







 本文深入讲解Apache Spark的核心特性,包括快速内存迭代计算、易用的API接口、广泛的集成能力及多样的部署方式。涵盖从安装配置到集群搭建,再到代码开发与任务提交全流程,适合技术人员全面掌握Spark。
本文深入讲解Apache Spark的核心特性,包括快速内存迭代计算、易用的API接口、广泛的集成能力及多样的部署方式。涵盖从安装配置到集群搭建,再到代码开发与任务提交全流程,适合技术人员全面掌握Spark。
文章目录
1. 官网

1.1. spark学习路线(技术人员的学习路线)
- what、how、why、use、运维(源码理解)
1.2. 什么是spark?
- 内存迭代式计算,利用DAG有向无环图
- 运行快:在硬盘比Hadoop快10倍,在内存比Hadoop快100倍
- 易用性:代码写的少,Scala,Python,Java, R… Hadoop 的 mr就一种
- 通用行:集成了core、sql、streaming、Mllib、graphx,在一个应用中可以随意组合
- 无处不在:数据源多种(hdfs、hbase、mysql、文件…),计算平台多种(standalone,YARN,mesos)
1.3. how(部署)
- 下载安装包
- 上传包
- 解压
- 重命名
- 修改环境变量
- 修改配置文件(重要、去官方文档看配置文件、所有集群跑不起来都在这里,通过log文件查看)
- 下发(scp)
- 修改其他机器的配置(可选)
- 格式化(可选)
- 启动集群(注意依赖关系)
1.4. standalone模式的spark集群搭建
- HA模式
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=mini1:2181,mini2:2181,mini3:2181 -Dspark.deploy.zookeeper.dir=/spark"
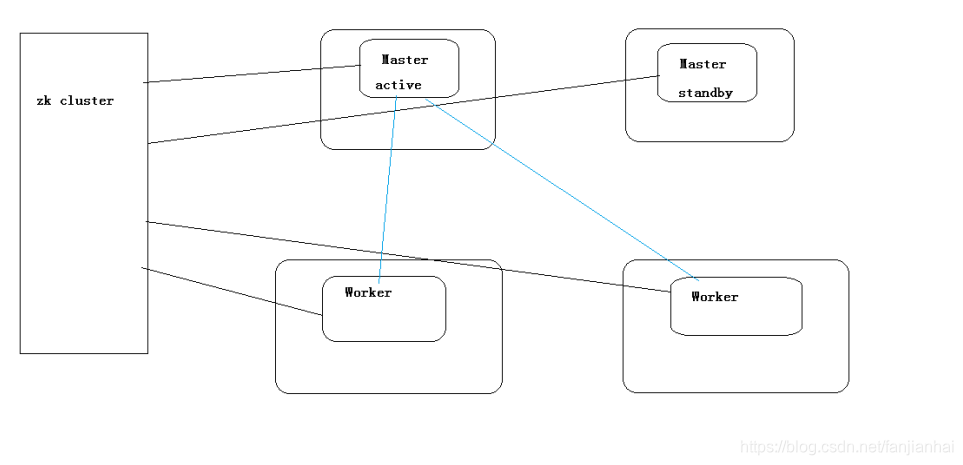
1.5. 运行spark-shell的两种方式
- 直接运行
spark-shell- 单机通过多线程跑任务, 只运行一个进程叫submit,任务不会提交到集群
- 运行spark-shell --master
spark://192.168.1.28:7077(注意:这里可以替换yarn,mesos的相关配置)- 将任务运行在集群中,运行submit在master上,运行executor在worker上
- 其他详细介绍

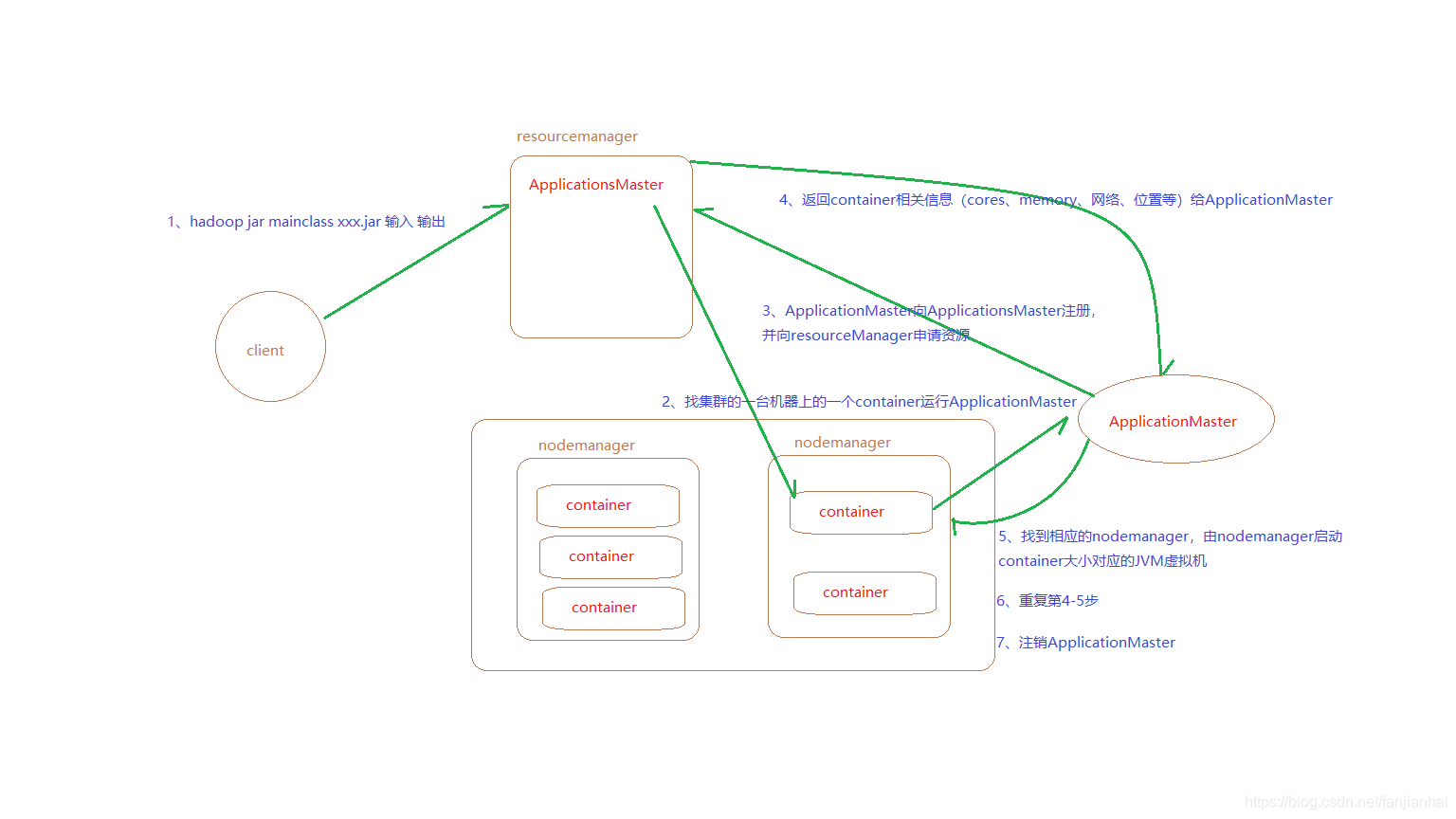
1.6. yarn调度框架示意图
- 组件解释
- container:封装了内存,CPU,磁盘,网络IO的一个Bean
- container是由resourcemanager创建好,然后序列化后交给nodemanager反序列化
- 申请资源是resourcemanager和nodemanager之间进行交互,任务调度是由resourcemanager当中的ApplicationsMaster来管理,ApplicationManager管理每个任务,ApplicationsManager管理每一个ApplicationManager。
1.7. 用api开发spark代码
-
gradle依赖
plugins { id 'java' id 'scala' } version '1.0.0' sourceCompatibility = 1.8 sourceSets { main { scala { srcDirs = ['src/main/scala', 'src/main/java'] } java { srcDirs = [] } } test { scala { srcDirs = ['src/test/scala', 'src/test/java'] } java { srcDirs = [] } } } repositories { mavenCentral() maven { url 'http://maven.aliyun.com/nexus/content/groups/public/' } maven { url 'https://maven.ibiblio.org/maven2/' } } dependencies { compile group: 'org.scala-lang', name: 'scala-library', version: '2.12.6' //scala基本库 testCompile group: 'org.scalatest', name: 'scalatest_2.12', version: '3.0.5' //scala测试相关的依赖 compile group: 'org.apache.spark', name: 'spark-core_2.12', version: '2.4.1' compile group: 'org.apache.spark', name: 'spark-sql_2.12', version: '2.4.1' compile group: 'org.apache.spark', name: 'spark-streaming_2.12', version: '2.4.1' compile group: 'org.apache.spark', name: 'spark-streaming-flume_2.12', version: '2.4.1' compile group: 'org.apache.spark', name: 'spark-streaming-kafka-0-10_2.12', version: '2.4.1' compile group: 'org.apache.hadoop', name: 'hadoop-client', version: '2.7.6' //hadoop客户端库 } -
创建scala类
import org.apache.spark.SparkContext // 一切任务的起源,所有计算的开头(上下文) import org.apache.spark.SparkConf // spark的配置信息,相当于mr当中的那个conf,它会覆盖掉默认的配置文件,主要作用:设置应用名字、设置运行本地模式还是集群模式 -
写代码(参考官方文档)
-
注意1:注意两个关键词:transformation,action -
注意3:自动生成变量名且带变量类型快捷键:Ctrl + Alt + v -
注意4:类继承关系快捷键 Ctrl + h -
注意5:如果在windows上运行,设置setMaster(“local[n]”),如果在线上运行,则去掉,在外部配置 -
代码1(scala版本)
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object WordCount { def main(args: Array[String]): Unit = { // 创建conf, 设置应用的名字和运行的方式, local[2]运行两个线程,产生两个结果文件 // 设置master为集群上的master(如 spark://mini1:7077,mini2:7077)时,只能打jar包丢到集群运行 val conf = new SparkConf().setAppName("WordCount").setMaster("local[2]") val sc = new SparkContext(conf) // IntelliJ IDEA scala 编程自动生成变量名且自带变量类型的设置方法 val file: RDD[String] = sc.textFile("hdfs://192.168.1.27:9000/words.txt") val words: RDD[String] = file.flatMap(_.split(" ")) val tuple: RDD[(String, Int)] = words.map((_, 1)) val result: RDD[(String, Int)] = tuple.reduceByKey(_ + _) val resultSort: RDD[(String, Int)] = result.sortBy(_._2, false) resultSort.foreach(println(_)) } } -
代码2(scala版本)
import org.apache.spark.SparkContext import org.apache.spark.rdd.RDD import org.apache.spark.sql.SparkSession object WordCount { def main(args: Array[String]): Unit = { val spark = SparkSession.builder().appName("WordCount").master("local[1]").getOrCreate() val sc: SparkContext = spark.sparkContext val result: RDD[(String, Int)] = sc.textFile("d://words.txt").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).sortBy(_._2, false) result.saveAsTextFile("d://word_output") } } -
代码3(python版本)
#!/usr/bin/python from pyspark import SparkConf, SparkContext def main(): conf = SparkConf().setAppName("pyWordCount").setMaster("local[2]") sc = SparkContext(conf=conf) sc.textFile("hdfs://192.168.1.27:9000/words.txt").flatMap(lambda x: x.split(" ")).map(lambda x: (x, 1)).reduceByKey(lambda x, y: x + y).saveAsTextFile("hdfs://192.168.1.27:9000/py_wc") if __name__ == '__main__': main()
-
1.8. 提交任务到集群
-
打jar包,去掉setMaster
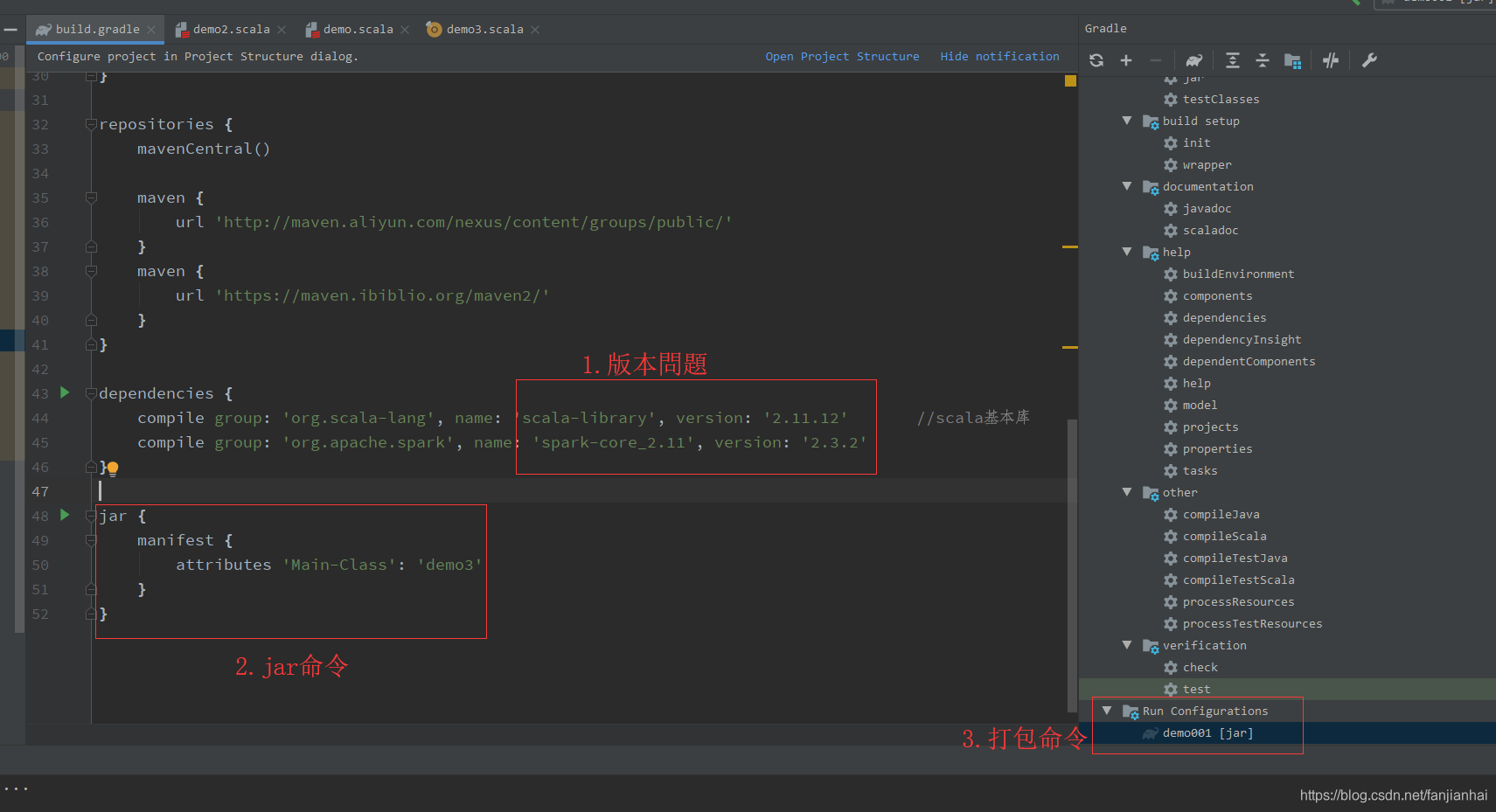
-
将jar上传到linux(不是上传到hdfs) -
执行命令
(standalone模式)
bin/spark-submit --master spark://192.168.1.27:7077,192.168.1.28:7077 --executor-memory 512m --total-executor-cores 2 --class demo3 /home/hadoop/fanjh/demo001-1.0.0.jar hdfs://cluster/test/input/words.txt hdfs://cluster/test/out2
(yarn模式)
bin/spark-submit --master yarn --executor-memory 512m --total-executor-cores 2 --class demo3 /home/hadoop/fanjh/demo001-1.0.0.jar hdfs://cluster/test/input/words.txt hdfs://cluster/test/out2



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









