



2022/3/15
1.导入两个库
Numpy计算
Pandas 开源用于数据分析的工具
Import numpy as np
Import pandas as pd
import os #用于os.getcwd()查找文件路径
2.使用相对/绝对路径导入数据
相对:
pd.read_csv #将csv文件读入并转化为数据框形式
#return dataframe or textparser
df=pd.read_csv('C:\\Users\\71403\\Desktop\\titanic\\train.csv') #df 选取
#这里一直报错
#AttributeError:函数名写错
#SyntaxError:语法错误-打成中文字符
#osError:文件路径的格式出错
#permission denied:右键属性开启权限/xx计算机名/user
#filednotfound:cvs文件和代码放一个文件夹
df.shape #显示(行,列)
df.head() #显示dataframe数据框的头部
df.tail(3) #尾部数据
#df.index 显示索引
#df.columns 显示列名
3.pd.read_table(path) #以行为单位存储,没有分割
pd.read_csv #用逗号进行分割
#如何让read_table &read_csv表的形式一致?
Pd.read_table(path,sep=’,’) #限定分割符以逗号分割
4.逐块读取数据
df=Pd.read_csv(‘train.csv’,chunksize=1000) #以每一千行为一块
df.head()
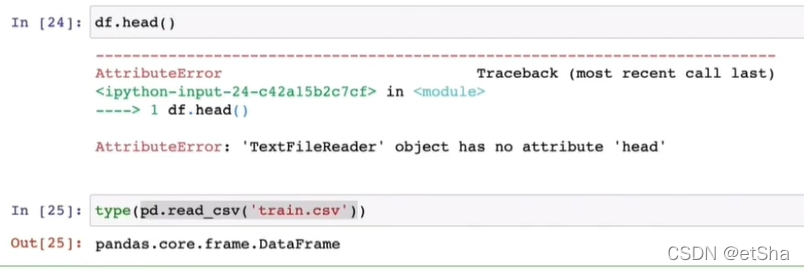
这里类型已经变了,故报错
Type(df)
Df.get_chunk()
5.将表头改为中文
方法一:表头替换
#先取消分块
Df=pd.read_csv(‘train.csv’)
Df.column=(‘’,’’,’’,…)
Df
#方法二 读取文件时直接重新命名/多加表头
Df=pd.read_csv(‘train.csv’,name=[‘’,’’,’’,…])
Df
6.展示头部及尾部数据
Df.tail()
Df.tail(15).shape #显示行列
Df.head(10) #显示前九行数据
7.显示空值数据
Df.isnull()
8.df.to_csv(‘train_chinese.csv’)


















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









