







 本文深入探讨无监督学习中的聚类算法,包括k-Means的修正与公式化解释,层次聚类的两种类型,以及DBSCAN和谱聚类的原理。同时,介绍了衡量聚类效果的指标和标签传递算法,揭示了在实际问题中如何选择合适的聚类方法。
本文深入探讨无监督学习中的聚类算法,包括k-Means的修正与公式化解释,层次聚类的两种类型,以及DBSCAN和谱聚类的原理。同时,介绍了衡量聚类效果的指标和标签传递算法,揭示了在实际问题中如何选择合适的聚类方法。
机器学习深版07:聚类
文章目录
1. 无监督学习
相比之前的有监督学习不同。其实是做一个降维。
2. 聚类

1. 相似度/距离计算方法总结

余弦相似度与Pearson相似系数本质上是一样的:

2. k-Means算法


1.修正
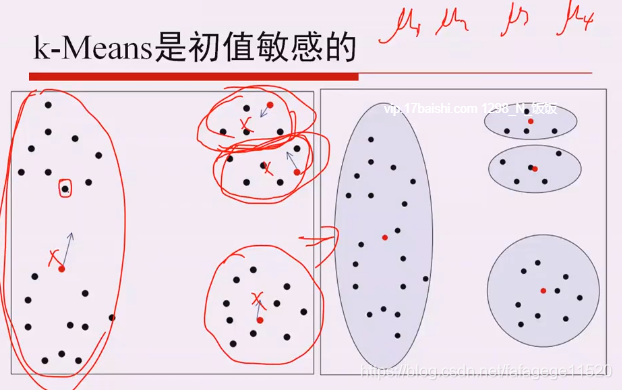
希望初始化聚类中心的时候距离就比较远。
k-Means++,应用权值和距离更新的一些方法,实现了初始化聚类中心点的选择。
2.公式化解释

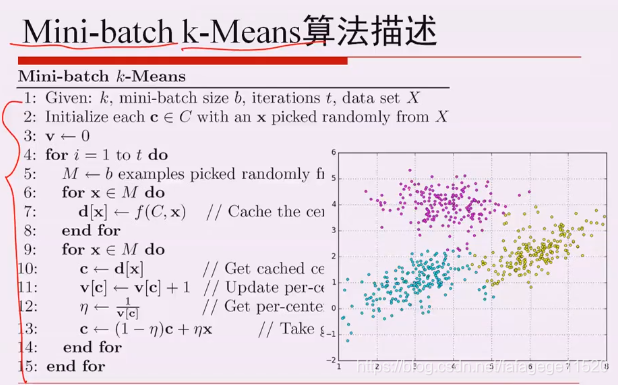
上面本质是批量梯度下降算法,用随机梯度下降,如果样本量巨大,可以考虑下面的,如下图:
3. 衡量指标
4. 已知实际的结果

ARI初始想法很简单,但是公式挺复杂,使他映射到0–1

AMI:还是利用上面的矩阵,计算MI互信息,然后计算NMI(正则化的互信息),卡一下它的范围,变成AMI。

2. 没有标记结果的判断


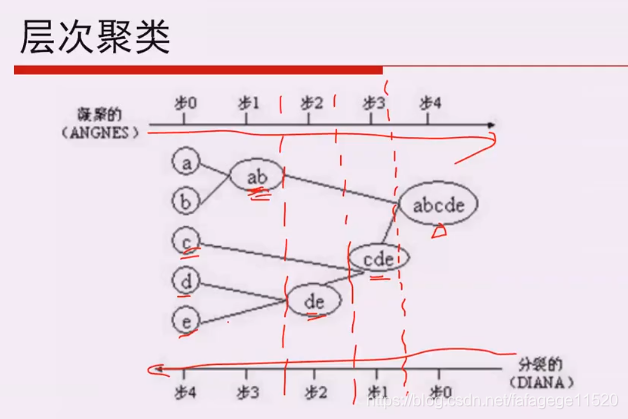
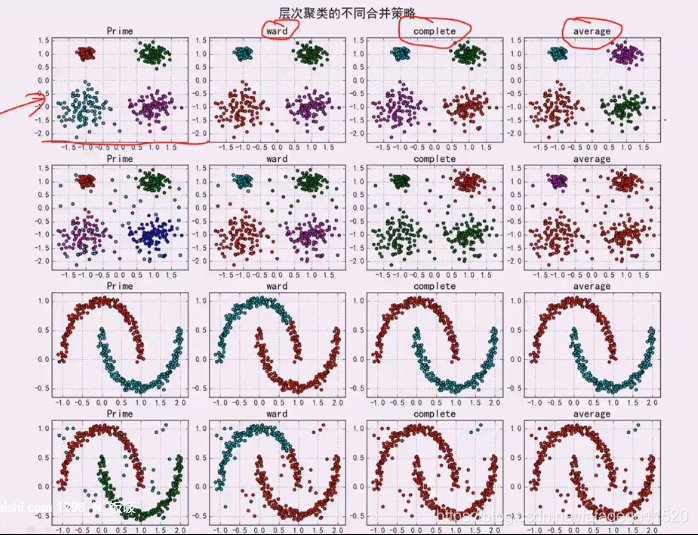
3. 层次聚类
1. 两种分类
凝聚式用的更多,学科划分中用到的很多。

2.距离的定义
最小距离:会出现链状结构
最大距离:一些狭长的簇不适用

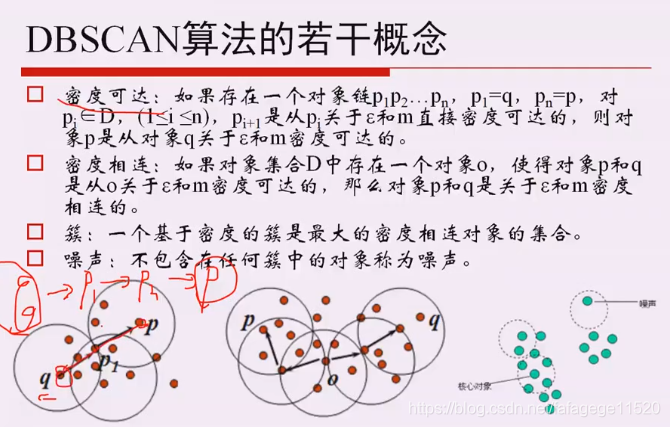
4.密度聚类

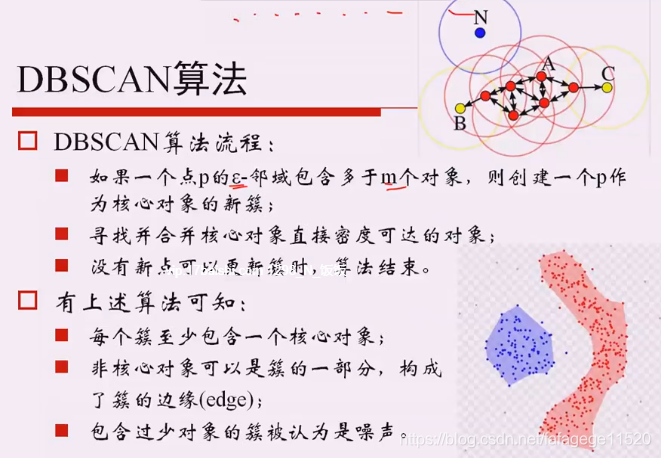
1.DBSCAN

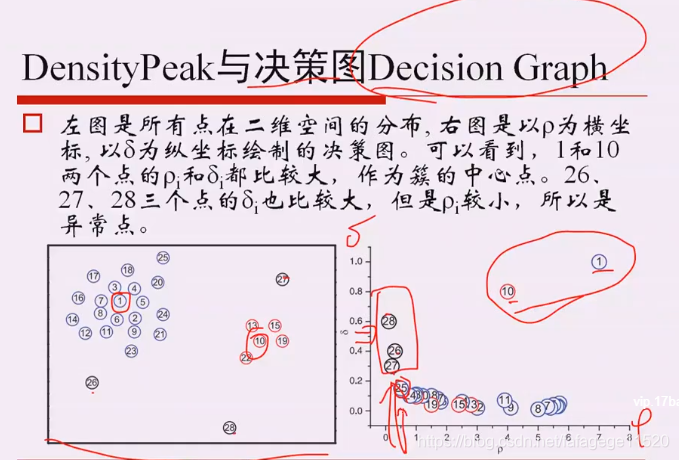
2.密度最大值算法


高局部密度点:比我有钱的最近的人的距离

5.谱聚类
1.数学知识
- 实对称矩阵的特征值是实数
- 实对称矩阵不同的特征值对应的特征向量是正交的
2.整体过程
和PCA相似


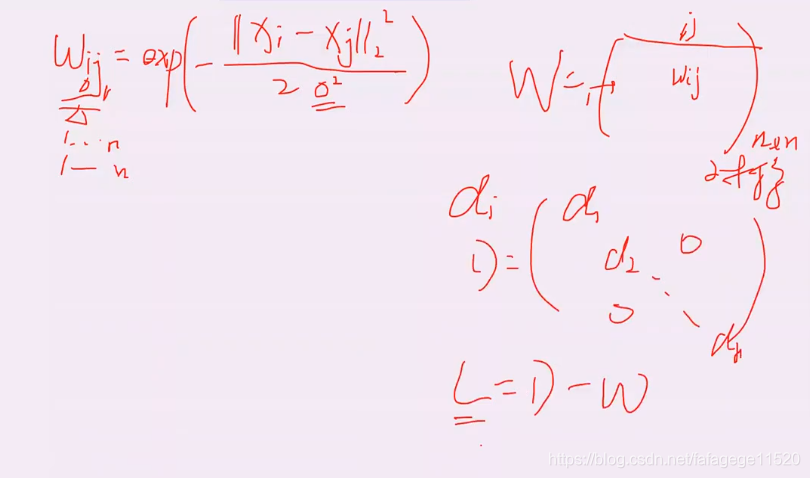
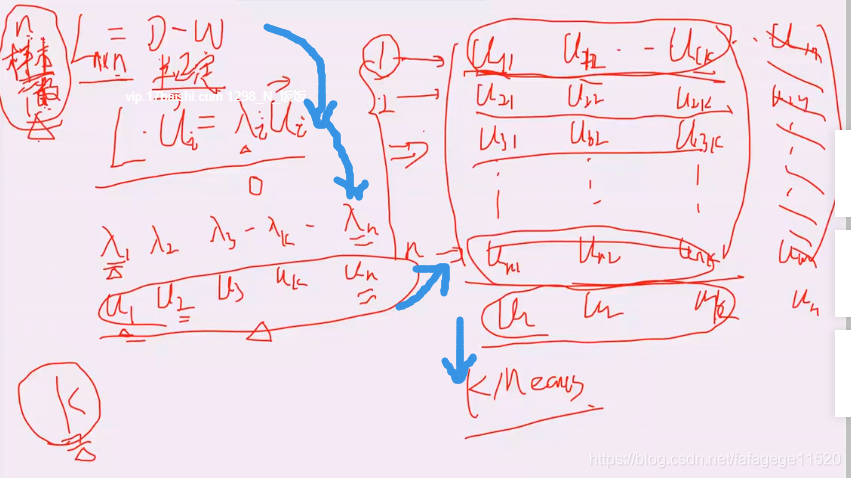
3.分类



4.理解上

5.进一步思考

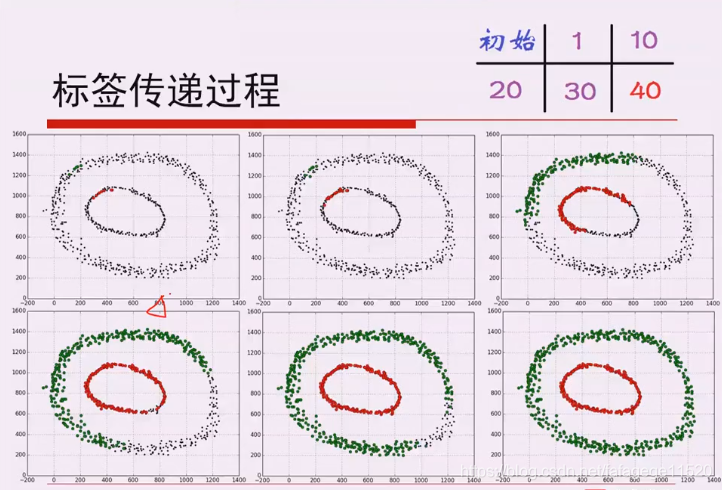
6.标签传递算法


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









