







文章目录
- 1. scala简介
- 2. scala基本语法
- 3. Scala之面向对象
- 4. Scala模式匹配和样例类
- 5. 高阶函数
- 6. Scala中的泛型
- 7. Scala中的隐式转换
- 8. 深入理解Scala中的隐式转换系统
- 9. 其他零碎知识点
- 10. 书山有路勤为径,学海无涯苦作舟
1. scala简介
1.1. 什么是scala
- Scala是一种多范式的编程语言,其设计的初衷是要
集成面向对象编程和函数式编程的各种特性。Scala运行于Java平台(Java虚拟机)(Scala自己的编译器还不够成熟),并兼容现有的Java程序
1.2. 为什么要学习scala
- 优雅: 这是框架设计师的第一个要考虑的问题,框架的用户是应用开发程序员,API是否优雅直接影响用户的体验。
- 速度快: Scala语言表达能力强,一行代码抵得上Java多行,开发速度快;
Scala是静态编译的,所有和JRuby,Groovy比起来速度会快很多。 能融合到Hadoop生态圈: Hadoop现在是大数据事实标准,Spark并不是要取代Hadoop,而是要完善Hadoop生态。JVM语言大部分可能会想到Java,但是Java做出来的API太丑,或者想实现一个优雅的API太费劲。
1.3. Scala官网
1.4. Spark,Kafka,Flink都是由Scala语言编写
1.5. Java能做的,Scala都能做,Java不能做的,Scala也能做。Scala可以任意调用Java的接口
1.6. Scala编译器和插件的安装
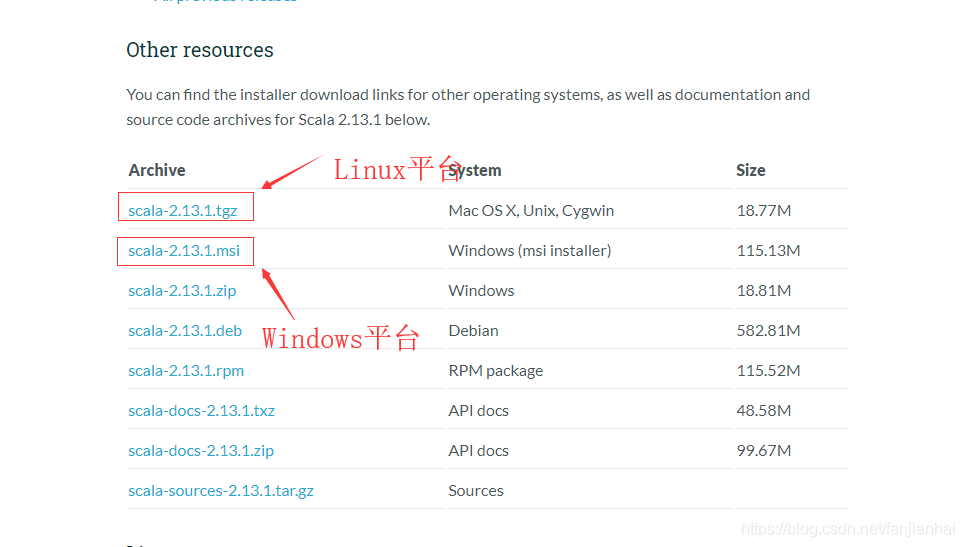
2. scala基本语法
2.1. 变量的声明
- 使用
val定义的变量值是不可以改变的,相当于Java里用final修饰的变量- 例:val i = 1
- 使用
var定义的变量是可变的,在Scala中鼓励使用val- 例:var s = "hello”
- scala编译器会自动推断变量的类型,必要的时候可以指定类型,变量名在前,类型在后
- 例: val s: String = “hello scala”
2.2. 常用类型
- scala和java一样,有7种数值类型
Byte、Char、Short、Int、Long、Float、Double(无包装类型)和一个Boolean类型
2.3. 循环语句
-
for循环1
val arr = Array[Int](1, 2, 3) for (e <- arr) println(e) -
for循环2
for (i <- 0 to 3) print(i + " ") println("\n*****") for (i <- 0 until 3) print(i + " ")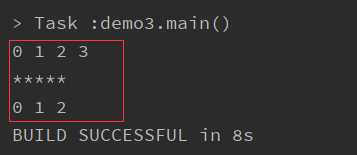
-
高级for循环
注意1:每个生成器都可以带一个条件,注意: if前面没有分号注意2:与java中for循环结构上的区别
for (i <- 1 to 3; j <- 1 to 3 if i != j) { print((10 * i + j) +" ") }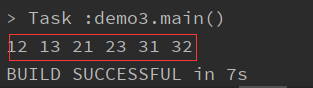
-
for循环推导式1
如果for循环的循环体以yield开始,则该循环会构建出一个集合,每次迭代生成集合中的一个值
val v = for (j <- 1 to 10) yield j * 100 println(v)
-
for 循环推导式2
遍历数组通过索引获取元素时,使用小括号括起来
val arr = Array[String]("a","b","c","d") for (i <- 0 until arr.length) println(arr(i))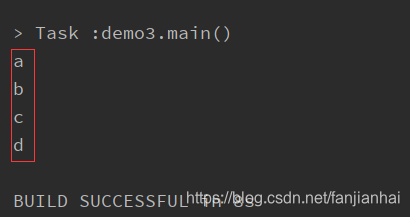
2.4. 判断语句
-
判断x的值,将结果赋予y
val x = 1 val y = if (x > 0) 1 else -1 -
混合表达式,将结果赋予z
val z = if(x > 1) 1 else "error" -
缺失else,相当于 if(x > 2) 1 else ()
注意:在scala中每个表达式都有值,scala中有个Unit类,写做(), 相当于Java中的void
val x = -1 val m = if(x > 2) 1 println(m)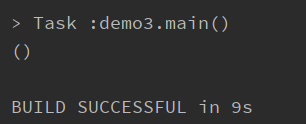
-
if 和 else if
val k = if(x < 0) 0 else if(x >= 1) 1 else -1 -
块表达式
注意:在scala中{}中可包含一系列表达式,块中最后一个表达式的值就是块的值
val result = { if(x < 0) { -1 } else if(x >= 1) { 1 } else { "error" } }
2.5. Scala操作符重载
-
Scala中的±*/%等操作符的作用和Java一样,位于&|^>><<也一样。只是一点特别的:
这些操作符实际上是方法val a = 1 + 2 val b = 1.+(2) println(a) println(b)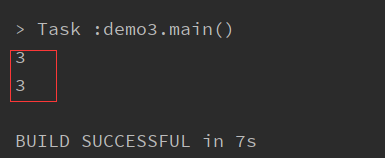
2.6. Scala中定义方法
-
定义既有参数,又有返回值方法
注意: 函数的返回类型,可以不写,但是在递归方法中必须指明返回类型
def m(x: Int): Int = x*x def m(x: Int)= x*x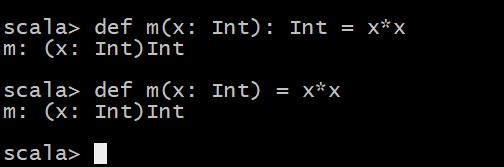
- 定义没有返回值的方法
def m(x: Int, y: Int): Unit = println(x + y) def m(x: Int, y: Int) = println(x + y) // 如果没有返回值,也可以不用写 def m(x: Int, y: Int) { println(x + y)}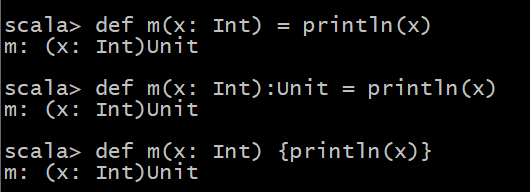
2.7. Scala中定义函数
-
定义有名字的函数
- 没有指定返回类型(简版)
val f = (x: Int) => x * 10 val f = (x: Int,y: Int) => x * y + 10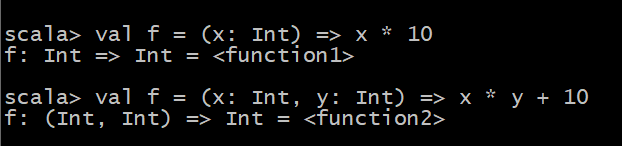
- 指定了返回类型(完整版)
注意:在Scala中,元组的下标是从1开始,python中是从0开始,r._1 获取到的是3.0
val f1: Int => Int = {x => x * x} // 注意:中间的Int是返回值 val f2: Int => String ={i => i.toString} // 注意: String是返回值 val f3: (Int, Double) => (Double, Int) = {(x, y) => (y, x)} // 注意:函数输入 => 函数输出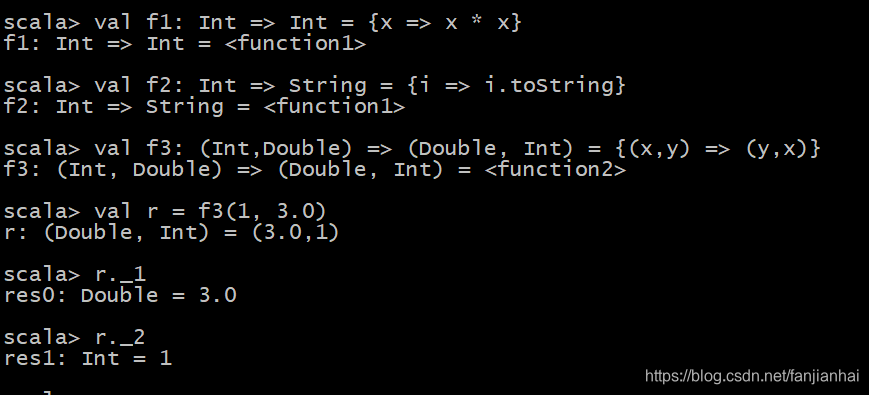
-
定义匿名函数
(x: Int) => x * 10 (x: Int,y: Int) => x * y + 10
-
函数作为参数传入方法
注意:匿名函数作为参数传入方法时候的简写原则

2.8. 方法转换成函数,方法作为参数传入方法
-
注意: 将方法名传入方法的本质是将方法转换成了函数
2.9. Scala中方法和函数的总结
- 在Java中方法和函数是一样的,在Scala中方法和函数是有区别的,不能混为一体
- 函数和方法具有的功能是不一样的
函数的标识 => ,但有=> 不一定是函数,例如,case语句中的=>- 函数是可以作为参数传入到方法里面的,方法也可以作为参数传入到方法里面,其本质还是转换成了函数
2.10. Scala中的数组
在Scala中,数组分为定长数组和变长数组
2.10.1. 定长数组

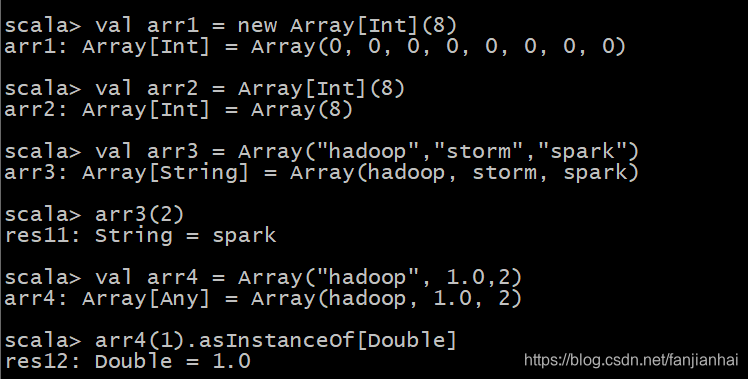
2.10.2. 变长数组

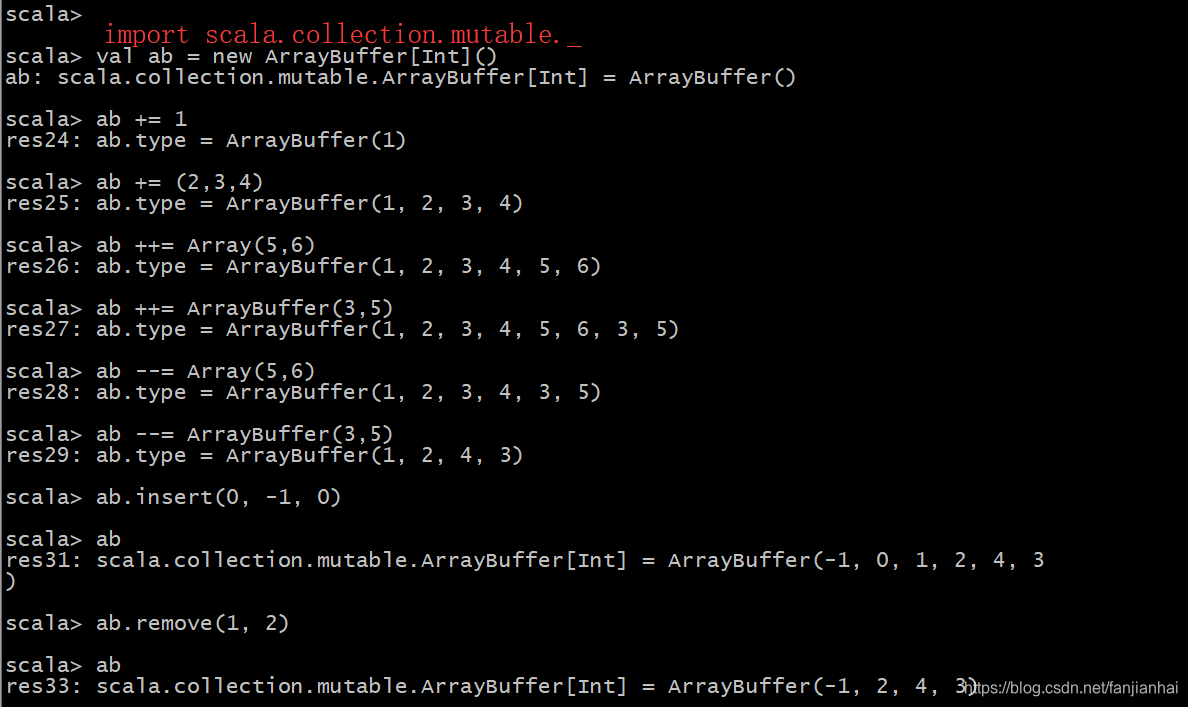
2.10.3. 数组遍历

2.10.4. 数组转换

2.10.5. 常用方法

2.11. Scala中的映射
在Scala中,把哈希表这种数据结构叫做映射,Java中叫Map,Python中叫字典
2.11.1. 构建映射

2.11.2. 常用方法
- m.getOrElse(“a”,-1) // 底层通过模式匹配实现 不会抛异常
2.12. Scala中的元组
在Scala中,元组类似Python中的元组
- 定义元组

2.13. Scala中的集合
Scala的集合有三大类:序列Seq、集Set、映射Map,所有的集合都扩展自Iterable特质,在Scala中集合有可变(mutable)和不可变(immutable)两种类型
2.13.1. 列表

2.13.2. Set

2.13.3. Map
2.14. 并行集合
- 并行集合可以由原来的单线程变成为多个线程一起工作
- 将普通集合转化成为并行集合:
arr(非并行) arr.par(并行集合)
3. Scala之面向对象
3.1. 类
3.1.1. 类的定义

3.1.2. 构造器

3.2. 对象
3.2.1. Scala伴生对象

3.2.2. Scala单例对象

3.2.3. apply方法

3.3. 继承

3.4. 偏函数

3.5. Option类型
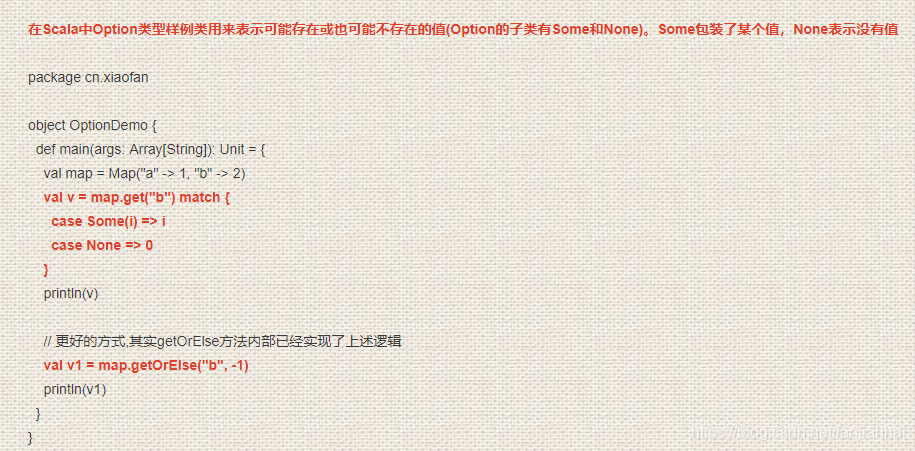
4. Scala模式匹配和样例类
4.1. 模式匹配
Scala有一个十分强大的模式匹配机制,可以应用到很多场合:如switch语句、类型检查等。并且Scala还提供了样例类,对模式匹配进行了优化,可以快速进行匹配
4.1.1. 匹配字符串

4.1.2. 匹配类型

4.1.3. 匹配数组、元组


4.2. 样例类

5. 高阶函数
Scala混合了面向对象和函数式的特性,我们通常将可以做为参数传递到方法中的表达式叫做函数。在函数式编程语言中,函数是“头等公民”,高阶函数包含:作为值的函数、匿名函数、闭包、柯里化等等。
5.1. 柯里化
柯里化指的是将原来接受两个参数的方法变成新的接受一个参数的方法的过程(比原来需要传递的参数少)

- 柯里化+隐士转换案例

6. Scala中的泛型
6.1. 泛型的介绍

6.2. 定义泛型类

6.3. 定义泛型方法

6.4. Type与Class、ClassTag与TypeTag
- Java和scala是基于JVM的,在虚拟机内部,并不关心泛型或类型系统。在JVM上,泛型参数类型T在运行时是被擦除掉的, 编译器把T当作Object来对待,所以T的具体信息是无法得到的。
- Manifest是scala2.8引入的一个特质,用于编译器在运行时也能获取泛型类型的信息。为了使得在运行时得到T的信息,scala需要额外通过Manifest来存储T的信息,并作为参数用在方法的运行时上下文。
- 在引入Manifest的时候,还引入了一个更弱一点的ClassManifest,所谓的弱是指类型信息不如Manifest那么完整。
不过scala在2.10里用TypeTag替代了Manifest,用ClassTag替代了ClassManifest。 ClassTag运行时指定在编译的时候无法指定的类型信息。- 详细链接1
- 详细链接2
7. Scala中的隐式转换
7.1. 协变(covariance)和逆变(contravariance)
-
注意1:Java中是不存在协变和逆变的,否则Java的类型安全就会被破坏了! -
注意2:Scala规定,协变类型只能作为方法的返回类型,而逆变类型只能作为方法的参数类型。 -
注意3:在声明Scala的泛型类型时,“+”表示协变,而“-”表示逆变。 -
注意4:类型通配符是指在使用时不具体指定它属于某个类,而是只知道其大致的类型范围,通过”_ <:” 达到类型通配的目的
7.2. Scala上下界绑定upperbound
- S <: T
- 这是类型上界的定义,也就是S必须是类型T的子类(或本身,自己也可以认为是自己的子类)。
- U >: T
- 这是类型下界的定义,也就是U必须是类型T的父类(或本身,自己也可以认为是自己的父类)。

7.3. 视图绑定viewBound
- [B <% A] ViewBound 表示B类型要转换成A类型,需要一个隐式转换函数, 可以认为view(视图绑定) bounds是上下边界的加强和补充,语法为:"<%",要用到implicit进行隐式转换
- 等价写法
def method [A <% B](arglist): R = ...
def method [A](arglist)(implicit viewAB: A => B): R = ...

7.4. 上下文绑定contextBound
- [B : A] ContextBound 需要一个隐式转换值
- 等价写法
def foo[A](a:A)(implicit b:B[A]) = g(a)
def foo[A : B](a: A) = g(a)

- 案例2

8. 深入理解Scala中的隐式转换系统
8.1. Scala中的两种隐式转换机制以及隐式视图的定义方式
package com.xiaofan
object demo03 {
def main(args: Array[String]): Unit = {
// 隐式值
// 给方法提供参数
implicit val str = "Scala"
def fun(implicit arg: String) = println("hello: " + "\t" + arg)
fun(str)
fun
// 隐式视图
// 隐式视图是指把一种类型自动转换成另外一种类型,进而使用另外一种类型中的属性和方法,从而满足表达式的要求.
def g(arg: String) = println("hello: " + "\t" + arg)
implicit def int2String(arg: Int) :String = arg.toString
g(100)
}
}
8.2. Scala中的隐式绑定可能所处的位置以及如何更好的使用隐式转换
在Scala当中,要想使用隐式转换,必须标记为implicit关键字,implict关键字可以用来修饰参数(隐式值与隐式参数)、函数(隐式视图)、类(隐式类)、对象(隐式对象).
package com.xiaofan
import java.io.File
import scala.io.Source
class RichFile(var file: File) {
def read(): String = Source.fromFile(file).mkString
}
class S1(path: String) extends File(path)
object S1 {
implicit def filetoRichFile(arg: File) = new RichFile(arg)
}
object App {
def main(args: Array[String]): Unit = {
val s1: S1 = new S1("d:\\abc.txt")
// 伴生对象调用自己的方法
val t1: String = S1.filetoRichFile(s1).read()
// 会检查类中(包含伴生对象中是否有符合条件的隐式转换)
val t2 = s1.read()
println(t1)
println(t2)
}
}
8.3. Scala中的隐式转换相关操作规则
package com.xiaofan
object App {
def main(args: Array[String]): Unit = {
// 隐式值和隐式参数
implicit val str = "Spark"
def fun(implicit arg: String) = println(arg)
fun
// 隐式对象
trait S1 {
def g(): Unit
}
implicit object S2 extends S1 {
override def g(): Unit = println("Hello Spark!")
}
def fun2(arg1: String)(implicit arg2: S1) = println("隐式类的定义具体见后面博客!")
fun2("Scala")(S2)
fun2("Java")
}
}
8.4. Scala中的隐式参数
package com.xiaofan
object S1 {
implicit val str = "Spark"
}
object App {
def main(args: Array[String]): Unit = {
def fun(arg1: String)(implicit arg2: String) = println(s"${arg1}\t${arg2}")
fun("Scala")("Spark")
import S1.str
fun("Java")
}
}
8.5. Scala中的隐式类
package com.xiaofan
import java.io.File
import scala.io.Source
object S1 {
implicit class RichFile(file: File) {
def read(): String = Source.fromFile(file.getPath).mkString
}
}
object App {
def main(args: Array[String]): Unit = {
val file = new File("d:\\abc.txt")
import S1.RichFile
// 引入了隐式类
val text:String = file.read()
println(text)
}
}
8.6. Scala中的隐式对象
package com.xiaofan
object App {
def main(args: Array[String]): Unit = {
trait S1 {
def fun(): Unit
}
implicit object S2 extends S1 {
override def fun(): Unit = println("Spark")
}
def g(arg1: String)(implicit arg2: S1) = println("隐式对象的解析!!!")
g("scala")
}
}
8.7. Predef类中的implicitly方法的用法介绍以及Ordering类型转化为Oredered类型的方式
Predef类中的implicitly方法可以获取参数实际运行时具体的数值
package com.xiaofan
object demo04 {
def main(args: Array[String]): Unit = {
val str: String = implicitly("Spark")
val i: Int = implicitly(10)
println(str)
println(i)
println(" ============================= ")
val aa = new Bigger[Int](10, 20)
println(aa.bigger)
}
}
class Bigger[T: Ordering](var first: T, var second: T) {
def bigger(implicit m: Ordering[T]) = {
if(implicitly(m).compare(first, second) > 0) first else second
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









