




(2021-AAAI)Type-augmented Relation Prediction in Knowledge Graphs
Keywords: Representation Learning
摘要
本文是关于知识图谱补全中的关系预测(relation prediction)。大多数现有的工作都是通过最大化观察到的三元组实例的可能性来进行补全,对实体类型信息、关系信息等本体信息的关注却不多。我们提出了一种类型增强的关系预测(TaRP)方法,其中我们将类型信息和实例级信息应用于关系预测。其中,类型信息和实例级信息分别编码为关系的先验概率和似然概率,并按照贝叶斯规则进行组合。在FB15K、FB15K-237、YAGO26K-906和DB111K-174四个基准数据集上,我们提出的TaRP方法的性能明显优于最先进的方法。此外,结果表明,该方法显著提高了数据效率。更重要的是,通过该模型,从特定数据集提取的类型信息可以很好地推广到其他数据集。
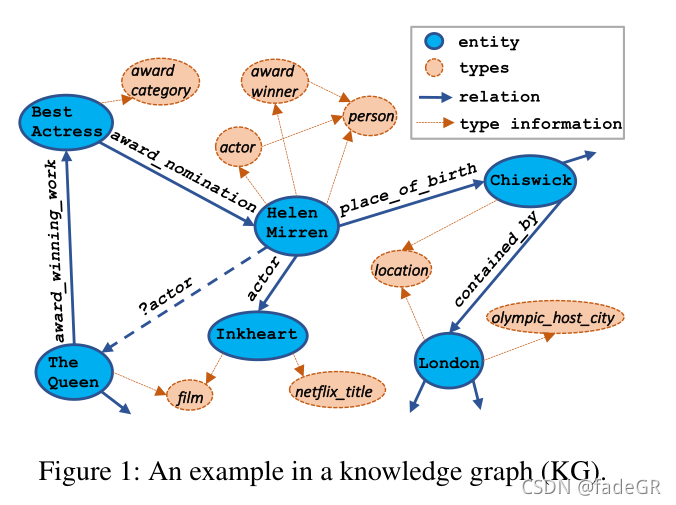
介绍
关系预测方法大都基于知识图谱嵌入,主要使用知识图谱中的两类信息进行分类:
- 实例级信息(Instance-level information) 也就是三元组信息
- 例如:Helen_Mirren →place_of_birth → Chis_wick
- 本体信息(Ontological information) 也就是实体属性信息 type information
- Helen_Mirren的类型{actor, award_winner, person}
大多数现有方法仅使用实例级信息来学习嵌入,而其他一些模型同时使用实例级信息和本体信息。类型信息例如本体信息可以直观地帮助关系预测,因为大多数关系可以将两种不同类型的实体连接为领域和范围。例如:
- 关系place_of_birth总是将person类型的实体和location类型的实体连接起来构成三元组。将此类类型信息集成到实例级训练三元组中可以使关系预测任务受益,特别是在缺乏足够的训练数据来学习嵌入的情况下。
如今一些现有的基于嵌入的模型集成了类型信息,但是这类模型通过模型训练来集成本体信息,来更好的地学习嵌入,因此容易出现以下缺点:
- 类型信息与层次信息没有显式区分,联合考虑两种信息来学习一组单一的模型参数
- 类型信息被紧密地编码到目标函数中,使得集成高度依赖于训练过程,因此在增加新的嵌入技术时不太灵活。我们将这种集成过程称为特性级集成(feature-level integration)。相反,我们提出了一种有效的决策级集成(decision-level integration):给定类型信息和实例级信息分别编码为先验概率和可能性,所提出的决策级集成遵循贝叶斯规则将这两种信息结合起来。
在本文中,我们提出了一个简单而有效的框架,以增强现有的基于嵌入的模型与类型信息。我们工作的贡献如下:
- 所提出的决策级集成框架独立于基于嵌入的模型,可以灵活地应用于不同的基于嵌入的模型,无需额外的训练
- 在三个基准数据集上,所提出的类型增强关系预测(TaRP)方法比最先进的模型实现了更好的关系预测性能。此外,我们还表明,通过集成类型信息,TaRP对培训数据的依赖性更小,因此数据效率更高。
- 我们通过经验证明,从特定数据中提取的类型信息可以通过TaRP模型对其他不同的数据集进行一般化。
相关工作
介绍了现有知识图谱补全大多数基于嵌入的方法,同时简单介绍了基于嵌入的方法的基本内容:设计嵌入方式、设计评分函数与损失函数。都是基于TransE的思想不断演化更新,这些方法只是借用了实例级信息,并没有借助本体信息。
再讨论了现有的基于嵌入的方法而且结合了本体信息,也有很多,而且还探讨了本体信息中除了类型信息之外的信息利用情况。但他们都是将本体信息集成到特征级的实例信息,来更好的学习嵌入。
除了基于嵌入的方法还有基于路径的方法,但计算量大本文不讨论该情况。
TaRP: Type-augmented
Relation Prediction Model(关系预测模型)
在本节中,我们将介绍我们的类型增强关系预测(type-augmented relation prediction framework)(TaRP)框架,该框架使用来自知识图谱的类型信息增强现有的嵌入模型。我们的框架由两个组件组成:
- (a)先验模型,其中我们将类型信息编码为先验概率,详见章节;
- (b)基于现有实例级信息的似然模型。任何现有的基于嵌入的模型都可以作为似然模型,在本节中我们简要描述了三种用于实验的基于嵌入的模型。该框架使用贝叶斯规则集成了先验和似然模型的信息(详见本节)。
Type Information Integration (类型信息集成)
本节介绍将类型信息编码为先验概率的方法,定义知识图谱G={E,R,T}\mathcal{G}=\{\mathcal{E}, \mathcal{R}, \mathcal{T}\}G={E,R,T},E,R,T\mathcal{E}, \mathcal{R},\mathcal{T}E,R,T分别为实体集,关系集,类型集。
基于层次结构的类型权重:类型是有层次结构的,一个个包含关系,例如{person,actor…},对于不同层次的类型赋予不同的权重。H=/t1/t2/…./tk/…/tK1H=/ t_{1} / t_{2} / \ldots . / t_{k} / \ldots / t_{K}^{1}H=/t1/t2/…./tk/…/tK1就是一个不断具体化的类型。权重公式如下:
weH(tk)=exp(k−1)∑j=0K−1exp(j)
w_{e}^{H}\left(t_{k}\right)=\frac{\exp (k-1)}{\sum_{j=0}^{K-1} \exp (j)}
weH(tk)=∑j=0K−1exp(j)exp(k−1)
每一个实体都对应一个类型序列,在该类型序列中计算不同层次类型的权重。对于同一个实体中的同一个类型,取所有层次中的最小值we(t)=w_{e}(t)=we(t)= min(weH1(t),weH2(t),…,weHN(t))\min \left(w_{e}^{H_{1}}(t), w_{e}^{H_{2}}(t), \ldots, w_{e}^{H_{N}}(t)\right)min(weH1(t),weH2(t),…,weHN(t))。例如:H1=/person/actorH_{1}= /person/actorH1=/person/actor ,H2=/person/awardwinnerH_{2}=/person/award_winnerH2=/person/awardwinner ,H3=/personH_{3}=/personH3=/person 所以计算得到: we(w_{e}(we( person )=0.27,we()=0.27, w_{e}()=0.27,we( actor )=0.73)=0.73)=0.73, we(w_{e}(we( award_winner )=0.73)=0.73)=0.73。同时类型分为头实体类型和尾实体类型:
Tr,head=∪e∈Head(r)TeTr,tail=∪e∈Tail(r)Te
\begin{aligned}T_{r, h e a d} &=\cup_{e \in \operatorname{Head}(r)} T_{e} \\T_{r, t a i l} &=\cup_{e \in \operatorname{Tail}(r)} T_{e}\end{aligned}
Tr,headTr,tail=∪e∈Head(r)Te=∪e∈Tail(r)Te
定义关系r的头实体集合:Head(r)={eh∣(eh,r,et)∈G,∀et∈E}\operatorname{Head}(r)=\left\{e_{h} \mid\left(e_{h}, r, e_{t}\right) \in \mathcal{G}, \forall e_{t} \in \mathcal{E}\right\}Head(r)={eh∣(eh,r,et)∈G,∀et∈E},定义关系r的尾实体集合:Tail(r)={et∣(eh,r,et)∈G,∀eh∈E}\operatorname{Tail}(r)=\left\{e_{t} \mid\left(e_{h}, r, e_{t}\right) \in \mathcal{G}, \forall e_{h} \in \mathcal{E}\right\}Tail(r)={et∣(eh,r,et)∈G,∀eh∈E},计算关系r对应头实体和尾实体的一个类型权重为:
wr, head (t)=∑e∈Head(r)we(t), for t∈Tr,headwr,tail(t)=∑e∈Tail(r)we(t), for t∈Tr,tail
\begin{aligned}
w_{r, \text { head }}(t) &=\sum_{e \in \operatorname{Head}(r)} w_{e}(t), \quad \text { for } t \in T_{r, h e a d} \\
w_{r, t a i l}(t) &=\sum_{e \in \operatorname{Tail}(r)} w_{e}(t), \quad \text { for } t \in T_{r, t a i l}
\end{aligned}
wr, head (t)wr,tail(t)=e∈Head(r)∑we(t), for t∈Tr,head=e∈Tail(r)∑we(t), for t∈Tr,tail
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gixau4qr-1636033705471)(%EF%BC%882021-AAAI%EF%BC%89Type-augmented%20Relation%20Prediction%20in%20Knowledge%20Graphs.assets/image-20211027110515317.png)]](https://i-blog.csdnimg.cn/blog_migrate/22c8b2999fcb3edc347715b02d157f24.png)
基于类型先验概率:计算头实体和关系的类型相似度,尾实体和关系的类型相似度,
s(eh,r)=∑t∈Tr,head∩Tehwr,head(t)∑t∈Tr,headwr,head(t)s(et,r)=∑t∈Tr,tail∩Tetwr,tail(t)∑t∈Tr,tailwr,tail(t)
\begin{aligned}
&s\left(e_{h}, r\right)=\frac{\sum_{t \in T_{r, h e a d} \cap T_{e_{h}}} w_{r, h e a d}(t)}{\sum_{t \in T_{r, h e a d}} w_{r, h e a d}(t)} \\
&s\left(e_{t}, r\right)=\frac{\sum_{t \in T_{r, t a i l} \cap T_{e_{t}}} w_{r, t a i l}(t)}{\sum_{t \in T_{r, t a i l}} w_{r, t a i l}(t)}
\end{aligned}
s(eh,r)=∑t∈Tr,headwr,head(t)∑t∈Tr,head∩Tehwr,head(t)s(et,r)=∑t∈Tr,tailwr,tail(t)∑t∈Tr,tail∩Tetwr,tail(t)
所以先验概率定义为:
p(r∣T(eh,et,R))≜s(eh,r)s(et,r)∑r′∈Rs(eh,r′)s(et,r′)
p\left(r \mid \mathcal{T}\left(e_{h}, e_{t}, \mathcal{R}\right)\right) \triangleq \frac{s\left(e_{h}, r\right) s\left(e_{t}, r\right)}{\sum_{r^{\prime} \in \mathcal{R}} s\left(e_{h}, r^{\prime}\right) s\left(e_{t}, r^{\prime}\right)}
p(r∣T(eh,et,R))≜∑r′∈Rs(eh,r′)s(et,r′)s(eh,r)s(et,r)
不同于以前的工作(Ma et al. 2017),通过平等对待每种类型来衡量语义相似度。我们的基于类型的先验概率与基于层次的类型权重不仅编码类型信息,而且编码类型之间的底层层次。
为了消除噪声,引入η\etaη参数,公式如下:
wr,∗(t)≥Wr,∗min+η×(Wr,∗max−Wr,∗min)
w_{r, *}(t) \geq W_{r, *}^{\min }+\eta \times\left(W_{r, *}^{\max }-W_{r, *}^{m i n}\right)
wr,∗(t)≥Wr,∗min+η×(Wr,∗max−Wr,∗min)
嵌入基础模型
介绍常用的嵌入模型:
TransE: eh,er∈Rd\mathbf{e}_{h}, \mathbf{e}_{r} \in \mathbb{R}^{d}eh,er∈Rd and r∈Rd\mathbf{r} \in \mathbb{R}^{d}r∈Rd.
fr(eh,et)=−∣∣eh⋅r−et∥
f_{r}\left(\mathbf{e}_{h}, \mathbf{e}_{t}\right)=-|| \mathbf{e}_{h} \cdot \mathbf{r}-\mathbf{e}_{t} \|
fr(eh,et)=−∣∣eh⋅r−et∥
RotatE: eh,er∈Cd\mathbf{e}_{h}, \mathbf{e}_{r} \in \mathbb{C}^{d}eh,er∈Cd and r∈Cd\mathbf{r} \in \mathbb{C}^{d}r∈Cd.
fr(eh,et)=−∥eh∘r−et∥
f_{r}\left(\mathbf{e}_{h}, \mathbf{e}_{t}\right)=-\left\|\mathbf{e}_{h} \circ \mathbf{r}-\mathbf{e}_{t}\right\|
fr(eh,et)=−∥eh∘r−et∥
QuatE: eh,er∈Hd\mathbf{e}_{h}, \mathbf{e}_{r} \in \mathbb{H}^{d}eh,er∈Hd and r∈Hd\mathbf{r} \in \mathbb{H}^{d}r∈Hd.
fr(eh,et)=−∥eh⊗r∣r∣−et∥
f_{r}\left(\mathbf{e}_{h}, \mathbf{e}_{t}\right)=-\left\|\mathbf{e}_{h} \otimes \frac{\mathbf{r}}{|\mathbf{r}|}-\mathbf{e}_{t}\right\|
fr(eh,et)=−∥∥∥∥eh⊗∣r∣r−et∥∥∥∥
以上的模型都只包含实例级信息,而不包含类型信息,所以要包含类型信息的话重新定义得分函数为:
p(eh,et∣r)≜exp(fr(eh,et))
p\left(e_{h}, e_{t} \mid r\right) \triangleq \exp \left(f_{r}\left(\mathbf{e}_{h}, \mathbf{e}_{t}\right)\right)
p(eh,et∣r)≜exp(fr(eh,et))
类型信息集成
最后一步是将实例级信息与类型信息在决策级中集成。给定一个三元组(eh,r,et)\left(e_{h}, r, e_{t}\right)(eh,r,et),根据类型信息p(r∣T(eh,et,R))p\left(r \mid \mathcal{T}\left(e_{h}, e_{t}, \mathcal{R}\right)\right)p(r∣T(eh,et,R)),我们得到关系的先验概率,同时得到实例级信息的模型p(eh,et∣r)p\left(e_{h}, e_{t} \mid r\right)p(eh,et∣r),通过贝叶斯规则得到后验概率:
p(r∣eh,et,T(eh,et,R))∝p(eh,et∣r)p(r∣T(eh,et,R))
\begin{aligned}
&p\left(r \mid e_{h}, e_{t}, \mathcal{T}\left(e_{h}, e_{t}, \mathcal{R}\right)\right) \\
&\propto p\left(e_{h}, e_{t} \mid r\right) p\left(r \mid \mathcal{T}\left(e_{h}, e_{t}, \mathcal{R}\right)\right)
\end{aligned}
p(r∣eh,et,T(eh,et,R))∝p(eh,et∣r)p(r∣T(eh,et,R))
因此后验概率p(r∣eh,et,T(eh,et,R))p\left(r \mid e_{h}, e_{t}, \mathcal{T}\left(e_{h}, e_{t}, \mathcal{R}\right)\right)p(r∣eh,et,T(eh,et,R))既包含类型信息又包含实例级信息。我们提出的决策级集成独立于嵌入技术。与现有论文相比,这是显著的差异化因素,例如,(Ma et al. 2017;Xie, Liu, and Sun 2016),将类型信息紧密地集成在特征级(集成在目标函数中),使其不那么灵活地演化嵌入技术。
类型信息:p(r∣T(eh,et,R))p\left(r \mid \mathcal{T}\left(e_{h}, e_{t}, \mathcal{R}\right)\right)p(r∣T(eh,et,R))
实例信息:p(eh,et∣r)p\left(e_{h}, e_{t} \mid r\right)p(eh,et∣r)
最终概率:$p\left(r \mid e_{h}, e_{t}, \mathcal{T}\left(e_{h}, e_{t}, \mathcal{R}\right)\right) $
实验
为了评估我们的类型增强关系预测(TaRP)方法的表现,我们首先对现有模型进行消融研究;然后评估TaRP模型的表现。我们通过将TaRP模型与三个基于基线嵌入的模型(TransE、RotatE和QuatE)进行比较,来证明问题资产救援计划模型的有效性。此外,我们还表明,通过合并类型信息,TaRP比现有方法的数据效率高得多。此外,我们还演示了类型信息的泛化能力。在最后,我们的方法是先进的模型,同时应用了本体论信息。
数据集我们考虑了三个基准数据集用于关系预测任务:FB15K (Bordes et al. 2013), Y AGO26K-906 (Hao et al. 2019)和DB111K-74 (Hao et al. 2019)。FB15K是一种流行的知识图谱补全的任务基准数据集,其类型信息已经被大多数之前的工作所使用,如(Ma et al. 2017;Guo et al. 2015;Xie, Liu, and Sun 2016)。Y AGO26K-906和DB111K-906是两个最新的包含显式本体信息的数据集,并没有被相关工作广泛考虑。FB15K由从FreeBase知识图中提取的三元组组成(Bollacker et al. 2008)。与(Xie, Liu, and Sun 2016)中介绍的FB15K类型信息相同。Y AGO26K-906和DB111K174都包含两种类型的KGs:实例KG和本体KG,它们通过类型链接相互连接。Y AGO26K-906和DB111K174的实例KGs分别由Y AGO知识图(Rebele et al. 2016)和DBpedia知识图(Lehmann et al. 2015)提取的三元组组成;并应用于关系预测任务。收集类型链接和本体KGs作为类型信息。三个数据集的统计信息如表1所示。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-35HxBrFl-1636033705490)(%EF%BC%882021-AAAI%EF%BC%89Type-augmented%20Relation%20Prediction%20in%20Knowledge%20Graphs.assets/image-20211104214508641.png)]](https://i-blog.csdnimg.cn/blog_migrate/ede9a2e065ea9b0053a174b3e946a1b2.png)
•FB15k-237(2013):是知识图谱Freebase的子集,15k表示其中知识库中有15k个主题词,237表示共有237种关系
•YAGO26K-906 (2019): 是知识图谱YAGO的子集, 26K表示其中知识库中有26K个主题词, 237表示共有237种关系
•DB111K-174 (2019):是知识图谱DBpedia的子集, 111K表示其中知识库中有111K个主题词, 174表示共有174种关系
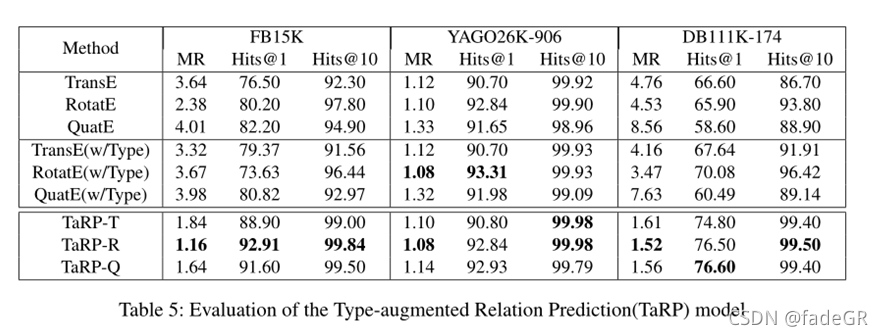
•结果表明,在不同的嵌入模型中引入类型信息,TaRP模型总能获得更好的性能
消融实验
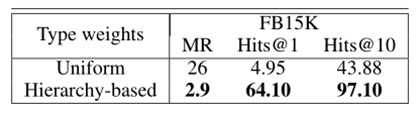
基于层次的类型权重的有效性:
类型信息的有效性:
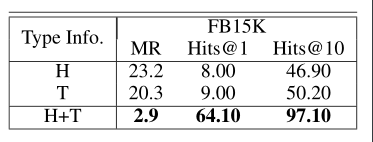
•H 仅头实体的类型信息
•T 仅尾实体的类型信息
•H+T头实体与尾实体的类型信息
TaRP模型评估
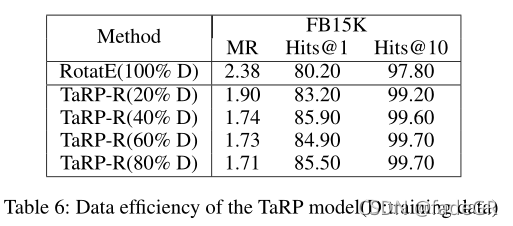
数据效率
•考虑从训练三元组的子集中学习嵌入
•结果表明,通过利用类型信息,TaRP对数据的依赖性更小,即数据效率更高
与SoTA模型对比
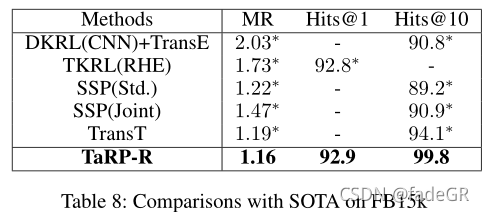
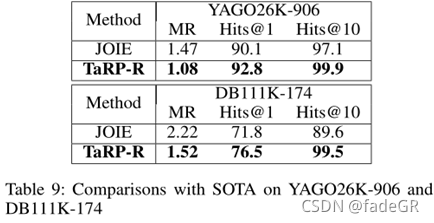
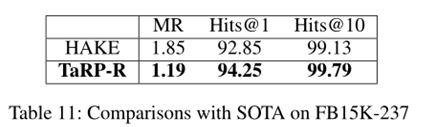
•DKRL (2016)、TKRL (2016)、SSP (2017)、TransT (2017)、JOIE(2019)
讨论
•提出决策级集成框架独立于基于嵌入的模型,可以应用于不同的基于嵌入的模型。
•提出的类型增强关系预测(TaRP)方法比最先进的模型实现了更好的关系预测性能。
•通过集成类型信息,TaRP对训练数据的依赖性更小,因此数据效率更高。
从特定数据中提取的类型信息可以通过TaRP模型对其他不同的数据集进行一般化
总结
在本文中,我们提出了一种有效的类型增广关系预测(TaRP)方法,该方法将类型信息和实例级信息应用于知识图谱的关系预测。将类型信息和实例级信息分别编码为关系的先验概率和可能性,并在决策级进行组合。我们的方法明显优于最先进的方法。此外,通过利用类型信息,TaRP模型能够比现有模型具有更高的数据效率。此外,从特定数据集提取的类型信息可以很好地推广到其他数据集。
•本文提出了一种有效的类型增强关系预测(TaRP)方法
•该方法将类型信息和实例级信息应用于知识图谱的关系预测
•将类型信息和实例级信息分别编码为关系的先验概率和可能性
•从特定数据集提取的类型信息可以很好地推广到其他数据集


















 3310
3310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











