







目录
一、工具定位与目标
工具名称:微信爆款文章及配图自动生成器
核心目标:基于用户输入的文章标题,通过 COZE 平台实现微信爆款文章内容与高质量配图的一站式自动化生成,大幅降低公众号内容创作门槛,提升运营效率。
应用场景:
- 新媒体运营者快速产出日常推文
- 企业宣传部门批量生成品牌推广内容
- 个人创作者高效完成原创内容制作
二、核心功能模块设计
1. 爆款文章生成模块
- 智能标题优化:基于输入标题,结合热点、名人、网络热词等元素,生成多个高传播潜力的备选标题,并筛选最佳方案。
- 内容结构化创作:根据标题与创作思路,自动搭建文章框架(如总分总、故事引导型),填充行业案例、数据、金句等内容,支持自定义风格(幽默 / 专业 / 情感)与字数要求。
- 语言润色:通过自然语言处理技术优化文案,增强节奏感与可读性,适配微信用户阅读习惯。
2. 高质量配图生成模块
- 文生图技术应用:以最终选定标题为提示词,调用文生图插件生成主题契合的封面图,支持分辨率、色彩风格等参数调整。
- 图片智能匹配:基于文章关键词,从内置图库或第三方平台(如 Unsplash、图虫)筛选内文配图,确保图文强关联。
3. 自动化发布模块
- 公众号授权对接:通过
app_id与app_secret获取公众号权限,实现封面图上传、文章内容自动导入草稿箱,减少人工操作步骤。 - 多平台适配输出:生成内容自动适配微信排版格式,同时支持导出为 Markdown、HTML 等通用格式,便于分发至其他平台。
三、COZE 平台搭建流程
1. 触发与输入设计
- 指令触发:用户输入 “生成文章 + 标题”(如 “生成文章 2025 年职场晋升指南”),或通过界面 “快速生成” 按钮启动工具。
- 参数设置:支持在对话中追加指令(如 “风格:轻松幽默,字数:1500 字”),灵活调整输出结果。
2. 工作流核心节点配置
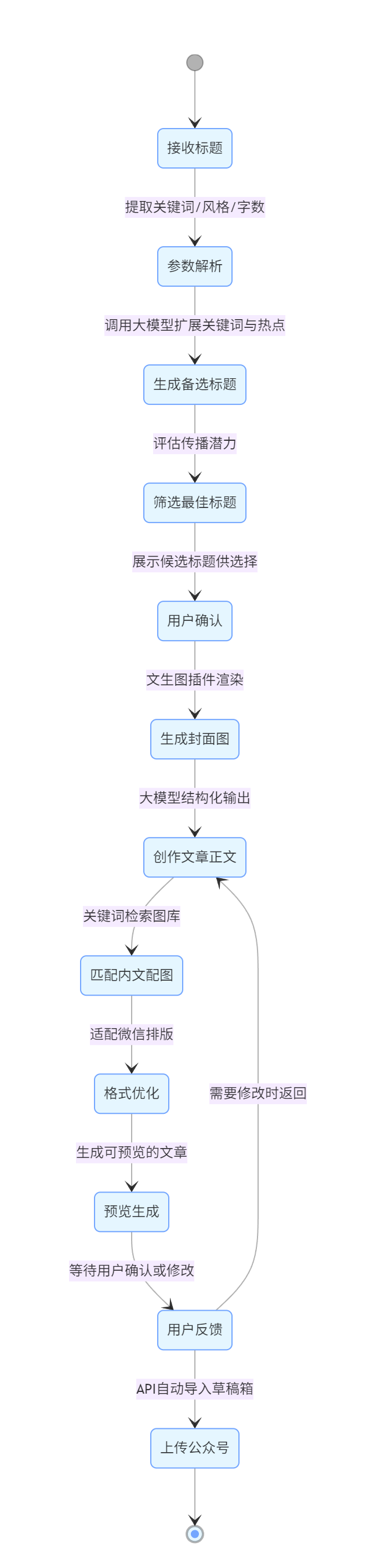
3. 关键节点实现细节
- 大模型提示词设计:
- 标题优化:“请基于‘{输入标题}’,结合近 7 天微博热搜、抖音爆款话题,生成 5 个包含数字、悬念、利益点的标题,并标注每个标题的引流策略。”
- 内容创作:“根据标题‘{选定标题}’与创作思路,以三段式结构展开文章,每段插入 1 个行业权威数据与 2 个用户痛点案例,语言风格保持口语化。”
- 文生图参数配置:
强制添加参数如--v 6.0(指定模型版本)、--style raw(高清细节),并在提示词中明确构图要求(如 “16:9 横版,科技感蓝紫色渐变背景”)。
四、技术实现与合规性
1. 技术要点
- 反同质化策略:通过动态调整大模型温度参数、引入个性化语料库,避免生成内容千篇一律。
- 性能优化:采用异步任务队列处理图片生成与文章创作,缩短整体响应时间。
2. 合规与安全
- 版权声明:明确标注文生图版权归属,支持用户替换为自有素材;文章内容生成基于公开数据与合法授权语料。
- 数据隐私:仅存储用户授权的公众号信息,操作日志 7 天后自动删除。
五、迭代与扩展方向
- AIGC 深度融合:接入多模态模型,支持 “标题 + 关键词 + 参考文章” 混合输入,提升内容定制化程度。
- 团队协作功能:增加多人协同编辑、审核流程,适配企业级内容生产场景。
- 数据看板:统计生成内容的阅读、转发数据,反向优化生成策略,形成创作 - 反馈闭环。
六、补充说明
1. 流程图补充说明
- 用户确认环节:在筛选最佳标题后增加用户确认步骤,允许用户手动调整或重新生成标题。
- 反馈循环:添加用户反馈机制,支持对生成内容不满意时返回修改,形成闭环流程。
- 预览功能:增加预览生成节点,在上传公众号前提供可视化预览效果。
2. 缺失内容补充
- 错误处理机制:在关键节点(如文生图失败、API 调用超时)添加重试逻辑与异常捕获,确保流程稳定性。
- 多模型切换:支持根据不同领域(如科技、财经、情感)自动切换专用大模型,提升生成内容专业性。
- 插件市场扩展:预留插件接口,未来可接入更多功能(如 AI 配音、SEO 优化)。
如需进一步细化某个模块,可和我交流、提供更多开发参数或配置细节。

















 391
391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









