





https://docs.nvidia.com/cuda/cuda-c-programming-guide/#
1. Introduction
1.1. The Benefits of Using GPUs
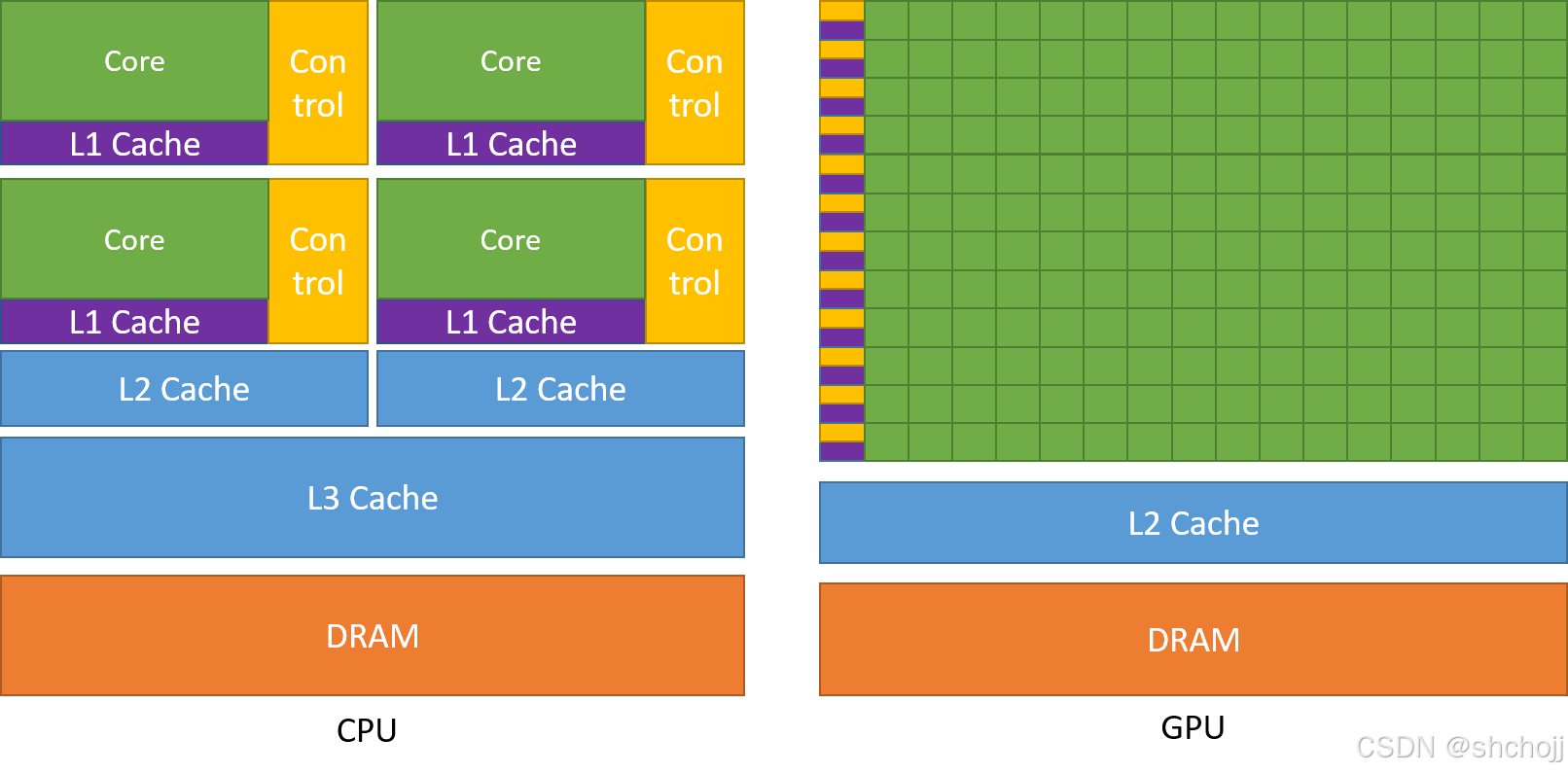
GPU专门用于高度并行计算,因此设计了更多的晶体管用于数据处理,而不是数据缓存和流量控制。GPU可以通过计算隐藏内存访问延迟,而不是依赖于大型数据缓存和复杂的流控制来避免长内存访问延迟,这两者在晶体管方面都是昂贵的。
1.2. CUDA®: A General-Purpose Parallel Computing Platform and Programming Model
1.3. A Scalable Programming Model
多核cpu和多核gpu的出现意味着主流处理器芯片现在是并行系统。挑战在于开发应用软件,透明地扩展其并行性,以利用不断增加的处理器内核数量,就像3D图形应用程序透明地扩展其并行性到具有广泛不同内核数量的多核gpu一样。
其核心是三个关键的抽象概念:线程组、共享内存和屏障同步的层次结构。 a hierarchy of thread groups, shared memories, and barrier synchronization
这些抽象提供细粒度数据并行性和线程并行性 fine-grained data parallelism and thread parallelism,嵌套在粗粒度数据并行性和任务并行性中coarse-grained data parallelism and task parallelism。将问题划分为可以由线程块独立并行解决的粗子问题 coarse sub-problems ,并将每个子问题划分为可以由线程块内的所有线程并行协作解决的细子问题threads within the block。
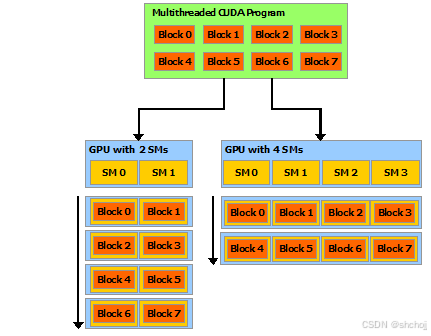
GPU是围绕一组流多处理器Streaming Multiprocessors (SMs)构建的(详见硬件实现)。一个多线程multithreaded 程序被分割成相互独立执行的线程块blocks of threads,这样多处理器的GPU会比少处理器的GPU在更短的时间内自动执行程序。
1.4. Document Structure
- Introduction是对CUDA的一般介绍。
-
编程模型概述了CUDA编程模型。
-
“编程接口”描述了编程接口。
-
硬件实现描述硬件实现。
-
性能指南提供了一些关于如何实现最大性能的指导。
-
CUDA-Enabled gpu列出所有CUDA-Enabled设备。
-
c++语言扩展是c++语言所有扩展的详细描述。
-
协作组描述了各种CUDA线程组的同步原语。
-
CUDA动态并行描述了如何从一个内核启动和同步另一个内核。
-
虚拟内存管理介绍如何管理统一的虚拟地址空间。
-
流有序内存分配器描述了应用程序如何排序内存分配和释放。
-
图内存节点描述了图如何创建和拥有内存分配。
-
数学函数列出了CUDA中支持的数学函数。
-
c++语言支持列出了设备代码中支持的c++特性。
-
Texture抓取提供了更多关于纹理抓取的细节。
-
Compute Capabilities提供了各种设备的技术规范,以及更多的体系结构细节。
-
驱动程序API引入了低级驱动程序API。
-
CUDA环境变量列表列出了所有CUDA环境变量。
-
统一内存编程介绍了统一内存编程模型。

















 809
809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









