




 本文详细介绍了队列的基本概念及其实现方式,包括循环队列、队列的常见操作等,并通过多个LeetCode题目示例讲解了队列在实际编程中的应用。涵盖了任务调度、链表操作、数据缓存等多个方面。
本文详细介绍了队列的基本概念及其实现方式,包括循环队列、队列的常见操作等,并通过多个LeetCode题目示例讲解了队列在实际编程中的应用。涵盖了任务调度、链表操作、数据缓存等多个方面。
前言
3月11日,开课吧门徒计划算法课第二讲学习笔记。
本课讲队列。
课题为:
1-2 线程池与任务队列(Task-Queue)
(由于自身精力问题,本次只记录重点和次重点,概念略写)
队列与线程池
队列概念简述
队列应用于一片连续的存储区域(这片区域可以为数组也可以为链表),可以存储符合条件的元素(可以为任意元素,但是需要为同类型)
下图对于队列做了一个简单的举例:
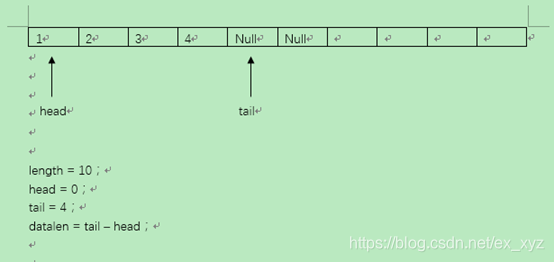
上图的队列有10个单位的内存空间,起始指针地址为0,尾指针地址为4,队列总长为4。
(通常情况下尾指针指向的元素是最后一个元素的下一位,也就是尾指针是不可取元素的)。
(为自身方便设计程序我定义一个尾元素的概念,尾元素为尾部当前元素,为尾指针上一个指向的元素)
(在我曾经的软件设计中,我设计的队列是从头入队,从尾出队,同样可以运行,但是不是规范的概念,并且尾指针用的是尾元素的概念)
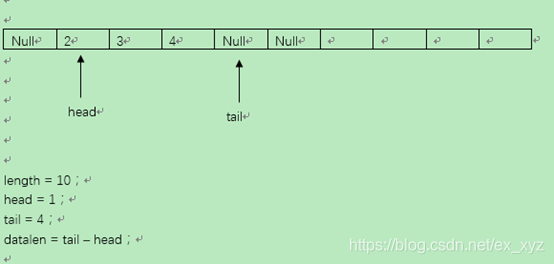
队列的出队
队列的出队动作通过提取一个头指针的所管理的元素来进行:
如下图:
队列的入队
队列的入队动作通过向尾指针管理的区域加入元素来进行:
如下图
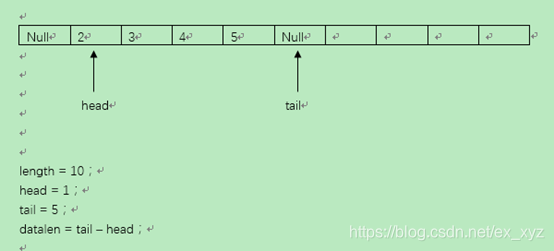
入队执行完毕后,尾指针向后移一位,队列总长度+1。(出位完毕后原先头指针指向的目标元素应该为空)
队列的假溢出
当尾指针走向存储空间的结尾时,指向划分的区域之外时,此时队列就满了,但是如果头指针有取出过数据,则实际上,队列空间还未满,因此这种状态称为队列的的假溢出
如下图

此时队列总长度为9,但是队列内存区域有10个空间,因此并未满。
(相比起尾指针我更喜欢用尾元素来进行管理)
循环队列
图略。
循环队列的出现是用于解决假溢出的情况,当将出现溢出动作时,令尾指针指向存储空间的开始。
(用尾元素来理解,将溢出时,尾指针指向存储空间的开始,尾元素为存储空间的结尾。而在下一个入队动作时,尾指针所在加入元素,成为尾元素,尾指针向后一位。)
总结
- 从头出队,从尾入队。
- 对于普通队列而言,出入队动作都是将指针后移一位,当头指向尾时,队列为空(tail == head)。
- 当尾指针溢出时,如果队列并未全部用尽,则称为假溢出。
- 对于循环队列,是用于有效的利用队列的空间而设计的。
- 循环队列溢出时,头尾指针是重合的(用尾元素来考虑则是,尾元素的后一位是头元素,因此不能再放入元素)
- 对于外部而言,只能获取到3个因素:队列长度,队是否为空,出队的元素
队列的基础操作
队列基本上有4种操作:
- push 入队操作 (对应下方举例的offer)
- pop 出队操作 (对应下方举例的poll)
- empty 判空操作
- front 获取队首元素 (对应下方举例的peek)
比较简单就直接转载一段:
https://www.runoob.com/java/data-queue.html
LinkedList类实现了Queue接口,因此我们可以把LinkedList当成Queue来用。
以下实例演示了队列(Queue)的用法:
import java.util.LinkedList;
import java.util.Queue;
public class Main {
public static void main(String[] args) {
//add()和remove()方法在失败的时候会抛出异常(不推荐)
Queue<String> queue = new LinkedList<String>();
//添加元素
queue.offer("a");
queue.offer("b");
queue.offer("c");
queue.offer("d");
queue.offer("e");
for(String q : queue){
System.out.println(q);
}
System.out.println("===");
System.out.println("poll="+queue.poll()); //返回第一个元素,并在队列中删除
for(String q : queue){
System.out.println(q);
}
System.out.println("===");
System.out.println("peek="+queue.peek()); //返回第一个元素
for(String q : queue){
System.out.println(q);
}
}
}
-
offer,add 区别:
一些队列有大小限制,因此如果想在一个满的队列中加入一个新项,多出的项就会被拒绝。
这时新的 offer 方法就可以起作用了。它不是对调用 add() 方法抛出一个 unchecked 异常,而只是得到由 offer() 返回的 false。 -
poll,remove 区别:
remove() 和 poll() 方法都是从队列中删除第一个元素。remove() 的行为与 Collection 接口的版本相似, 但是新的 poll() 方法在用空集合调用时不是抛出异常,只是返回 null。因此新的方法更适合容易出现异常条件的情况。 -
peek,element区别:
element() 和 peek() 用于在队列的头部查询元素。与 remove() 方法类似,在队列为空时, element() 抛出一个异常,而 peek() 返回 null。
上方举例的是一个没有设定范围的用链表制作的队列,不会构成循环队列,并且也没有长度上限。
循环队列(略)
制作循环队列核心方式在于管理队列长度和判断队列的空和满。
- 如果采用记录长度的方式则可以判断所用长度和队列空间总长来管理。
- 如果采用指针位置比较则通常需要牺牲一个存储单元(当尾指针下一位为头指针时判断为满,但是此时尾指针依然可以存放一个元素)
队列的应用
- 队列通常应用于不需要立即响应的任务,因此常常在许多场景中用于存放指令。
由于有些指令可能会有不同的执行效率的要求,因此可以设计不同的优先级队列,这样需求更为紧急的指令可以先执行,而相同优先级的则是依次执行。 - 在通信场景中队列本身可以理解为动态缓存,可以对于数据流进行滤波。比如使用半双工模组进行伪全双工通讯时,就可以依次将数据存入消息队列中,每一次切换发送定长的报文。此时一轮通讯完毕的实际信息交互速度就可以对外显示为双向速度,实现全双工的效果。
CPU的超线程技术
以真双核CPU举例:
在原本情况下(下图真双核):
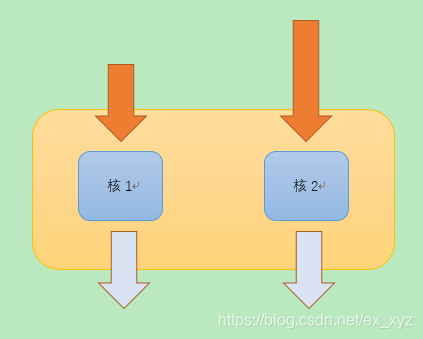
真双核CPU的计算核心依次从指令队列中取出指令进行执行。在这种情况下虽然任务执行的速度很快,但是同一时间内只能执行2个任务队列。
(橙色箭头表示需要执行的指令队列,箭头长度表示指令负荷,蓝色箭头表示已经执行完毕的指令)
在虚拟多核情况下(下图虚拟4核):
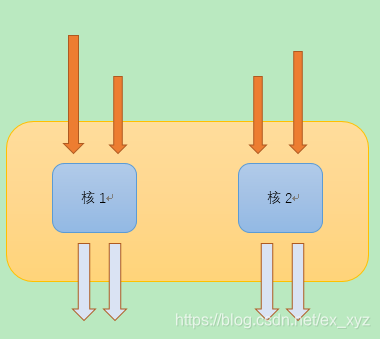
在这种情况下,每一个核心处理2个任务队列,对外部显示的就是4核心的效果。虽然会慢一些,但是适合需要多个任务并行的情况,并且CPU的速度很快通常能大于指令队列的取得速度。
这种虚拟的多核实现就称为CPU的超线程技术。
(CPU推荐支持2个任务队列,也就是n个真核,就可以运行2n个虚拟核)
在此基础上还可以有多路cpu并行的情况,来提升任务的处理性能(通常家用电脑仅为一路)
经典例题
分隔链表 leetcode—86
给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你应当 保留 两个分区中每个节点的初始相对位置。
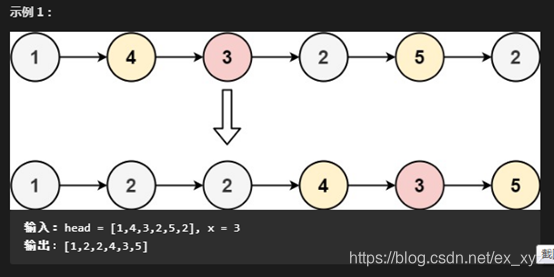
思路分析
首先这相当于将链表分成2个链表,分别为大于等于,小于。因此可以定义2个表头(空头)分别连接这2个生成的链表,最后再将这2个链表进行拼接。
(这题和队列的关联程度在于,依次从头取出单元,这种动作相当于将原始链表视作一个队列,进行出队动作。)
(以上为我的思路,和课堂意思一致)
解题举例
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
import java.util.Queue;
class Solution {
public ListNode partition(ListNode head, int x) {
//定义2个空头,小于/等于大于,头指针
ListNode dummy1,dummy2;
//定义2个中间变量,小于/等于大于,尾指针
ListNode temp1,temp2;
//定义2个长度变量,小于/等于大于,队列长度
ListNode len1,len2;
//上述的部分用于模拟队列,但是实际上可以直接采用现有的类
//如下:
//定义2个队列
Queue<ListNode> queue1 = new LinkedList<ListNode>();
Queue<ListNode> queue2 = new LinkedList<ListNode>();
//持续出队,直到为空
while(head != null){
if(head.val < x){
queue1.offer(head);
}
else{
queue2.offer(head);
}
head = head.next;
}
//准备用于返回的链表
ListNode dummy =new ListNode(0);
ListNode cur=dummy;
//接续小于的部分
for(ListNode temp : queue1){
System.out.println(temp.val);
cur.next = temp;
cur = cur.next;
}
//接续剩余的部分
for(ListNode temp : queue2){
System.out.println(temp.val);
cur.next = temp;
cur = cur.next;
}
//链表尾部断绝,防止成环
cur.next = null;
return dummy.next;
}
}
上述解决方法中提取元素的方式采用了遍历,但也可以用peek和poll配合实现出队,方法为先peek判断是否有元素,如果有就poll一个。
复制带指针的链表 leetcode—138
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
- val:一个表示 Node.val 的整数。
- random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
你的代码 只 接受原链表的头节点 head 作为传入参数。
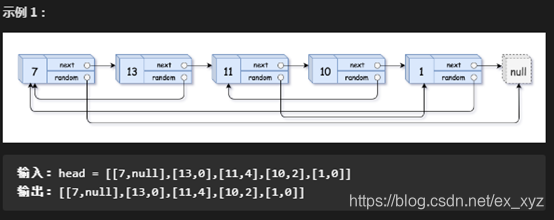
思路分析
首先,本题不只是复制一个链表和其存储的指针,这个链表中存储的指针会重新指向这个需要复制的链表。
因此本题的题意是当这个指针指向的是需要复制的链表的某个节点时,在复制动作结束后,这个新链表中的指针也应该指向新的链表的对应节点。
对此可以拓展一下思维,这个链表的random指针可能指向空或者表外的某个地方或者是表内。 (本题仅指向空或者表内)
而当指向表内的某个节点时,需要在复制的时候,令新表的对应指针指向这个复制完毕的点。
那么这样就提出一个问题:
- 问题A:如何知道这个random指针指向的内容是链表中的某一个节点呢?
(本题保证如果有指向则必然是某一个节点)
解A:
想要明确一个链表的节点是否属于这个链表,并且知道位置,唯一的方案为从链表头部进行查询,如果能找到这个节点就可以定位坐标。
加速查询的办法为,将原始链表的地址存入mapTree,key为地址,val为坐标。
如果采用这个方案需要遍历链表整体至少2遍,第一遍存入map,第二遍获得对应关系,而复制链表的动作就可以在这个行为过程中完成,第一遍创建新链表存储值和链表关系,第二遍获取新链表的指针指向关系。
(以上是我的解题思路,以空间复杂度换时间复杂度,但是自我感觉效率低下,下面记录课上的思路)
首先将原始链表每一个节点原地复制一个节点,再将原始的节点指向复制的节点,复制的节点指向原始节点的下一个节点。
原本假设如图:
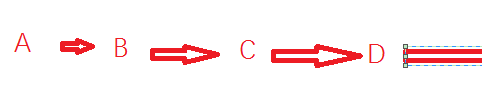
现在改为:
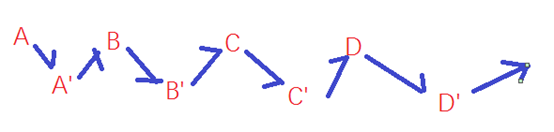
(到此明白这个思路了)
在这个情况下,原始的链表依然能够获取到之前的形态,只不过需要跳过一个节点。 而期望复制的链表同样可以获取到目标形态。那么原始链表的random指针指向的节点的下一个节点就是被复制的节点。
因此在这个情况下,依次令新节点的random指针指向原始节点指向的节点的下一个节点就可以满足节点的指向关系的复制。
完成这一步后再将原始链表复原,新链表拼接,就实现了复制。
(提出一个疑惑:这个思路怎么应对我提出的拓展问题,random指针可能指向其他链表)
(那么就同样需要进行一次map的存储)
(因此课上的解决方案为这个类型题目的特解,我考虑的为通解)
(然后这题我认为和队列无关,只是一道链表题)
解题举例
(以下为根据课上的思路写的代码)
/*
// Definition for a Node.
class Node {
int val;
Node next;
Node random;
public Node(int val) {
this.val = val;
this.next = null;
this.random = null;
}
}
*/
class Solution {
public Node copyRandomList(Node head) {
Node temp = head;
if(head==null)
return null;
//原地复制链表
while(temp!=null){
//进行值的复制
Node cur = new Node(temp.val);
cur.next = temp.next;
temp.next = cur;
temp = cur.next;
}
temp = head;
//看看是不是复制成功了
while(temp!=null){
System.out.println(temp.val);
temp = temp.next;
}
temp = head;
//进行random指针的复制
while(temp!=null){
Node cur = temp.next;
if(temp.random!=null)
cur.random = temp.random.next;
temp = cur.next;
}
//进行两个队列的分离
Node dummy = new Node(0);
Node cur = head.next;
temp = head;
dummy.next = cur;
while(temp!=null){
//获取新链表
cur = temp.next;
//旧表复原
temp.next = temp.next.next;
//新表重新指向
if(cur.next!=null)
cur.next = cur.next.next;
temp = temp.next;
}
return dummy.next;
}
}
设计循环队列(略)
(略,代码量比较大并且自认为熟练掌握)
需要关注的一个重点是循环队列的判断满的方式:
- 如果包含长度参数则可以全部利用空间
- 如果使用指针判断则需要牺牲一个单位空间
设计前中后队列 leetcode—1670
请你设计一个队列,支持在前,中,后三个位置的 push 和 pop 操作。
请你完成 FrontMiddleBack 类:
- FrontMiddleBack() 初始化队列。
- void pushFront(int val) 将 val 添加到队列的 最前面 。
- void pushMiddle(int val) 将 val 添加到队列的 正中间 。
- void pushBack(int val) 将 val 添加到队里的 最后面 。
- int popFront() 将 最前面 的元素从队列中删除并返回值,如果删除之前队列为空,那么返回 -1 。
- int popMiddle() 将 正中间 的元素从队列中删除并返回值,如果删除之前队列为空,那么返回 -1 。
- int popBack() 将 最后面 的元素从队列中删除并返回值,如果删除之前队列为空,那么返回 -1 。
请注意当有 两个 中间位置的时候,选择靠前面的位置进行操作。比方说:
将 6 添加到 [1, 2, 3, 4, 5] 的中间位置,结果数组为 [1, 2, 6, 3, 4, 5] 。
从 [1, 2, 3, 4, 5, 6] 的中间位置弹出元素,返回 3 ,数组变为 [1, 2, 4, 5, 6] 。
解题思路
对于长存储空间单点操作可以用链表来实现,但是这道题目要求在存储的前中后3个位置进行添加和删除动作,如果用单向链表则不利于尾部删除一个元素后重新定位,因此可以采用双向链表来实现设计需求。
整体设计中需要关注的就是前段的长度和后端的长度,其余只需要符合双向链表的添加和删除即可。
(以上是我的解题思路,我认为性能足够优秀了,但是依然看一下课程上的思路是什么)
课上的解决思路为用单向链表实现双端队列。
(为什么不使用双向链表?)
(改为使用双向链表了,跟我的设计方法一致,那就看有没什么先进的思想)
(课上写的更为严谨,但逻辑是一样的)
示例代码
(略写多余的部分,仅记录双向链表节点类的设计前后添加删除的方法)
(下方这个类,添加和删除都不会移动自身的指针,适用题中的各种情况)
class Node {
int val;
Node pre;
Node next;
//构造方法
public Node(int val ,Node pre,Node next){
this.pre = pre;
this.val = val;
this.next =next;
}
//front push
public void pushFront(int val){
Node wantPush = new Node(val,null,null);
//防止为空
if(pre!=null){
pre.next = wantPush;
wantPush.pre = pre;
}
wantPush.next = this;
this.pre = wantPush;
}
//front pop
public Integer popFront(){
int wantPopVal = 0;
if(pre!=null){
wantPopVal = pre.val;
if(pre.pre!=null){
pre.pre.next = this;
this.pre = pre.pre;
}else
this.pre = null;
return wantPopVal;
}else
return null;
}
//Back push
public void pushBack(int val){
Node wantPush = new Node(val,null,null);
//防止为空
if(next!=null){
next.pre = wantPush;
wantPush.next = next;
}
wantPush.pre = this;
this.next = wantPush;
}
//Back pop
public Integer popBack(){
int wantPopVal = 0;
if(next!=null){
wantPopVal = next.val;
if(next.next!=null){
next.next.pre = this;
this.next = next.next;
}else
this.next = null;
return wantPopVal;
}else
return null;
}
}
最近请求数 leetcode—933
写一个 RecentCounter 类来计算特定时间范围内最近的请求。
请你实现 RecentCounter 类:
- RecentCounter() 初始化计数器,请求数为 0 。
- int ping(int t) 在时间 t 添加一个新请求,其中 t 表示以毫秒为单位的某个时间,并返回过去 3000 毫秒内发生的所有请求数(包括新请求)。确切地说,返回在 [t-3000, t] 内发生的请求数。
保证 每次对 ping 的调用都使用比之前更大的 t 值。
解题思路
(本题为简单题,略过代码)
首先时间t这个参数可以理解为时间轴,并且是递增的,所以如果有记录超出了需要关注的范围[t-3000, t]则可以删除。
因此可以用队列的方式实现。
每一次调用进行一次入队,要求队列的元素包含时间戳的概念。
返回的内容就是队列的长度,返回前先判断一下队首这个单元的时间戳是否超时,如果超时就出队,持续这个动作直到某一个单元的时间戳没有超时在范围[t-3000, t]内,返回队列长度。
(以上为我的思路,和课堂意思一致)
拓展思考例题
下方题目和本课知识点不强相关,用作思维的练习。
第K个数 leetcode—面试17.09
有些数的素因子只有 3,5,7,请设计一个算法找出第 k 个数。注意,不是必须有这些素因子,而是必须不包含其他的素因子。例如,前几个数按顺序应该是 1,3,5,7,9,15,21。
示例 1:
输入: k = 5
输出: 9
解题思路
(先记录课上的思路,我的方案是错误的)
(以下是课上的思路)
以下为课堂的思路:
- 首先定义一个队列,令3个指针(p3,p5,p7)先最先指向1
- 每一轮每一个指针都试图生成数字,将生成最小数字加入队列(3,5,7)存入3,随后指针移位仅移位执行了动作的指针(目前是p3,p3目前指向了3,其余不变),移动一位(在数列中,下一位是添加了的3)
- 类推下一轮,生成的为(5,7,9),移动p5,其余不变。(p5原本在1,计算完毕一次后压入5,移动到3)
- 当某一试图加入的数字
文字演示:
p3=3,p5=1,p7=1,>3 ,[1,3]
p3=3,p5=3,p7=1,>5 ,[1,3,5]
p3=3,p5=3,p7=3,>7 ,[1,3,7]
p3=5,p5=3,p7=3,>9 ,[1,3,7,9]
p3=7,p5=5,p7=3,>9 ,[1,3,7,9,15] //这一轮3和5的指针都算出了15并加入,因此都向后一位
p3=9,p5=5,p7=5,>9 ,[1,3,7,9,15,21]//这一轮3和7的指针都算出了21并加入,因此都向后一位
p3=9,p5=7,p7=5,>9 ,[1,3,7,9,15,21,25]
……
(至此明白了,在之前我试图用类似的方法计算,但是没有考虑到指针的概念,所以做不出来,这道题不应该使用队列,在java端应该使用动态可增长数组来进行管理:ArrayList)
(然后课上讲了以下为什么这个方式可以不漏选,不重复)
不重复:
待计算的指针下一步生成的数字必然大于最后存储的数字(因为上一次计算的结果的最小值被存储,并且计算单元后移一位必然能算出更大的数字)
不漏选:
任意一个数字如果漏选则意味着,其因数的上一次计算不在指针移动的路线上,但是这不可能发生。因为指针一次只移动一位,指针所经过的路线为符合条件的数字,如果一次出现漏选则说明符合这个条件的指针上一个位置不在应该所处的位置上。 那么对于上一个位置而言同样是漏选的,所以可以持续追溯到这个指针一开始就不再路线上,但是这不可能,因为初始条件定义了指针必然在路线上。
(以下是我的思路)
方案1:直接计算 (性能过低因此舍弃。)
拆解所有正数,选择因数只有3、5、7的数字,每取到取到第k位停止。这个计算方式在k较大时需要大量的计算。
方案2:找数字变化的规律。(设计有错因此舍弃)
本题的思路为 3,5,7的任意幂次进行相乘,将结果进行排列输出,计算公式为:
f=3^a*5^b*7^c(a、b、c为任意自然数)
不进行简化,本题的计算方式为,取任意自然数进行计算,将结果进行排序,但是实际上并非如此。
要充分利用这3个最小计算单元来进行使用,对于任一个正数:
- 乘以3的结果都是小于乘以5的结果的,
- 乘以5的结果都是小于乘以7的结果的,
- 乘以5和7的结果都是小于乘以两次3的
然后组合这3个最小单元生成更高一级的最小单元
- 3乘以7小于5乘以5
- 3乘3乘3小于5乘以7
- 3乘3乘5小于7乘以7
因此根据排序会有11个计算单元
3
5
7
9
15
21
25
27
35
45
49
任一个数在试图获取下一个数字时都是应试图将自身的单元替换成能级更高一级的单元进行计算
对于1,——》3
对于3,——》5
对于5,——》7
对于7,——》没有单元了换用能级更低的3来跨级-》3,3——》9
对于9,——》15
对于15,——》21
对于21,——》查分成单元升级——》25
对于25,——》拆分成单元升级——》27
对于27,——》拆分成单元升级——》35
对于35,——》用9替换7——》45
对于45,——》9和5用77来换——》49
对于49,——》7换成9——》63
对于63,——》7,3,3——21换成25——》75
综上能级交换的原则是能从高到低优先向上进一位,
比如45包含了3,5,9,15,45,5个能级单元,因此进为最高能级45为49,其余不变。
比如63包含了3,7,9,21,4个能级单元,因此进位最高能级21为25,其余不变。
(可能会重复吗?不会重复,因为每一个数字都必然比前一个数字大)
(这个思路会有遗漏吗?很可能会有,这个思路的原理是任意个一个满足数列条件的数都可能是由之前的某一个数进行能级代换升级)
(能级替换的方式为试图获取符合能级表的最大因数,去能级表查看是否还有更大的,如果有就换成更大的数字;其余因数不变,如果没有更大的因数,则用次级能级升级为更大的能级进行使用)
(这样会遗漏吗?)
证明一下:
证明完毕,确实遗漏了。
(正如21后是25一样,在对于单一能级进行提升时,可以通过降低另一个能级来减少提升的幅度)
(反思了一下我的思路在提出公式f=3^a*5^b*7^c后先试图进行枚举幂指数然后进行排序,对于这个设计我选择了放弃,因此我的潜意识中认为,用某一个状态的数值乘以某一数值生成目标值的方式不可用,于是在接下来的设计过程中开始关注,两个相邻的数字间的关系)
(也就是出现了思考维度不足的缺陷,设计算法时,更需要高维度的思维,而非低维度的思维)
(逻辑论述时,需要低维度的思维而非高维度的思维)
(那么如果非要按着我的能级方式进行计算应该怎么做)
(应该是用枚举的方式在升级时尝试降级,用穷举的方式逼近目标能级)
(真正值得反思的问题是,我对于这个中等难度的题思考了过久,在单一的方案上思考过深入,在初期出现漏洞时尝试进行填补,而不是反思逻辑的不足,导致在提出前3个能级的概念失败后迅速尝试进行提出更高的能级理论去填充设计的缺陷)
(这种习惯需要改正,所以以上内容留作纪念)
示例代码
课上思路的解决方案:
(只要有思路了写起来就很容易)
class Solution {
public int getKthMagicNumber(int k) {
ArrayList <Integer> arr = new ArrayList<Integer>();
int index3=0;
int index5=0;
int index7=0;
arr.add(1);
while(--k>0){
int num3 = arr.get(index3);
int num5 = arr.get(index5);
int num7 = arr.get(index7);
num3 *=3;
num5 *=5;
num7 *=7;
int addnum;
addnum = Math.min(num3,num5);
addnum = Math.min(addnum,num7);
arr.add(addnum);
if( addnum == num3)
index3 ++;
if( addnum == num5)
index5 ++;
if( addnum == num7)
index7 ++;
}
int len = arr.size();
return arr.get(len-1);
}
}
亲密字符串 leetcode—859
给定两个由小写字母构成的字符串 A 和 B ,只要我们可以通过交换 A 中的两个字母得到与 B 相等的结果,就返回 true ;否则返回 false 。
交换字母的定义是取两个下标 i 和 j (下标从 0 开始),只要 i!=j 就交换 A[i] 和 A[j] 处的字符。例如,在 “abcd” 中交换下标 0 和下标 2 的元素可以生成 “cbad” 。
解题思路
本题为简单题。
首先这两个字符串必须等长,并且有可以交换的元素(长度相等且大于等于2)。
这里首先可以判断一次字符串相等的情况,如果相等有重复字符则可以通过交换重复字符来实现目标,否则不能。
接下来就只考虑字符串不相等的情况。
其次又由于只能交换一个字符,所以根据字符串是否相同,要将字符串切分成3份,交换前,交换中,交换后,这3份必须完全相同(但是可以没有长度)。
接着两个字符串不同的位置必须各自有且只能为2个字符,并且将一个字符串中的不同字符进行调换后要和另一个字符串相同。
(很简单,没有参考价值不写代码了)
柠檬水找零 leetcode—860
在柠檬水摊上,每一杯柠檬水的售价为 5 美元。
顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。
每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零,也就是说净交易是每位顾客向你支付 5 美元。
注意,一开始你手头没有任何零钱。
如果你能给每位顾客正确找零,返回 true ,否则返回 false 。
解题思路
(简单题略)
本题的计算方式为优先考虑进行大面额的找零,其次是小面额。
(这种优先级的考虑方式尝试,属于贪心算法的思维)
煎饼排序 leetcode—969
给你一个整数数组 arr ,请使用 煎饼翻转 完成对数组的排序。
一次煎饼翻转的执行过程如下:
选择一个整数 k ,1 <= k <= arr.length
反转子数组 arr[0…k-1](下标从 0 开始)
例如,arr = [3,2,1,4] ,选择 k = 3 进行一次煎饼翻转,反转子数组 [3,2,1] ,得到 arr = [1,2,3,4] 。
以数组形式返回能使 arr 有序的煎饼翻转操作所对应的 k 值序列。任何将数组排序且翻转次数在 10 * arr.length 范围内的有效答案都将被判断为正确。
示例图:

解题思路
这道题目很有意思,本质上是一个数组的排序动作,但是相比起一般的排序,这种排序方式需要调换区域内的全部数字的顺序。这种翻转的方式就像将一个煎饼进行翻面一样,所以称为煎饼排序。
这道题输出的结果为,每一次翻转动作执行时候所采用的翻转范围(显然k可以为1但是没有必要)
从题意可以推算,一个k值只能进行一次翻转。
并且如果需要调换两个元素的位置可以先翻转一整块再翻转这两个元素之间的一块。
(元素间距0或者1可以不进行翻转)
首先可以有一个简单思路,使用冒泡排序。而冒泡排序每一次只需要操作2个相邻值。但是考虑到操作数要小于等于10*len(时间复杂度要小于nlogn),所以不可以使用冒泡排序。
那么其次就是快排,快排的概念为通过交换数字的位置,使得大于某一个数的值全在该数的左侧,小于某一个数的值全在该数的右侧。但是快排最差的时间复杂度也为(n2),并且依然是交换动作很多。
接着是插入排序,我是否可以通过检索最小的数字将这个数放到首位,可以只需要进行一次交换,其次我是否可以通过检索次小的数字将这个数字放到首位,可以只需要进行一次交换。这种方式的时间复杂度较高,但是交换的动作少,最多为n次,因此这种方式是可用的。
(此处我已经得出了方案,理论上我需要调换的次数为len次,那么是否可以采用快排呢?我暂时没有考虑清楚)
(接下来看课堂的思维)
(课上讲只能翻转前n位?)
(我认为题目没有说只能为前n位 ,如果是只能为前n位,那么我选择插入排序从尾部向前排序)
(题目有讲反转子数组 arr[0…k-1],所以还是我读题不仔细)
(我的解题思路是正确的,但是读题不仔细浪费了我的时间)
(代码没有参考价值略过)
任务调度 leetcode—621
给你一个用字符数组 tasks 表示的 CPU 需要执行的任务列表。其中每个字母表示一种不同种类的任务。任务可以以任意顺序执行,并且每个任务都可以在 1 个单位时间内执行完。在任何一个单位时间,CPU 可以完成一个任务,或者处于待命状态。
然而,两个 相同种类 的任务之间必须有长度为整数 n 的冷却时间,因此至少有连续 n 个单位时间内 CPU 在执行不同的任务,或者在待命状态。
你需要计算完成所有任务所需要的 最短时间 。
示例 3:
输入:tasks = [“A”,“A”,“A”,“A”,“A”,“A”,“B”,“C”,“D”,“E”,“F”,“G”], n = 2
输出:16
解释:一种可能的解决方案是:
A -> B -> C -> A -> D -> E -> A -> F -> G -> A -> (待命) -> (待命) -> A -> (待命) -> (待命) -> A
解题思路
首先这个题目的意思要理解清楚。
(吸取一下教训多读题)
这个题目的意思就是相同任务间必须间隔若干的时间,因此如果想要总时间最短就需要让一个任务在等待的时候去执行另一个任务。
因此总体上就是在每一次执行任务的时候,都试图执行先执行未CD的数量最多的任务。
实现的方法为使用队列,每一个任务做一个队列,存入行为组(执行或者CD),每一个时间周期在CD的任务队列执行出队动作,并且找一个未CD的任务,并且总长最长的任务进行执行。直到所有的队列为空。
最后记录时间周期总长。
(以上是我的思路,看看课程怎么讲)
课上的思路为排布任务,先执行最多的任务,并且用其他任务去填充冷却时间,最后计算总面积
讨论两种情况,
一种情况为所有的冷却时间都被利用
一种是存在部分任务有冷却时间
于是对于存在部分任务有冷却时间先提出了一个公式。
最多的任务为m个,任务的CD为n,最多的任务长度为len
则理论上所需的动作位数为:
(len-1)*(n+1)+m
(**这部分的思路:**假设有空,那么一定是最多的任务需要进行最多的CD轮次。因此用其他任务来填充这个任务空缺)
随后在
进行任务总数量和格子的总数量之间取一个最大值
(没看懂这部分讲了什么)
(意思应该是讨论所有的任务执行过程中有多少格子可以被填满的问题)
(从数学角度进行的推演)
当任务总数目大于任务生成的格子数目的时候,那么最大耗时就是任务数目
否则是任务生成的格子数目。
(至此看懂了)
解决方案为:
对于所有任务进行统计然后进行排序。
随后计算最多的任务数量为m,计算最大的任务长度为len;
并且计算有多少任务跟这个最大格子数,
两个数取最大值。
(这个方案从数学角度去解决了问题)
(这个方案的兼容性没有我的方案来的好,我的方案可以解决任意任务间隔CD的情况也就是可以支持每种任务不同的CD的问题,但是对于这个问题课上的解决性能更为优秀)
(对此我不认为是我读题不仔细导致的,我思考问题习惯找通解而非特解,更善于做整体的归纳,所以我记录这两种方案)
示例代码
(课上的方案)
class Solution {
public int leastInterval(char[] tasks, int n) {
//第一步所有单元进行排序
Arrays.sort(tasks);
//第二步对于所有单元获取最大的任务组长度
int tasksLen[] = new int [26];
int index = 0;
tasksLen[0] = 1;
int maxLen = 1;
for(int i=1;i<tasks.length;i++){
//如果某一位和前一位不同
if(tasks[i-1]!=tasks[i]){
index ++;
}
tasksLen[index]++;
if(tasksLen[index]>maxLen)
maxLen = tasksLen[index];
}
//第三步获取最大长度相同的任务数目
int maxNum = 0;
for(int i=0;i<=index;i++){
System.out.println(tasksLen[i]);
if(maxLen == tasksLen[i])
maxNum++;
}
System.out.println(maxNum);
System.out.println(maxLen);
//第四步用公式进行计算
int res = (maxLen-1)*(n+1)+maxNum;
return Math.max(res,tasks.length);
}
}
(我的方案)
(设计时需要采用链表而非数组,否则会超时)
(我认为我的这套设计,还能够输出任务耗时最小时的,任务调度安排,因此同样具有参考意义)
class Solution {
public int leastInterval(char[] tasks, int n) {
//首先进行任务种类长度的计算
//第一步所有单元进行排序
Arrays.sort(tasks);
int tasksLen[] = new int [26];
int index = 0;
tasksLen[0] = 1;
for(int i=1;i<tasks.length;i++){
//如果某一位和前一位不同
if(tasks[i-1]!=tasks[i]){
index ++;
}
tasksLen[index]++;
}
//至此获得每个任务种类的数目。
//创造各个任务所处线程的时钟队列
LinkedList<LinkedList<Boolean>> taskThreadGroup =
new LinkedList<LinkedList<Boolean>>();
while(index>=0){
LinkedList<Boolean> taskThread = new LinkedList<Boolean>();
//每个线程如果有任务则至少一个任务
taskThread.add(true);
for(int i= 1;i<tasksLen[index];i++){
//每一个任务需要先休息n时钟动作
for(int j=0;j<n;j++)
taskThread.add(false);
//然后再执行
taskThread.add(true);
}
//添加到线程组中
taskThreadGroup.add(taskThread);
index--;
}
//开始执行
int res = 0;
for(;;){
//首先找一个任务队列最长的任务进行执行
//但是要求这个任务不在CD
int maxLen = -1;
int maxIndex = -1;
for(int i = 0; i< taskThreadGroup.size();i++){
LinkedList<Boolean> taskThread = taskThreadGroup.get(i);
if(taskThread.size()>0)
if(taskThread.size()>maxLen){
//只有这个任务可以执行才进行提取
if(taskThread.get(0)){
maxLen = taskThread.size();
maxIndex = i;
}
}
}
//将所有在CD的任务,时钟推进一位
boolean CDFlag = false;
for(int i = 0; i< taskThreadGroup.size();i++){
LinkedList<Boolean> taskThread = taskThreadGroup.get(i);
if(taskThread.size()>0)
if(!taskThread.get(0)){
CDFlag = true;
taskThread.remove(0);
}
}
//找到可以执行的任务了
if(maxIndex>=0){
LinkedList<Boolean> taskThread = taskThreadGroup.get(maxIndex);
//可执行的任务时钟推进一位,并执行
taskThread.remove(0);
}
//当没有任务可以执行并且没有任务在等待cd时,所有的任务执行完毕
if(!CDFlag&&maxLen==-1){
break;
}
//还可以选择判定任务线程池为空,认为所有任务执行完毕
//在此记录任务时钟进一位
res++;
}
return res;
}
}
结语
- 本次调试采用的编译环境为leecode,上一次采用的是牛客网,从个人使用手感来看,牛客网的好一些,有更多的自动输入补全功能。
- 此外,在整理笔记时,在绘制示意图上浪费了大量的时间,并且不美观,后续需要对此进行研究。
- 解题时,比思考解决方案更重要的是观察现象,充分的观察可以使得自身获取更多的可利用资源。
- 本次我的采用的学习方法为先看大纲,自行解题,记录自身的解题思维,如果课堂有更好的思维再额外记录,由于本次上课时较为忙碌,所以是看录播视频进行的学习更好掌握学习节奏。
- 对此我存疑?有大纲吗,我忘记了,后续如果找到了,那就删除这句话。
(本课的例题138、面试17.09,969自身没能实现最优的解法需要额外复习。)
(138的不足为没有充分集中注意力,未能充分使用题目的资源,总结为自身注意力不集中)
(17.09的不足为没有及时放弃错误的逻辑,思考问题不够全面)
(969的不足为读题不仔细,总结为自身注意力不集中)
在学习的中后期,我基本放弃了画示意图,后续我认为我需要研究一个更好的示意图绘图方案。

















 1953
1953




 到【灌水乐园】发言
到【灌水乐园】发言







