




 本文深入解析了线性回归模型,包括简单回归与多元回归的概念,介绍了经验风险最小化、结构风险最小化、最大似然估计及最大后验估计四种参数学习方法。探讨了在不同条件下如何选择合适的算法以优化模型,如最小二乘法、岭回归等。
本文深入解析了线性回归模型,包括简单回归与多元回归的概念,介绍了经验风险最小化、结构风险最小化、最大似然估计及最大后验估计四种参数学习方法。探讨了在不同条件下如何选择合适的算法以优化模型,如最小二乘法、岭回归等。
以下内容均为https//nndl.github.io/nndl-book.pdf的学习笔记。
机器学习的简单示例-线性回归
线性回归(Linear Regression)概述
简介
是一种对自变量和因变量之间关系进行建模的回归分析.自变量数量为1 时称为简单回归,自变量数量大于1 时称为多元回归.
机器学习中,,自变量就是样本的特征向量𝒙 ∈ ℝ𝐷(每一维对应一个自变量,列向量),因变量是标签𝑦,这里𝑦 ∈ ℝ 是连续值(实数或连续整数).假设空间是一组参数化的线性函数:

下面用增广向量来简要表示上述线性模型:

线性回归之参数学习
任务:给定一组包含𝑁 个训练样本的训练集𝒟 = {(𝒙(𝑛), 𝑦(𝑛))} n=[1,N],**学习一个最优的线性回归的模型参数𝒘.**下面从四个角度进行分析:
1.经验风险最小化
1)求解步骤
平方损失函数衡量真实标签和预测标签之间的差异。训练集上的经验风险定义为:
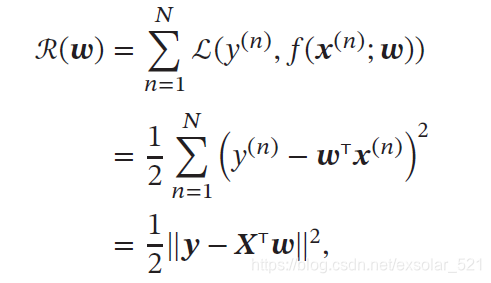

2)求解条件
𝑿𝑿T ∈ ℝ(𝐷+1)×(𝐷+1) 必须存在逆矩阵
–> 𝑿𝑿T 是满秩的(rank(𝑿𝑿T) = 𝐷 + 1
–> 行列式不为0
–>𝑿 中的行向量之间是线性不相关的,每个特征不相关。
一种常见的𝑿𝑿T 不可逆情况是样本数量𝑁 小于特征数量(𝐷 + 1),𝑿𝑿T的秩为𝑁.这时会存在很多解𝒘∗,可以使得ℛ(𝒘∗) = 0.
3)𝑿𝑿T 不可逆时解决方法
a.主成分分析:先使用主成分分析等方法来预处理数据,消除不同特征之间的相关性,然后再使用最小二乘法来估计参数。
b.最小均方算法:使用梯度下降法来估计参数.先初始化𝒘 = 0,然后通过下面公式进行迭代:
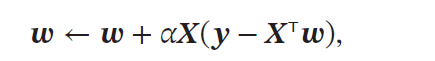
其中𝛼 是学习率。
2.结构风险最小化
1)为什么提出?
最小二乘法的基本要求是各个特征之间要互相独立,保证𝑿𝑿T 可逆,但在此条件满足的情况下,如果特征之间有较大的多重共线性(Multicollinearity),就会导致𝑿𝑿T 的逆无法准确计算,𝑿𝑿T 的逆对数据集𝑿扰动极其敏感。
2) 如何解决?
岭回归(Ridge Regression):给𝑿𝑿T 的对角线元素都加上一个常数𝜆 使得(𝑿𝑿T + 𝜆𝐼) 满秩。,即其行列式不为0.最优的参数𝒘∗ 为:

岭回归的解𝒘∗ 可以看作结构风险最小化准则下的最小二乘法估计,其目标函数可以写为:
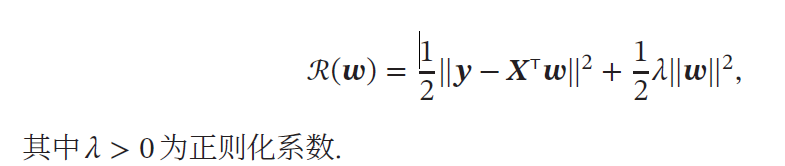
3.最大似然估计
从建模条件概率𝑝(𝑦|𝒙) 的角度来进行参数估计。
假设标签𝑦 为一个随机变量,并由函数𝑓(𝒙; 𝒘) = 𝒘T𝒙 加上一个随机噪声𝜖决定,即
𝑦 = 𝑓(𝒙; 𝒘) +𝜖,
= 𝒘T𝒙 + 𝜖,


4.最大后验估计
1)为什么需要最大后验估计?
当训练数据比较少时会发生过拟合,估计的参数可能不准确.为了避免过拟合,我们可以给参数加上一些先验知识.
2)步骤



















 1254
1254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









