



MongoDB介绍
MongoDB主要有如下特点:
(1)高性能:
- MongoDB提供高性能的数据持久性。特别是对嵌入式数据模型的支持减少了数据库系统上的I/0活动。
- 索引支持更快的查询,并且可以包含来自嵌入式文档和数组的键。(文本索引解决搜索的需求、TTL索引解决历史数据自动过期的需求、地理位置索引可用于构建各种 O2O应用)
- mmapv1、wiredtiger、mongorocks(rocksdb)、in-memory等多引擎支持满足各种场景需求。
- Gridfs解决文件存储的需求。
(2)高可用性:
- MongoDB的复制工具称为副本集(replicaset),它可提供自动故障转移和数据冗余。
(3)高扩展性:
- MongoDB提供了水平可扩展性作为其核心功能的一部分。
- 分片将数据分布在一组集群的机器上。(海量数据存储,服务能力水平扩展)
- 从3.4开始,MongoDB支持基于片键创建数据区域。在一个平衡的集群中,MongoDB将一个区域所覆盖的读写只定向到该区域内的那些片。
(4)丰富的查询支持:
- MongoDB支持丰富的查询语言,支持读和写操作(CRUD),比如数据聚合、文本搜索和地理空间查询等
(5)其他特点:
- 如无模式(动态模式)、灵活的文档模型
单机部署
第一步:下载安装包
MongoDB提供了可用于 32 位和 64 位系统的预编译二进制包,你可以从MongoDB官网下载安装,MongoDB预编译二进制包下载地址:试用 MongoDB 社区版 |MongoDB 数据库
数据库的的创建与删除
mongodb的存储机制是:
1、当使用use db的时候会先把数据存在内存中,当其中有集合时,才会存储在磁盘。
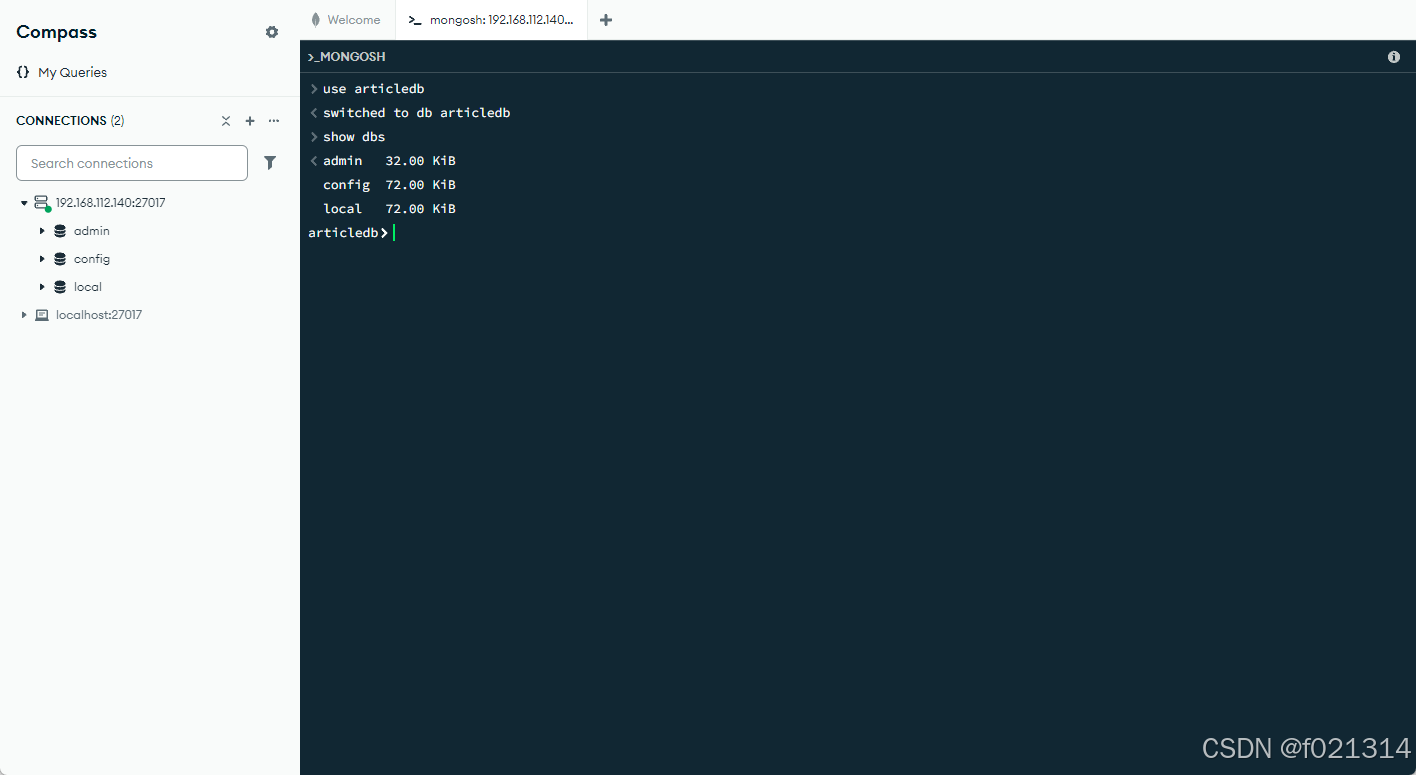
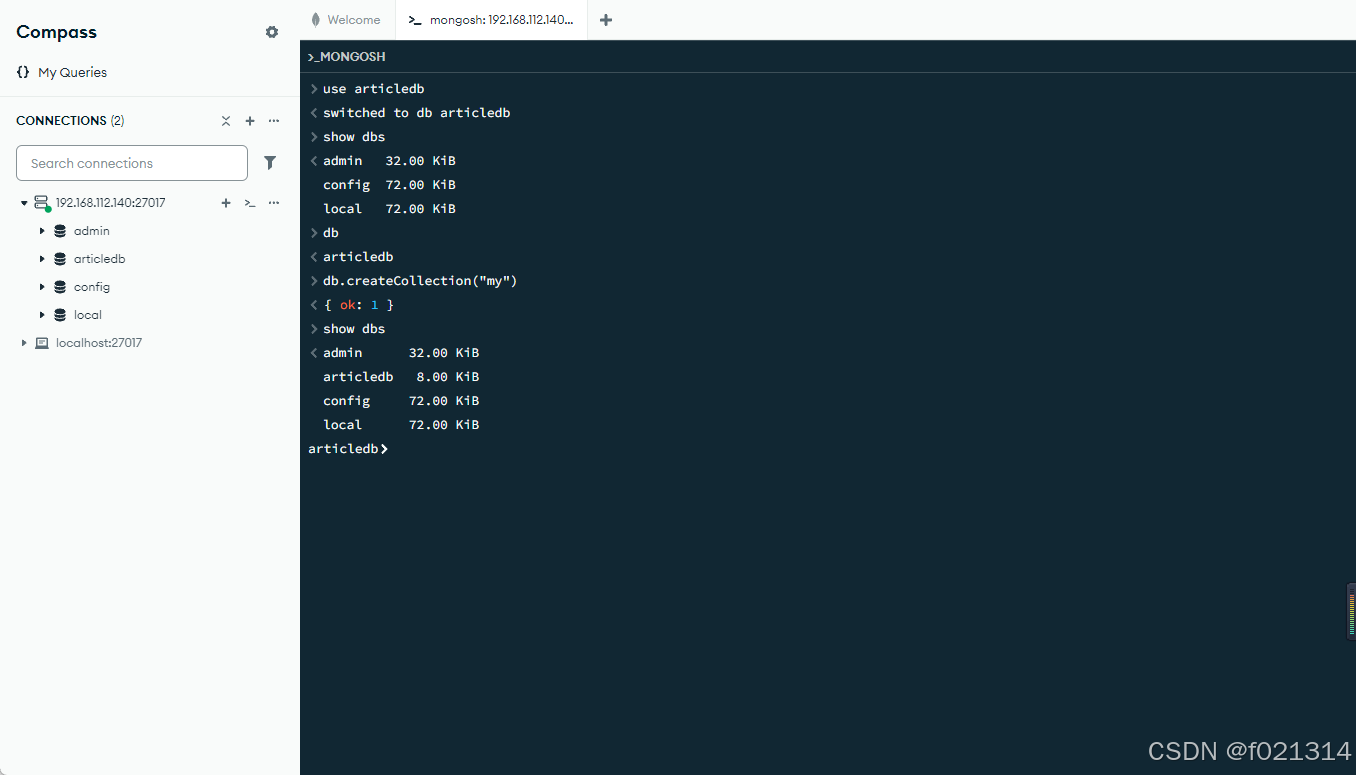
2、当我们创建集合后,就会将表保存在磁盘中。
文档基本的CRUD
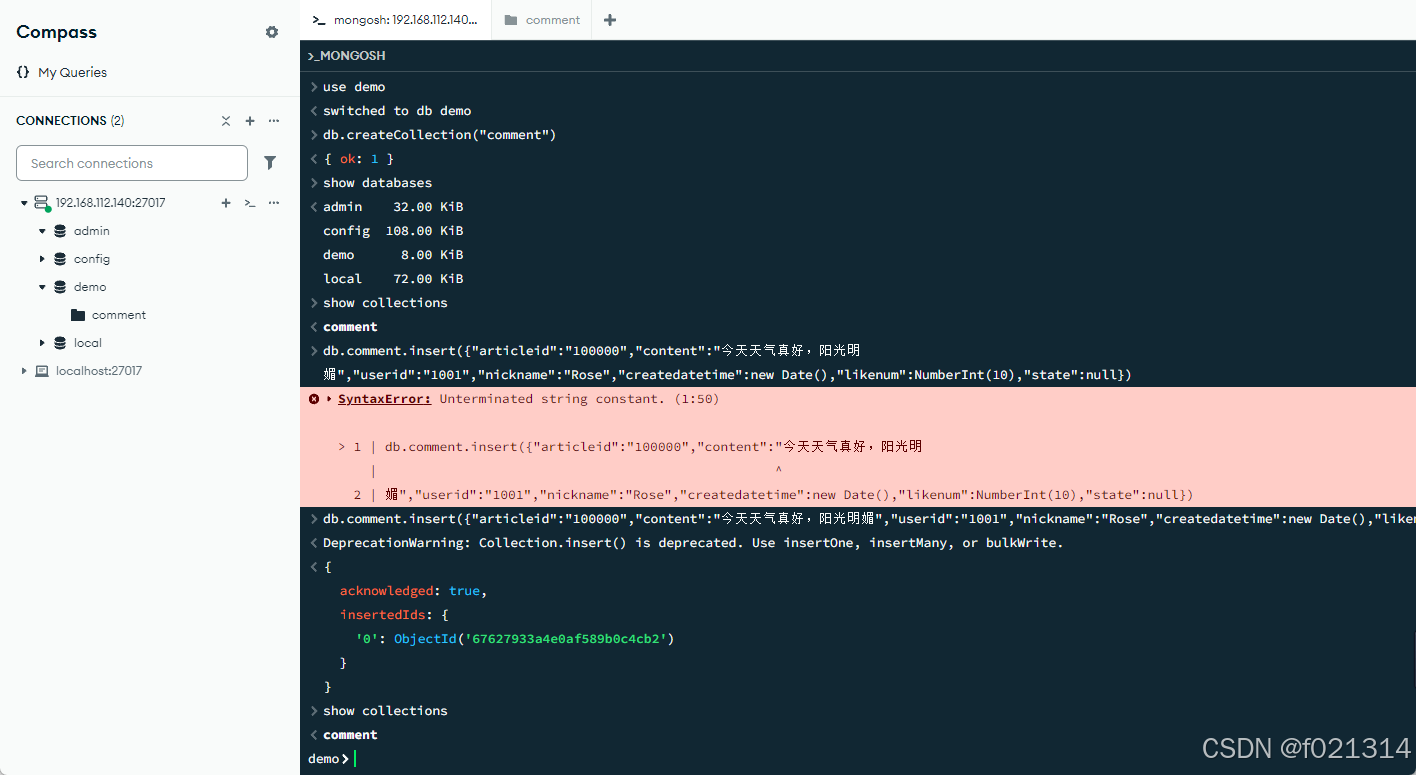
文档的插入和查询
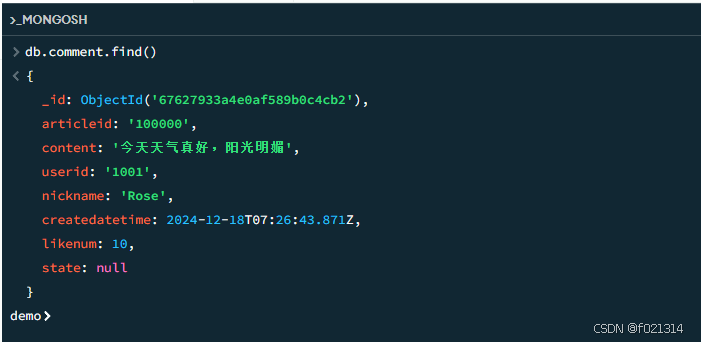
文档的基本查询
文档的更新
db.collection.update(query, update, options)
//或
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>,
collation: <document>,
arrayFilters: [ <filterdocument1>, ... ],
hint: <document|string> // Available starting in MongoDB 4.2
}
)文档的删除
Java客户端使用Mongodb
在配置完环境后,进行测试
spring:
#数据源配置
data:
mongodb:
# 主机地址
host: 192.168.112.140
# 数据库
database: demo
# 默认端口是27017
port: 27017 @Test
void contextLoads() {
List<Comment> commentList = (List<Comment>) commentService.findCommentList();
System.out.println(commentList);
}
分页列表展示
public Page<Comment> findCommentListByParentid(String parentid,int page,int size) {
return commentRepository.findByParentid(parentid,PageRequest.of(page-1,size));
}
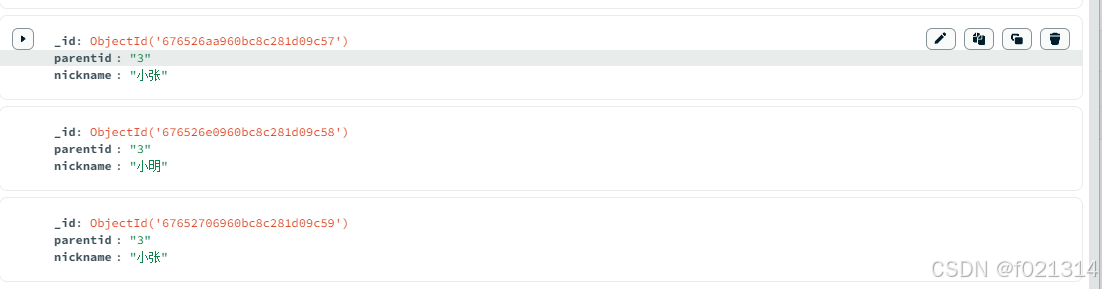 由于设置的每页显示两个数据,所以只显示了小张和小明两个人。
由于设置的每页显示两个数据,所以只显示了小张和小明两个人。
MongoTemplate实现点赞数加一
public void updateCommentLikenum(String id){
// 查询条件
Query query = Query.query(Criteria.where("_id").is(id));
// 更新条件
Update update = new Update();
update.inc("likenum");
mongoTemplate.updateFirst(query,update,Comment.class);
}原本:


之后:

Mongodb集群和安全
副本集-Replica Sets
MongoDB中的副本集(Replica Set)是一组维护相同数据集的mongod服务。副本集可提供冗余和高可用性,是所有生产部署的基础。
也可以说,副本集类似于有自动故障恢复功能的主从集群。通俗的讲就是用多台机器进行同一数据的异步同步,从而使多台机器拥有同一数据的多个副本,并且当主库当掉时在不需要用户干预的情况下自动切换其他备份服务器做主库,而且还可以利用副本服务器做只读服务器,实现读写分离,提高负载。
(1)冗余和数据可用性
复制提供冗余井提高数据可用性。通过在不同数据库服务器上提供多个数据剧本,复制可提供一定级别的容错功能,以防止丢失单个数据库服务器。
在某些情况下,复制可以提供增加的读取性能,因为客户端可以将读取操作发送到不同的服务上,在不同数据中心维护数据副本可以增加分布式应用程序的数据位置和可用性。您还可以为专用目的维护其他副本,例如灾难恢复,报告或备份。
(2)MongoDB中的复制
副本集是一组维护相同数据集的mongod实例。副本集包含多个数据承载节点和可选的一个仲裁节点。在承载数据的节点中,一个且仅一个成员被视为主节点,而其他节点被视为次要(从)节点。
主节点接收所有写操作。 副本集只能有一个主要能够确认具有{w:"most”)写入关注的写入; 虽然在某些情况下另一个mongod实例可能暂时认为自己也是主要的。主要记录其操作日志中的数据集的所有更改,即opl0g。
辅助(副本)节点复制主节点的oplog井将操作应用于其数据集,以使辅助节点的数据集反映主节点的数据集。如果主要人员不在,则符合条件的中学将举行选举以选出新的主要人员。
(3)主从复制和副本集区别
主从集群和副本集最大的区别就是副本集没有固定的"主节点";整个集群会选出一个“主节点”,当其挂掉后,又在剩下的从节点中选中其他节点为“主节点”,副本集总有一个活跃点(主、primary)和一个或多个备份节点(从、secondary)。
副本集的三个角色
副本集有两种类型三种角色
两种类型:
- 主节点(Prim平y)类型:数据操作的主要连接点,可读写,
- 次要(辅助、从)节点(Secondaries)类型:数据冗余备份节点,可以读或选举
三种角色:
- 主要成员(Primary):主要接收所有写操作。就是主节点。
- 副本成员(Replicate):从主节点通过复制操作以维护相同的数据集,即备份数据,不可写操作,但可以读操作(但需要配置)。是默认的一种从节点类型。
- 仲裁者(Arbiter):不保留任何数据的副本,只具有投票选举作用。当然也可以将仲裁服务器维护为副本集的一部分,即副本成员同时也可以是仲裁者。也是一种从节点类型。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









