:
a、 https需要ca证书(花钱)
b、https具有安全性的ssl加密
c、端口、连接方式不同,http 80端口,https:443端口
https工作原理:
a、客户端通过https的url向服务端请求ssl连接
b、服务器端将网站的证书信息(含有公钥)传送给客户端
c、客户端与服务器端协商安全等级,客户端浏览器根据协商产生随机密钥,通过网站的公钥加密传递给网站
d、服务器端利用自己的私钥解密会话密钥并进行密文通信
https优缺点:
优点:a、可认证两端,确认发送两端没有错误 b、安全,使用http+ssl进行加密传输、身份认证,可防止数据窃取改变
缺点:a、握手阶段费时,耗电量大 b、ssl证书费钱 c、ssl证书需要绑定ip,不能在同一ip上绑定多个域名,ipv4资源不够 d、黑客攻击
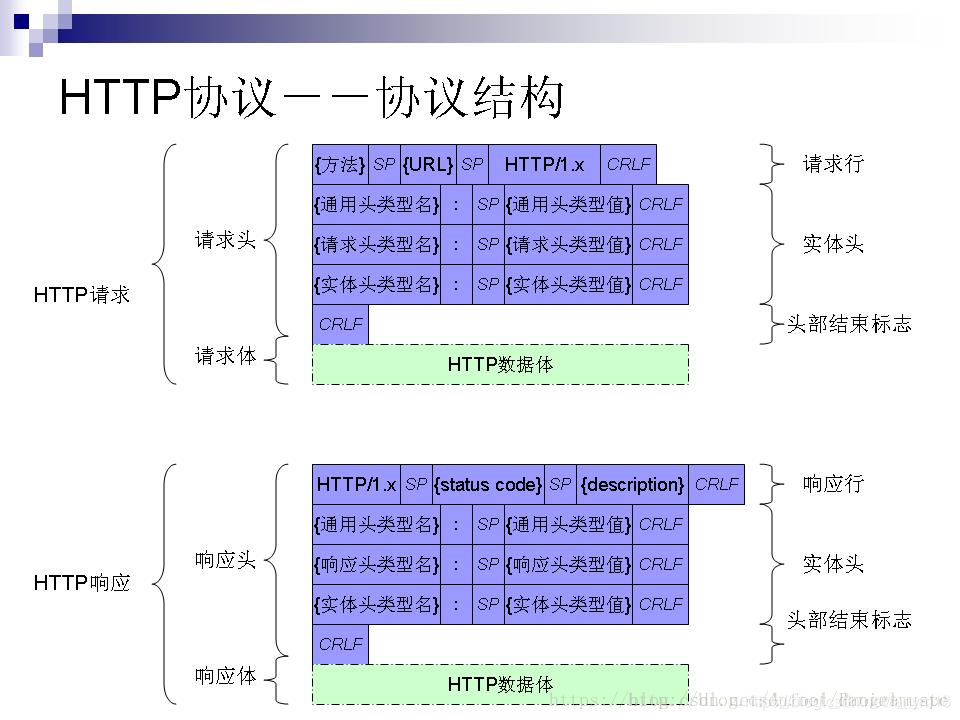
7、http请求报文和响应报文格式
请求报文:请求行、请求头、空行、请求数据
请求行:方法 空格 url 空格 http版本
请求头:accetp(请求对象类型)、accetp-language(语言环境)、accept-encording(客户端编码环境)、accept-charset、user-agent(客户端类型)、host(请求主机名)、connection(是否需要持久连接)、authorization(授权信息)、cookie(存储保持会话信息)
响应报文:状态行、消息报头、相应正文
状态行:http协议版本 空格 响应状态码 空格 状态码的文本描述
响应头:location(令客户端重新定向到的URI)、server(HTTP服务器的安装信息)、content-encoding、conent-length、conent-type、last-modified、date、refresh
响应码:
1xx:请求已接受
2xx:成功接受(200)
3xx:重定向(301,302)
4xx:客户端问题(404)
5xx:服务器端问题
7、url与uri的区别
l是locator定位 i是identifier标识,url不可以是相对的,是绝对的,可以定位到某个资源上,是具体的uri
8、一次完整的http请求经历的7个步骤
建立TCP连接->发送请求行->发送请求头->(到达服务器)发送状态行->发送响应头->发送响应数据->断TCP连接
9、http1.1版本新特性
持久连接:只要两端任何一端不断开就一直保持连接
管线化:一个客户端可以同时发出多个http请求,不用一个个等待响应。(区分tcp复用)
10、http优化方案
tcp复用:多个客户端的http请求复用到一个服务器端tcp连接上
tcp缓冲:提高服务器响应喝处理效率
内容缓存:将经常用的网页内容缓存起来,客户端可以直接从内存中获取数据
压缩:将文本数据进行压缩,减少带宽
ssl加速:ssl不仅可以加密还可以在通道内加速
11、从输入url到页面加载全过程
a、浏览器查找当前URL是否存在缓存(expires、cathe-control),并比较缓存是否过期。
b、DNS域名解析解析URL对应的IP。
c、据IP建立TCP连接(三次握手)。
d、HTTP发起请求。
f、服务器处理请求,浏览器接收HTTP响应。
e、渲染页面,构建DOM树。
g、服务器关闭TCP连接(四次挥手)。
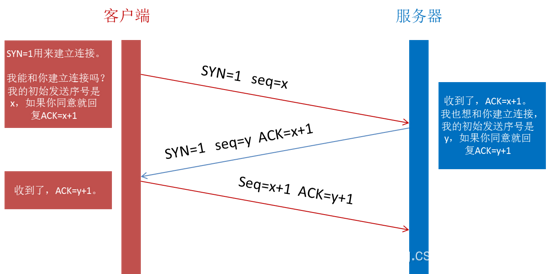
12、三次握手(syn seq,syn seq ack,ack)
第一次:客户端发送syn(syn=1,seq=x)包到服务器,进入syn_sent状态
第二次:服务器发送syn+ack(syn=1,seq=y,ack=x+1)到客户端,进入syn_recv状态
第三次:客户端发送ack(seq=x+1,ack=y+1)到服务器端,进入establish状态,完成三次握手
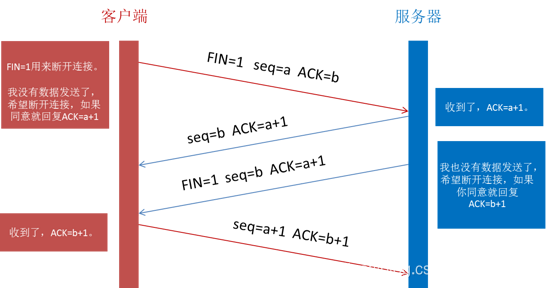
13、四次挥手(fin seq,ack seq,fin seq ack,seq,ack)
第一次:fin=1,seq=a,ack=b
第二次:seq=b,ack=a+1
第三次:fin=1,seq=b,ack=a+1
第四次:seq=a+1,ack=b+1
服务器可能还有数据要发送
14、浏览器内核拿到响应后渲染页面步骤
解析html,生成dom树
解析css,生成css规则
合并生成render树,,布局绘制render树,浏览器将各层的信息发给gui,gui合成各层,显示在屏幕上
15、五大常见浏览器的内核,常见浏览器兼容问题
IE:trident
chrome:blink
firefox:gecko
safari:webkit
opera:blink
16、http缓存
浏览器缓存:http缓存、cookie、localSotrage、sessionStorage
http缓存:强缓存、协商缓存
浏览器先判断是否命中强缓存。如果命中则直接加在缓存中的资源,并不会将请求发送到服务器。如果未命中强缓存,则浏览器发送请求到服务器。服务器来判断浏览器本地缓存是否失效。若可以使用,则服务器并不会返回资源信息,浏览器继续从缓存加载资源。如果未命中协商缓存,则服务器会将完整的资源返回给浏览器,浏览器加载新资源,并更新缓存。
强缓存:在http响应头中的expires(gmt到期时间)和cache-control(max-age =…单位为s,优先级更高)决定
由于失效时间是一个绝对时间,所以当客户端本地时间被修改以后,服务器与客户端时间偏差变大以后,就会导致缓存混乱。于是发展出了Cache-Control
协商缓存:服务器根据http头信息中的Last-Modify/If-Modify-Since或Etag/If-None-Match来判断是否命中协商缓存。如果命中,则http返回码为304,浏览器从缓存中加载资源。
Last-Modify/If-Modify-Since或Etag/If-None-Match
17、如何跨域访问
由于浏览器安全限制的同源策略:协议、域名、端口号都相同,只要有一个不相同,那么都是非同源。
不同源:Cookie、LocalStorage 和 IndexDB 无法读取;DOM 和 Js对象无法获得;AJAX 请求不能发送
但是(对于像 img、iframe、script 等标签的 src 属性是特例,它们是可以访问非同源网站的资源的。)
跨域方法:
(1) 跨域代理:vue.config.js的proxy中设置代理
const service = axios.create({
baseURL:process.env.VUE_APP_BASE_URL,
withCredentials:true, //跨域请求时的凭证
timeout: 10000,
});
module.exports={
publicPath:process.env.VUE_APP_ROUTER_BASE_URL,// //默认情况下,vue cli会假设应用被部署在域名的根路径上(例如:http://baidu.com),如果被部署在子路径上,那么需要用这个选项和vue.config.js中的publicPath来指定这个子路径(http://baidu.com/tlife-platform-admin)
devServer:{ //环境配置
open:true,//配置自动启动浏览器
proxy:{// 跨域请求时需要配置代理
'/app':{ //凡是匹配到该路径都设置代理
target:"http://10.xxx.xxx.xxx", //后台服务器域名,注意:此处写了target,对应的baseURL就得为空了,否则重复
changeOrigin:true,//跨域需要配置
pathRewrite:{}
}
}
}
}
(2) JSONP
利用script标签src属性的开放策略请求数据,动态加载 script的src。
注意两点
一、使用 JSONP模式来请求数据,服务端返回的是一段可执行的 JavaScript代码。
二、我们只能把参数通过 url的方式传递,所以jsonp的 type类型只能是get
18、cors的返回头、cors预请求,什么时候会出发预请求
js
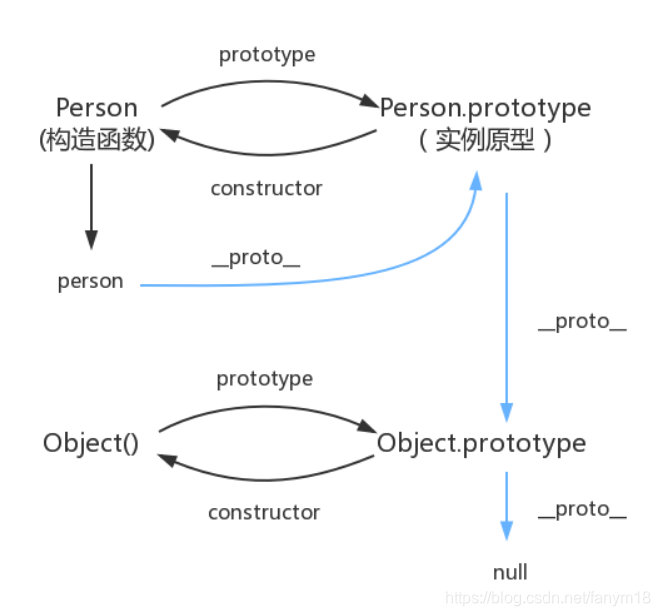
原型链:
数组
基本方法
判断a是否是数组的方法:
1、Array.isArray(a) 判断a是否是数组,返回布尔
2、判断变量a是否是b的实例 a instanceof Array
3、判断a的构造函数是否是b a.constructor==Array
截取
2、array.spllice(),三个参数 start,num,addelemts,改变原数组,返回被删除元素
3、array.slice(),两个参数:start,end含头不含尾,不改变原数组,返回新数组
头尾增删:
4、array.pop() 尾部删除一个元素,返回被删除元素
5、array.push() 尾部添加一个或多个元素,返回length
6、array.shift() 头部删除一个元素,返回被删除元素
7、array.unshift() 头部添加一个或多个元素,返回length
遍历
8、arr.map(item=>{}) 返回新数组,不改变原数组,
9、arr.forEach(item=>{}) 返回修改后的数组,改变原数组
vue
一、vue的事件、回调、属性为什么不能使用箭头函数
箭头函数中的this是绑定父级上下文的,非严格模式下,不使用箭头函数内部的this指向的就是vm实例,一旦使用es6中的箭头函数就会指向undefined
二、v-model的原理
三、nextTick的原理
涉及到的是js的事件循环:主执行栈+任务队列(宏任务(同步代码,setTimeOut,setInterval)+微任务(nextTick,promise.then))
vue是数据驱动视图,是异步的。宏任务一个一个放到主执行栈中执行,当执行栈执行完成后更新DOM,完成后立即清空该过程产生的微任务(调用nextTick),所以在nextTick中可以获得更新之后的数据。
react
一、优势和特点
react起源于facebook,由于独特的diff算法设计,性能出众,代码逻辑简单,成为web前端主流的开发工具,特点如下:
1、独特的diff算法(真实DOM与虚拟dom直接进行对比,过程中直接更新真实dom)
三个策略:
a、只对比同一层级的变化
b、拥有相同类的两个组件会生成相似的树形结构,拥有不同类的两个组件会生成不同的树形结构
c、同一层级的一组子节点可以使用唯一的id进行区分
基于三个策略对虚拟dom的结构(三种)进行算法优化:文本,原生dom节点,组件
a、对比文本节点:直接更新内容
b、非文本dom节点:提供了三个节点操作:移动、插入(全新节点)、删除
c、组件:如果是同一类型的组件,进行虚拟dom比较(shouldComponentUpdate(nextState,nextProps)判断是否需要进行diff算法),如果不是直接替换
2、代码采用jsx,将html于js混写
reactDOM.render(
<div>
<h1>{1+1}</h1>
<div>,documen.getElementById("app"))
3、组件:不过是一段Html结构的包装容器,并且具备管理这段Html结构的状态等能力;
可复用,可维护性高
class App extends React.Component{
render(){
return(
<div>
<h1>{1+1}</h1>
<div>
)
}
}
export default App;
4、灵活:
5、react native
二、state与props的区别
props:只读不可变,父组件传递下来的,一般用来实现UI组件之间的嵌套组合
state:可读可写,本组件私有的,一般用来实现交互
三、key的作用,使用index当key可以吗
作用:react用来识别列表元素是否发生了变化(删除或添加)
当数据不会发生变化的情况下可以


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









