







目录
轻松制作 “假如书籍会说话” 爆款视频,单条播放破 50 万,读书博主逆袭必备攻略
轻松制作 “假如书籍会说话” 爆款视频,单条播放破 50 万,读书博主逆袭必备攻略
1. 前言
翻开一本旧书,指尖摩挲泛黄的纸页时,你是否曾幻想过,那些沉淀着智慧与故事的文字能开口诉说?从作者创作时的灵感迸发,到不同读者的感悟共鸣,每一本书都承载着跨越时空的对话。在 Coze 的世界里,这个浪漫想象正变为现实。

今天,我们将带你解锁 “如果书籍能说话” 的COZE工作流,让静默的书籍化身智能伙伴,开启一场前所未有的阅读交互之旅。
效果展示:


2. Coze工作流设计思路
2.1 整体架构规划
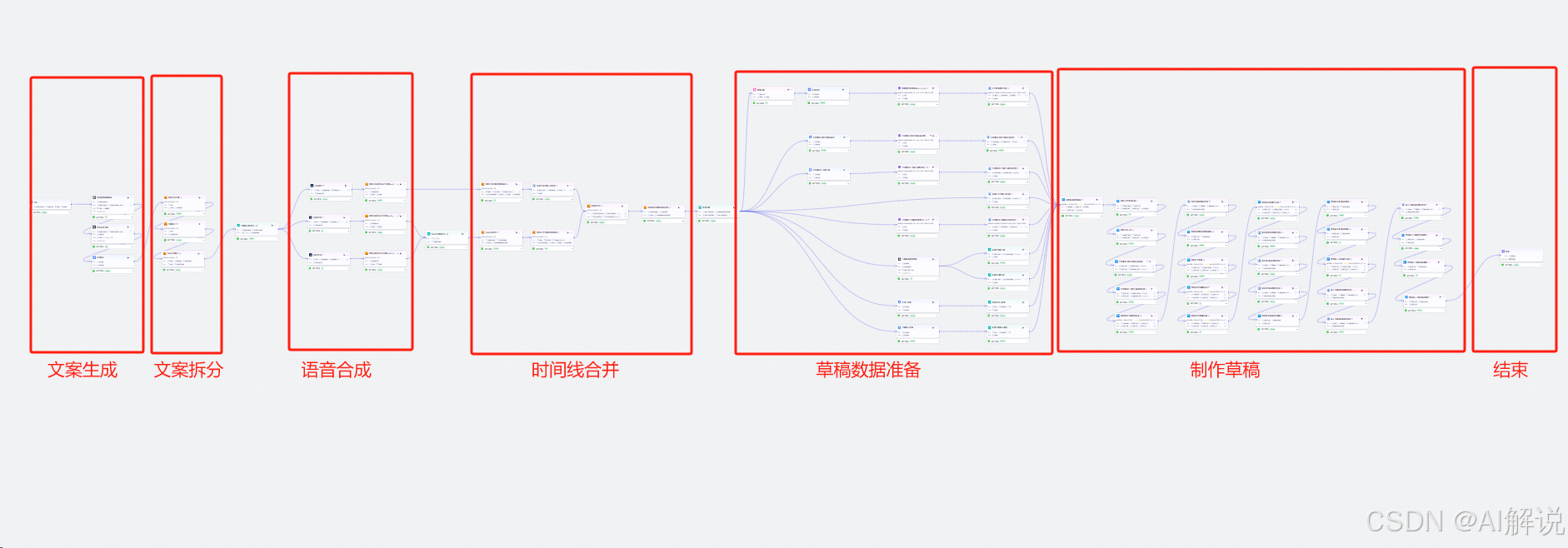
我们设计的工作流主要包含五个核心环节:根据书名生成对话文案,将文案按角色进行台词拆分,将台词进行语音合成,时间线合并,最后将素材、文案和配音通过剪映小助手工具创建剪映草稿。
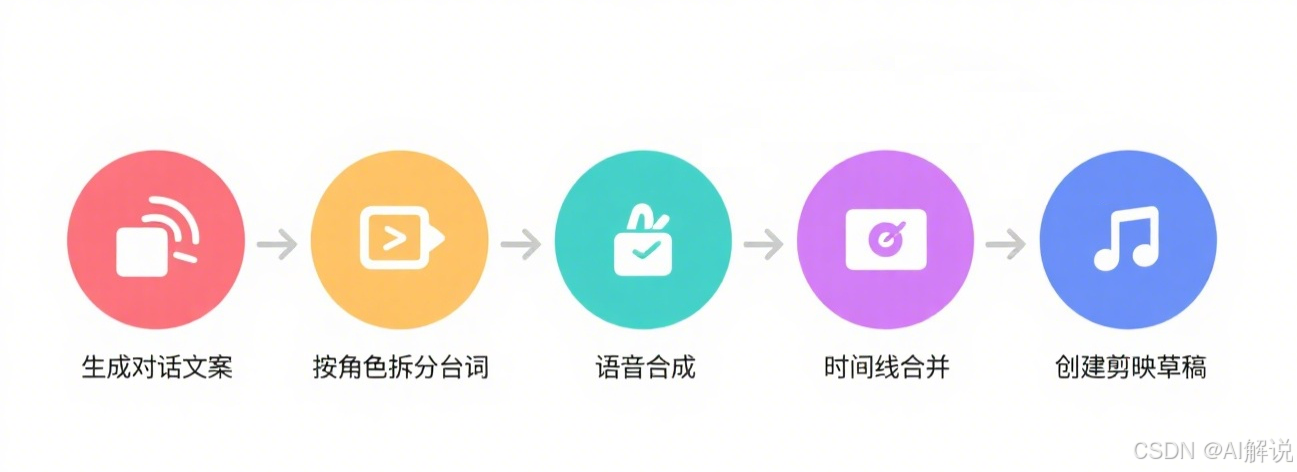
2.2 完整的工作流程
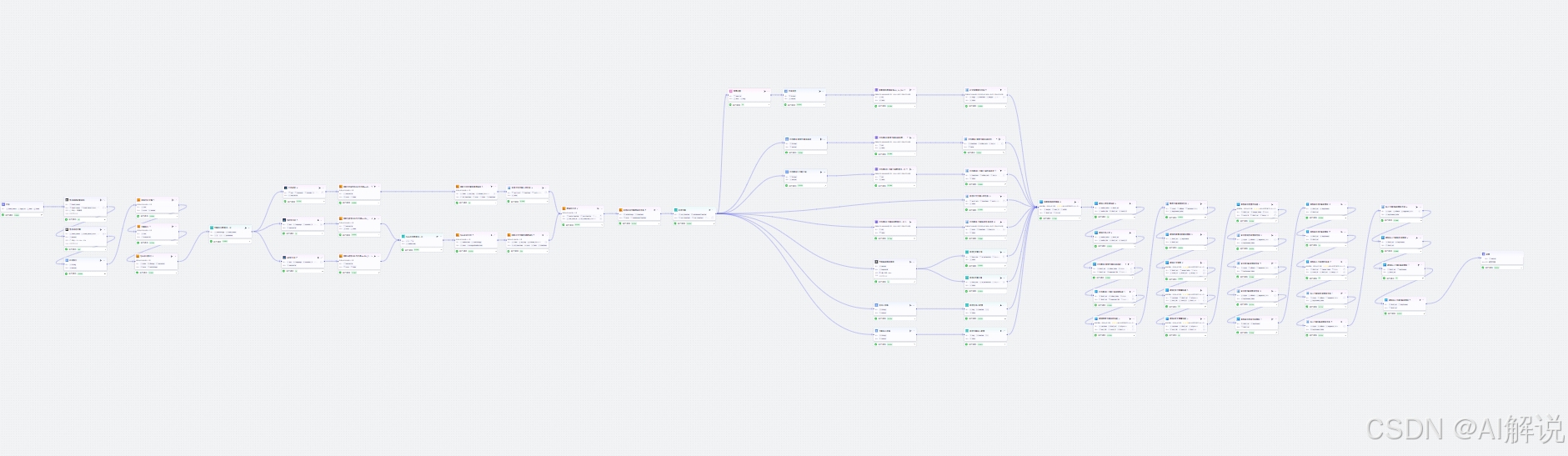
3. Coze工作流具体实现
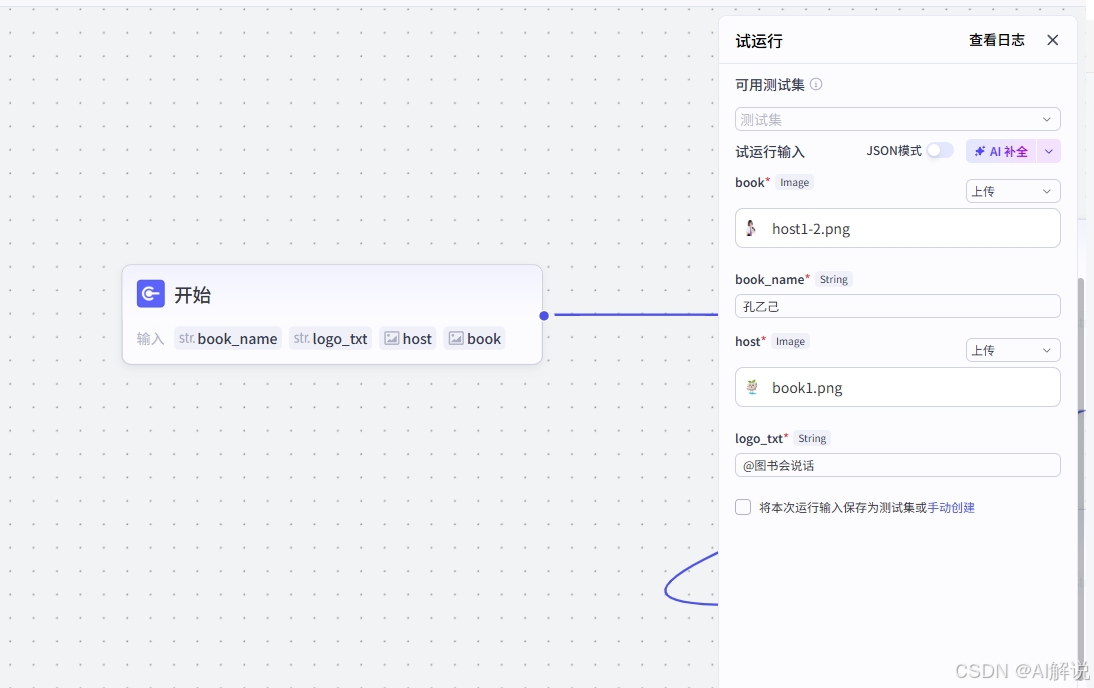
3.1 开始节点:
作为工作流的起始点,其主要作用是接收用户输入。我们设置4个输入变量,book_name、logo_txt、host、book,分别为书名、右下角的文字、主持人形象和书籍的形象。
3.2 生成对话文案:
该节点使用豆包大模型节点,将根据用户输入的参数生成对话文案。
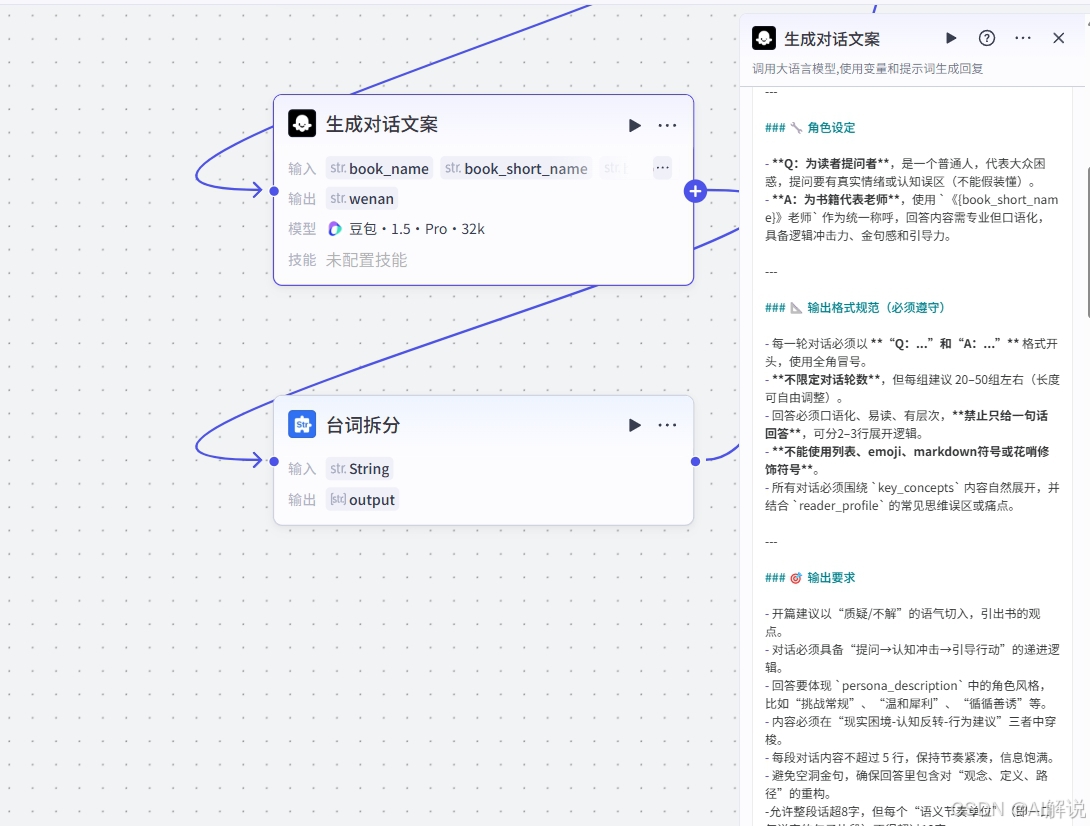
3.3 台词拆分:
该节点负责将获得的文案按照指定的分隔符进行拆分。
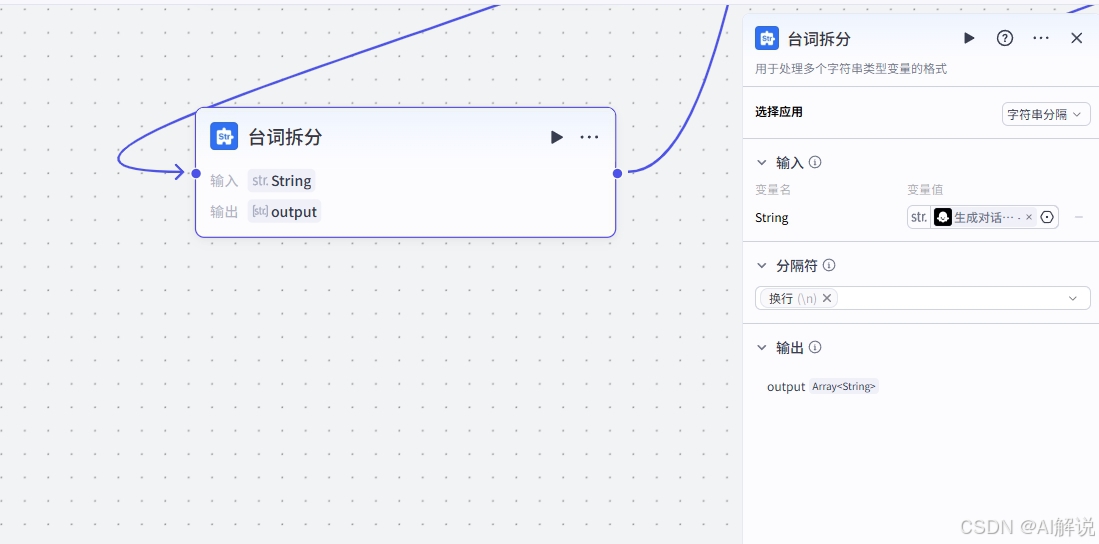
3.4 台词整理:
该组节点负责去除台词中的无效空白文案,然后再按角色拆分台词。
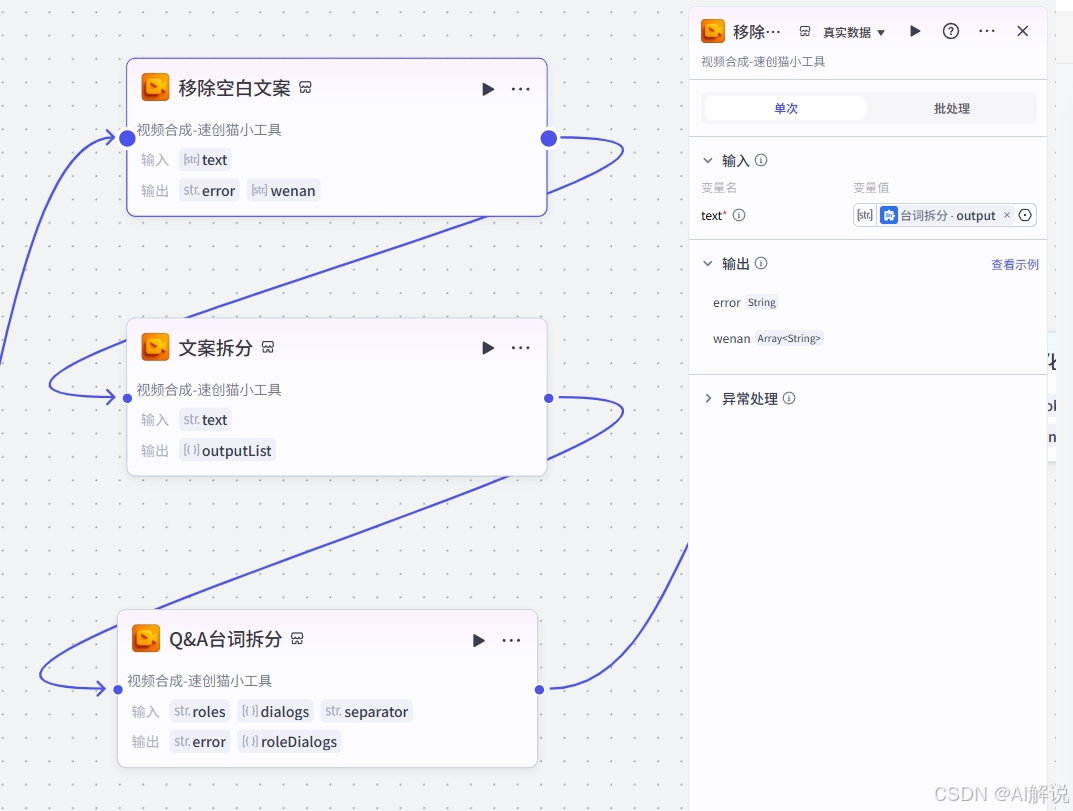
3.5 文案拆分数据合并
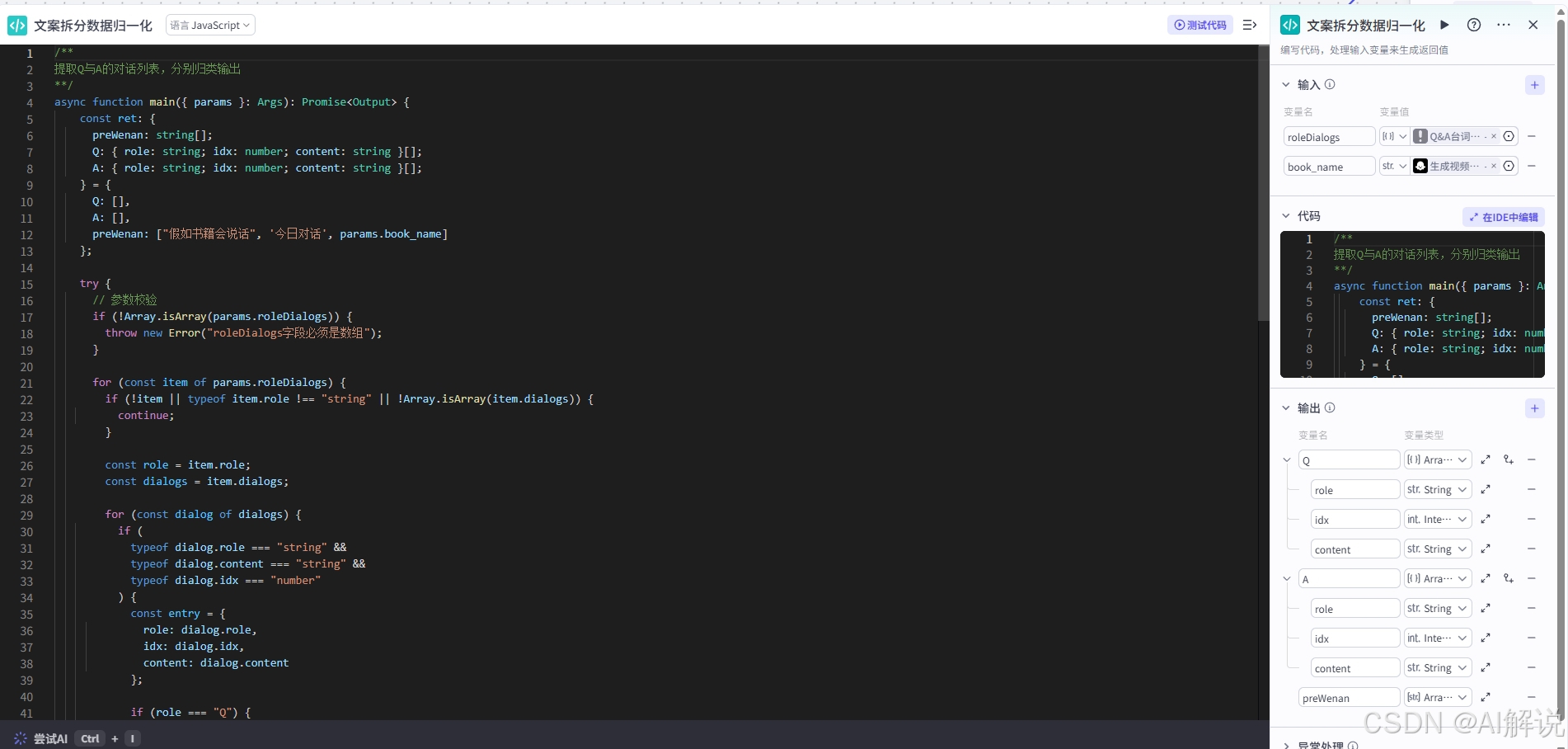
该节点通过代码将对话文案组合起来,输出Q数组和A数组,为后续合成语音做准备。
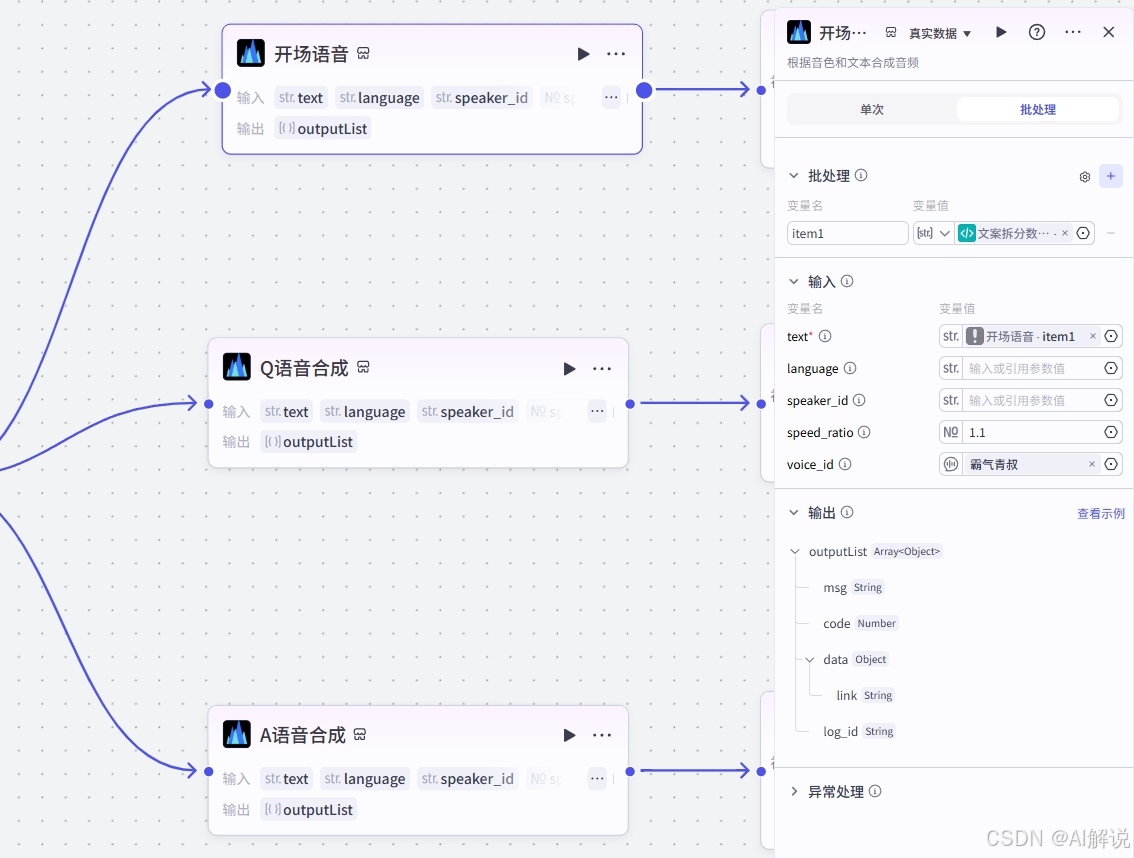
3.6 语音合成
通过合成语音插件将前一个数组中的Q文案和A文案分别合成语音,这里可以选择自己喜欢的音色。
3.7 提取开场文案音频时间线:
3.8 提取正文文案音频时间线:
3.9 时间线合并:
3.10 背景设置:
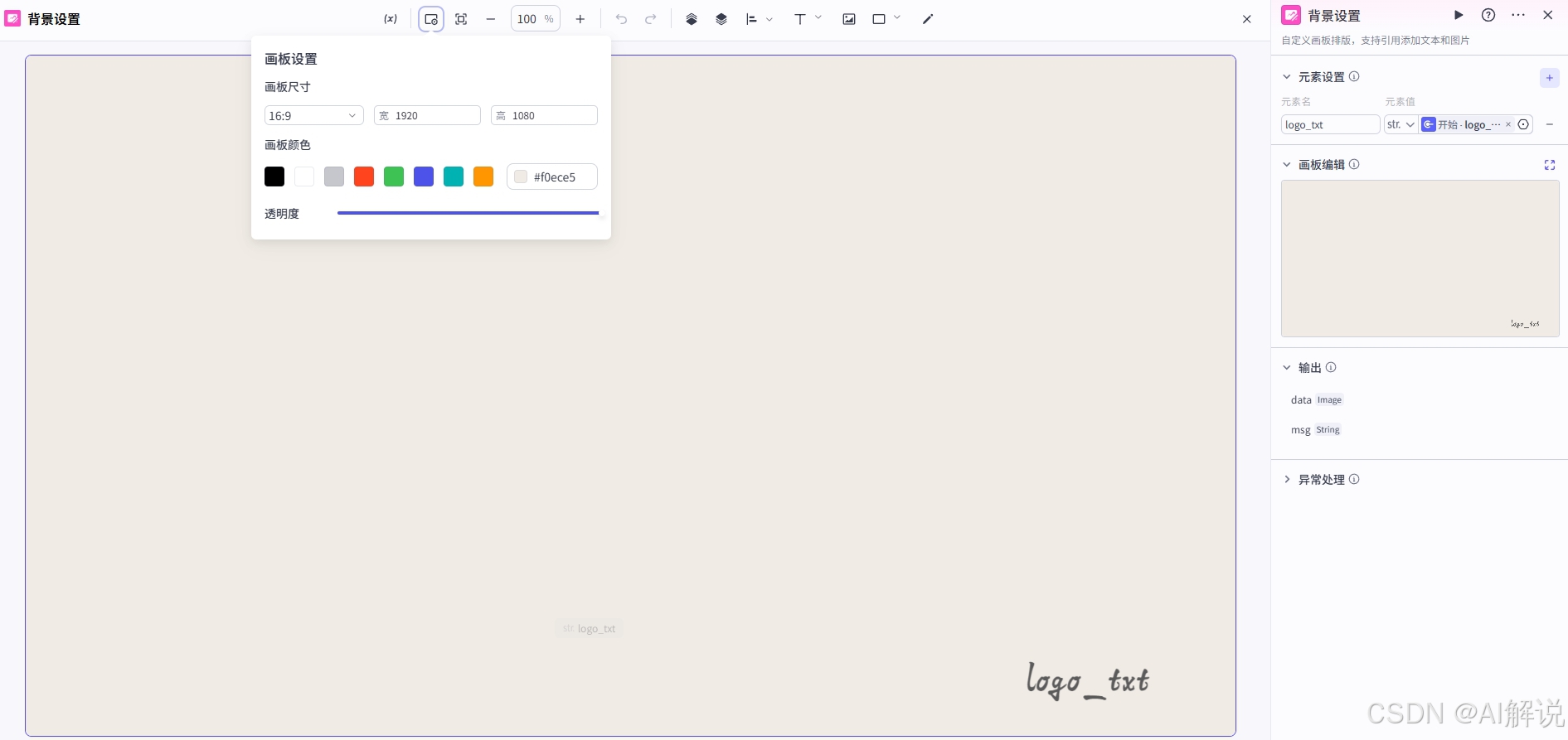
3.11 剪映小助手数据生成-背景图片信息:
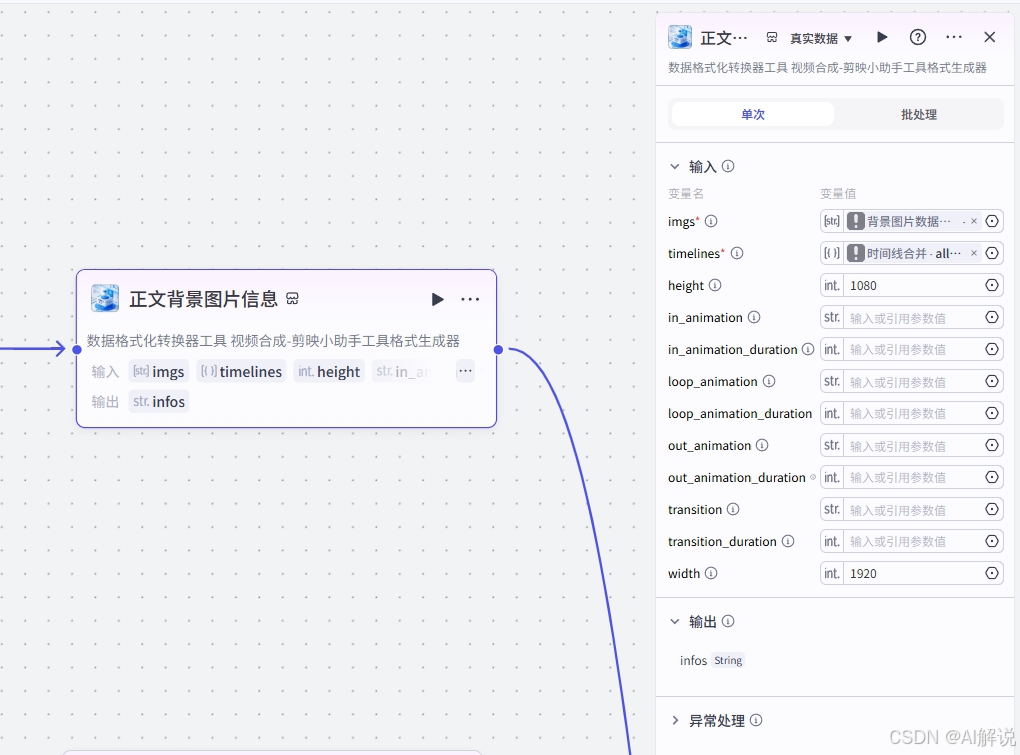
3.12 剪映小助手数据生成-开场素材:
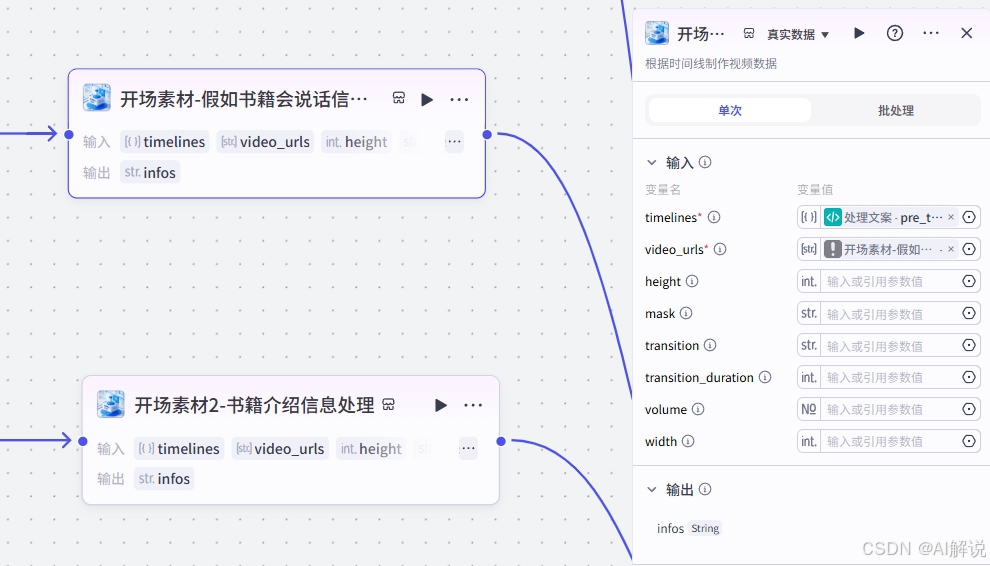
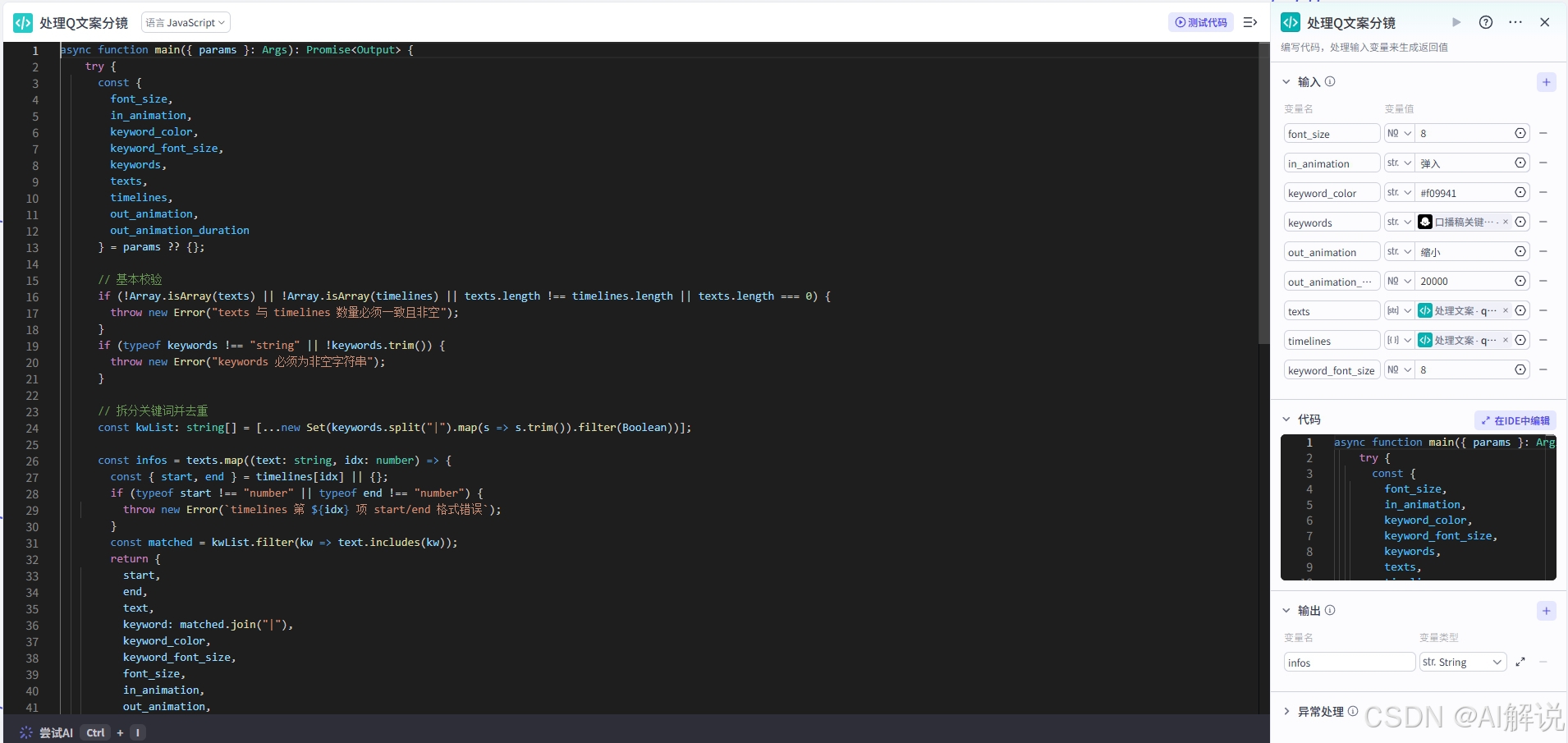
3.13 代码节点-处理Q(A)文案分镜:
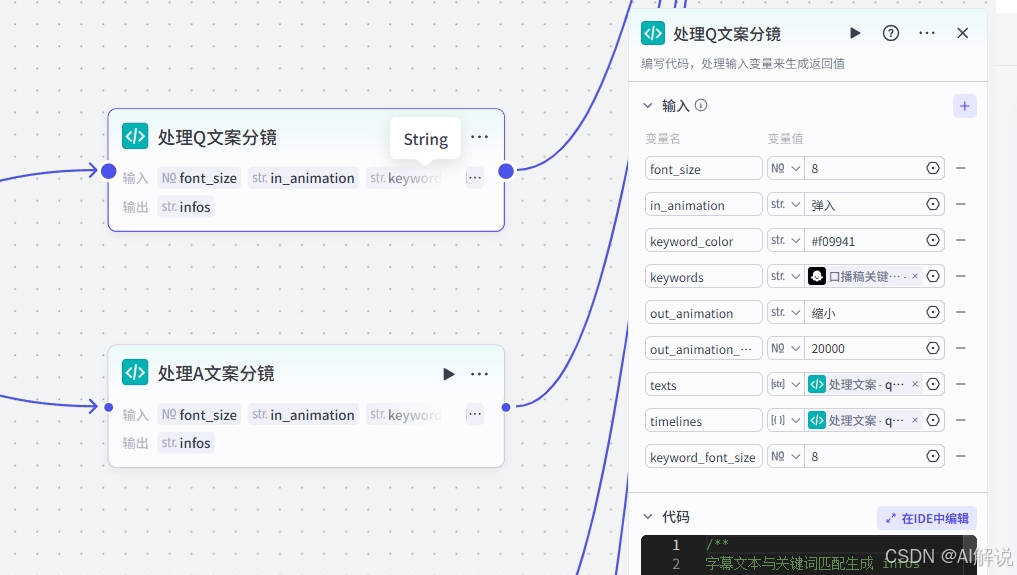
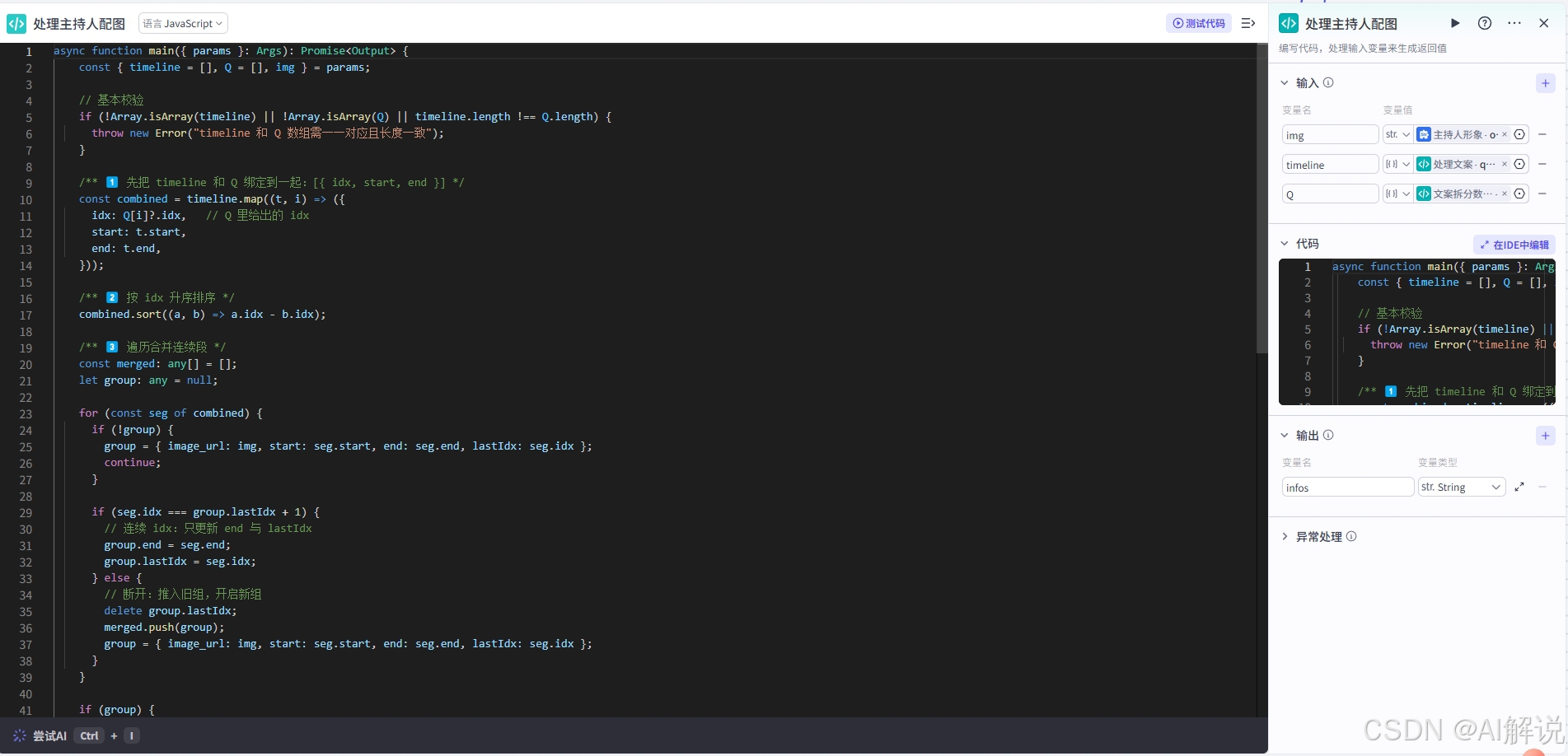
3.14 代码节点-处理主持人(书籍)配图:
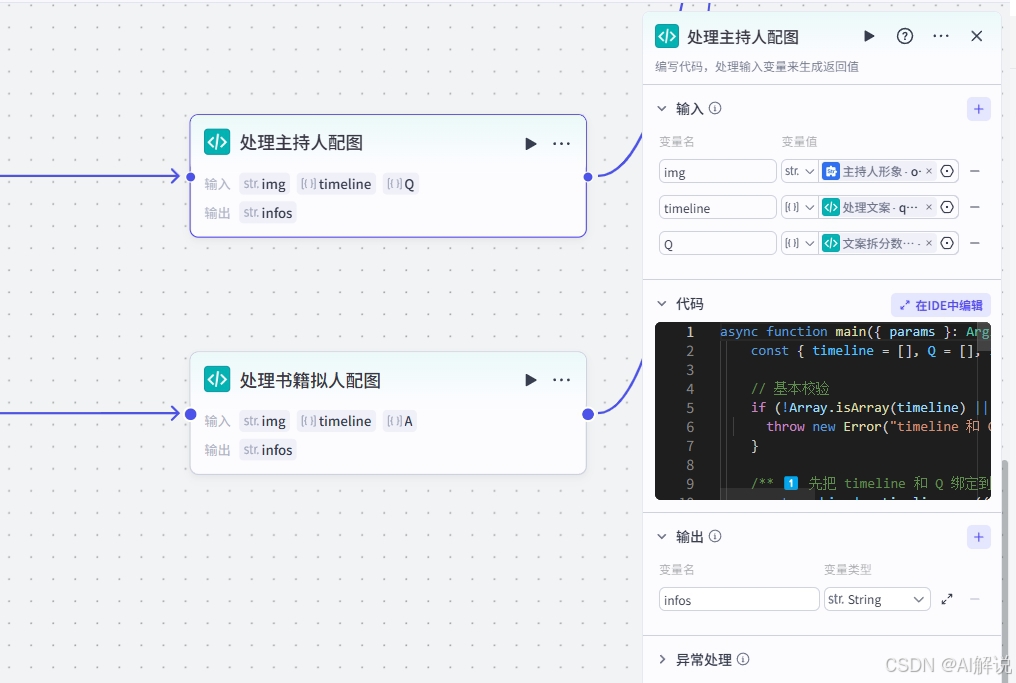
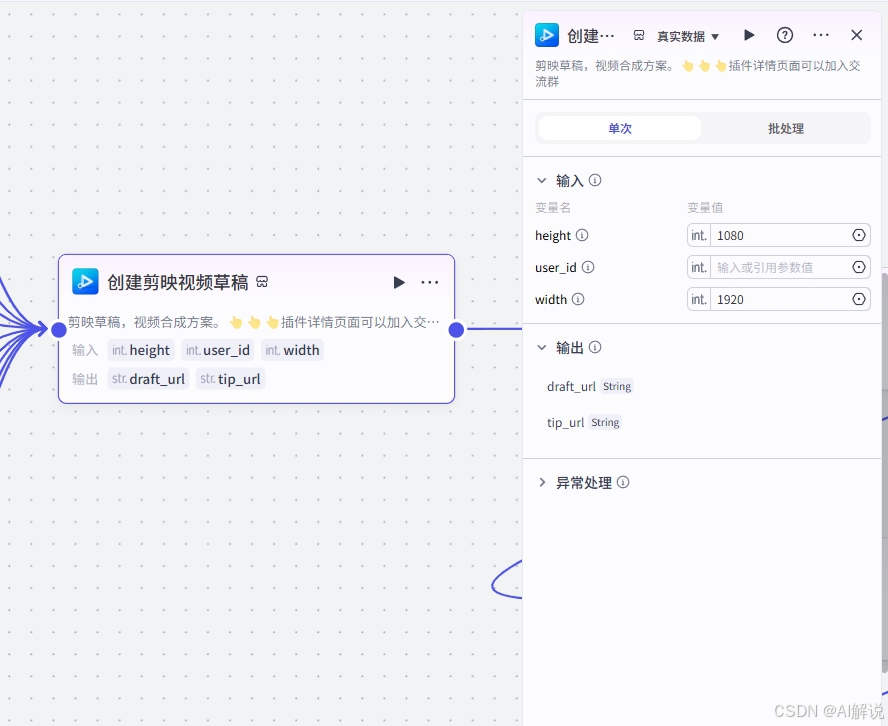
3.15 创建剪映草稿:
3.16 将所有元素添加进草稿:
3.17 结束节点:
工作流的最终节点,用于返回草稿的链接。
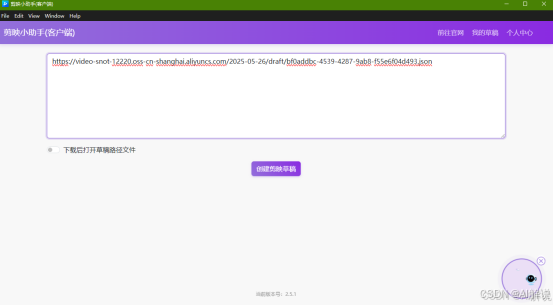
3.18 剪映小助手下载预览文件
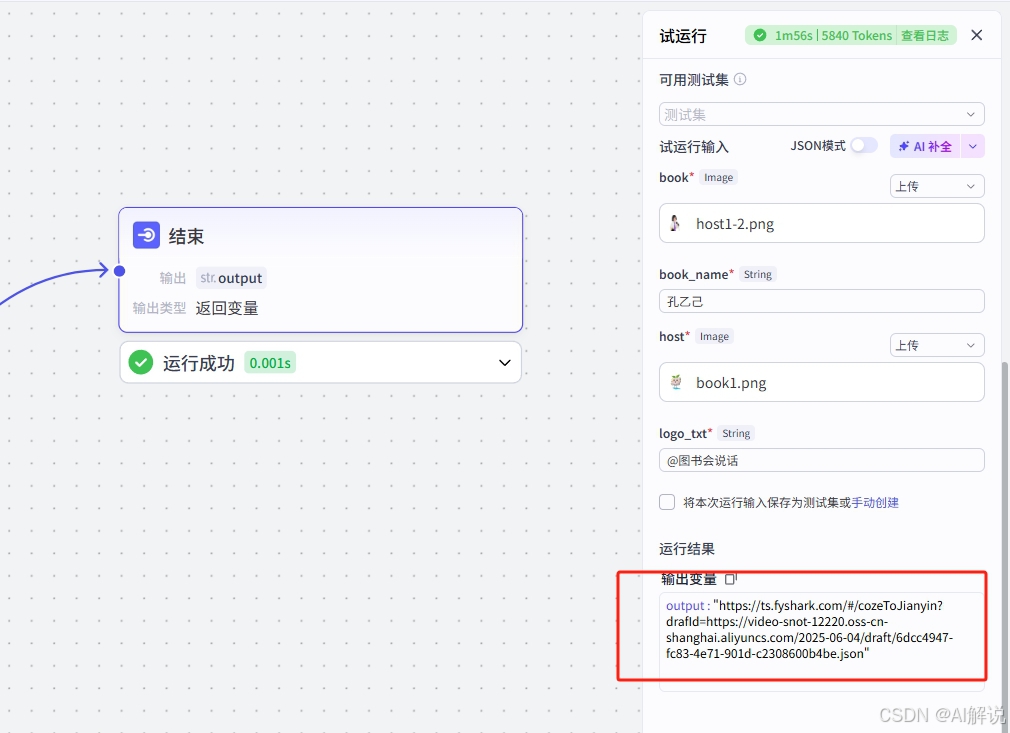
运行完成后,复制output链接,通过剪映小助手下载素材文件,最后打开剪映即可发布。
3.20代码
1.文案拆分数据归一化
async function main({ params }: Args): Promise<Output> {
const ret: {
preWenan: string[];
Q: { role: string; idx: number; content: string }[];
A: { role: string; idx: number; content: string }[];
} = {
Q: [],
A: [],
preWenan: ["假如书籍会说话", '今日对话', params.book_name]
};
try {
// 参数校验
if (!Array.isArray(params.roleDialogs)) {
throw new Error("roleDialogs字段必须是数组");
}
for (const item of params.roleDialogs) {
if (!item || typeof item.role !== "string" || !Array.isArray(item.dialogs)) {
continue;
}
const role = item.role;
const dialogs = item.dialogs;
for (const dialog of dialogs) {
if (
typeof dialog.role === "string" &&
typeof dialog.content === "string" &&
typeof dialog.idx === "number"
) {
const entry = {
role: dialog.role,
idx: dialog.idx,
content: dialog.content
};
if (role === "Q") {
ret.Q.push(entry);
} else if (role === "A") {
ret.A.push(entry);
}
}
}
}
} catch (e) {
// 错误处理,返回空结构
return {
preWenan: [],
Q: [],
A: []
};
}
return ret;
}
2. 处理文案
async function main({ params }: Args): Promise<Output> {
const ret: any = {
pre_timeline1: [params.pre_timeline.at(0)],
pre_timeline2: [params.pre_timeline.at(1)],
pre_book_timeline: [
{
start: params.pre_timeline.at(2).start - 500_000,
end: params.pre_timeline.at(2).end,
},
],
pre_timeline2_all: [
{
start: params.pre_timeline.at(1).start,
end: params.pre_timeline.at(2).end,
},
],
};
const { roleWenanTimeline = [] } = params;
// 容器初始化
const qWenan: string[] = [];
const aWenan: string[] = [];
const qTimelines: { start: number; end: number }[] = [];
const aTimelines: { start: number; end: number }[] = [];
// 第一组 → q,第二组 → a
roleWenanTimeline.forEach((group: any, idx: number) => {
const tgtWenan = idx === 0 ? qWenan : aWenan;
const tgtTlines = idx === 0 ? qTimelines : aTimelines;
(group.wenan ?? []).forEach((w: string) => tgtWenan.push(w));
(group.timelines ?? []).forEach((tl: any) =>
tgtTlines.push({ start: tl.start, end: tl.end })
);
});
// 写回到 ret
Object.assign(ret, { qWenan, aWenan, qTimelines, aTimelines });
return ret;
}
3.处理Q文案分镜
async function main({ params }: Args): Promise<Output> {
try {
const {
font_size,
in_animation,
keyword_color,
keyword_font_size,
keywords,
texts,
timelines,
out_animation,
out_animation_duration
} = params ?? {};
// 基本校验
if (!Array.isArray(texts) || !Array.isArray(timelines) || texts.length !== timelines.length || texts.length === 0) {
throw new Error("texts 与 timelines 数量必须一致且非空");
}
if (typeof keywords !== "string" || !keywords.trim()) {
throw new Error("keywords 必须为非空字符串");
}
// 拆分关键词并去重
const kwList: string[] = [...new Set(keywords.split("|").map(s => s.trim()).filter(Boolean))];
const infos = texts.map((text: string, idx: number) => {
const { start, end } = timelines[idx] || {};
if (typeof start !== "number" || typeof end !== "number") {
throw new Error(`timelines 第 ${idx} 项 start/end 格式错误`);
}
const matched = kwList.filter(kw => text.includes(kw));
return {
start,
end,
text,
keyword: matched.join("|"),
keyword_color,
keyword_font_size,
font_size,
in_animation,
out_animation,
out_animation_duration
};
});
return { infos: JSON.stringify(infos) };
} catch (e: any) {
return { infos: "[]", error: String(e.message || e) } as any;
}
}
4.主持人配图
async function main({ params }: Args): Promise<Output> {
const { timeline = [], Q = [], img } = params;
// 基本校验
if (!Array.isArray(timeline) || !Array.isArray(Q) || timeline.length !== Q.length) {
throw new Error("timeline 和 Q 数组需一一对应且长度一致");
}
/** 1️⃣ 先把 timeline 和 Q 绑定到一起:[{ idx, start, end }] */
const combined = timeline.map((t, i) => ({
idx: Q[i]?.idx, // Q 里给出的 idx
start: t.start,
end: t.end,
}));
/** 2️⃣ 按 idx 升序排序 */
combined.sort((a, b) => a.idx - b.idx);
/** 3️⃣ 遍历合并连续段 */
const merged: any[] = [];
let group: any = null;
for (const seg of combined) {
if (!group) {
group = { image_url: img, start: seg.start, end: seg.end, lastIdx: seg.idx };
continue;
}
if (seg.idx === group.lastIdx + 1) {
// 连续 idx:只更新 end 与 lastIdx
group.end = seg.end;
group.lastIdx = seg.idx;
} else {
// 断开:推入旧组,开启新组
delete group.lastIdx;
merged.push(group);
group = { image_url: img, start: seg.start, end: seg.end, lastIdx: seg.idx };
}
}
if (group) {
delete group.lastIdx;
merged.push(group);
}
/** 4️⃣ 结果 JSON 字符串化返回 */
return { infos: JSON.stringify(merged) };
}
3.21 复盘智能体工作流流程
4. 资料领取
在使用大模型时若感觉体验不佳,很可能是提示词撰写方式有待优化。为此,我们整理了丰富的提示词模板与 Coze系列操作教程,涉及的代码和提示词、完整工作流程已同步至 Coze 空间,感兴趣的朋友可以私信微信详细了解~
5. 结语
通过这套 “如果书籍能说话” 的 Coze 工作流,我们不仅赋予了书籍 “声音”,更创造了一种全新的知识交互方式。无论是深度解析经典著作,还是收集个性化阅读建议,它都能让每一本书籍真正 “活” 起来。现在,快将这份教程付诸实践,让你的藏书成为会思考、能对话的智慧宝库。未来,也期待你探索更多创意玩法,打造独属于自己的书籍智能交互生态!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









