







ElasticSearch分词器和聚合,数据的丰富和去重
- 1. analyzer
- 2. Aggregations
- 3. [Observability:使用 Elastic Stack 分析地理空间数据 ](https://blog.youkuaiyun.com/UbuntuTouch/article/details/106531939)
- 4. [把MySQL数据导入到Elasticsearch中](https://blog.youkuaiyun.com/UbuntuTouch/article/details/101691238)
- 5. Logstash处理重复的文档
- 6. 数据的丰富
- 7. 寄语:程序员之所以犯错误,不是因为他们不懂,而是因为他们自以为什么都懂。
1. analyzer
1.1. 什么是analysis?
- 分析是Elasticsearch在文档发送之前对文档正文执行的过程,以添加到反向索引中(inverted index)
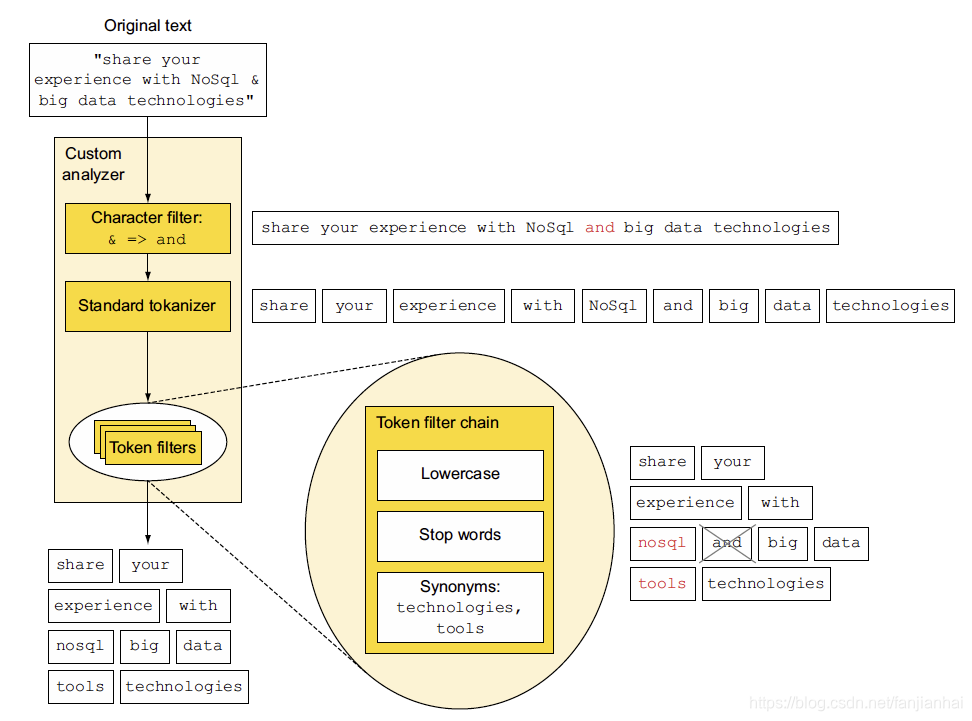
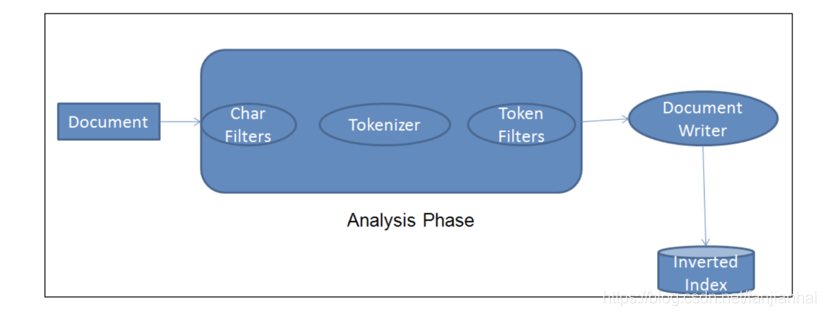
- 每当一个文档被ingest节点纳入,它需要经历如下的步骤,才能最终把文档写入到Elasticsearch的数据库中
1.2. 如何定义一个定制的分析器
-
在这里我们主要运用现有的plugin来完成定制的分析器
DELETE blogs PUT blogs { "settings": { "analysis": { "char_filter": { "xschool_filter": { "type": "mapping", "mappings": [ "X-Game => XGame" ] } }, "analyzer": { "my_content_analyzer": { "type": "custom", "char_filter": [ "xschool_filter" ], "tokenizer": "standard", "filter": [ "lowercase", "my_stop" ] } }, "filter": { "my_stop": { "type": "stop", "stopwords": ["so", "to", "the"] } } } }, "mappings": { "properties": { "content": { "type": "text", "analyzer": "my_content_analyzer" } } } }
1.3. 中文分词器
2. Aggregations
2.1. Bucket aggregation
-
我们将重点介绍直方图(histogram),范围(range),过滤器(filter)和术语(terms)等存储桶聚合 -
Bucket aggregation是一种把具有相同标准的数据分组数据的方法 -
案例1
-
样例数据
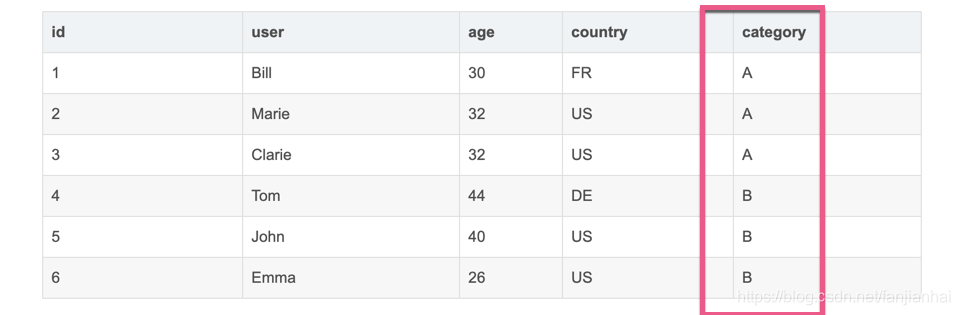
-
统计同一个category中同一个国家的平均年龄
GET users/_search { "size": 0, "aggs": { "categories": { "terms": { "field": "category" }, "aggs": { "countries": { "terms": { "field": "country" }, "aggs": { "average_age": { "avg": { "field": "age" } } } } } } } } -
结果统计
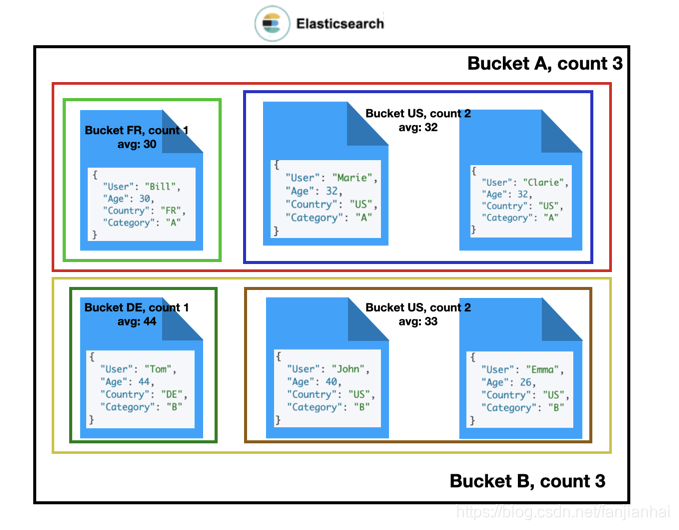
-
-
案例2
-
过滤聚合(角色为defender和角色为forward的平均分)
GET sports/_search { "size": 0, "
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









