




目 录
0、概述
在上一篇文章中,我们对训练集的各个特征已经有了初步了解,并提取出了九个可用的特征:
Pclass、Age、SibSp+Parch、Fare、Sex、Name、Ticket、Cabin、Embarked。
本篇文章中,将继续跟着该网址的第三部分和第四部分,对数据进行清洗,并且进行模型训练。
1、数据清洗
数据清洗主要有两部分工作:第一部分为缺失值填充,第二部分为异常值处理。
1.1 缺失值填充
在前一篇文章我们说过,训练集和测试集的数据中,有部分数值为NaN,这部分数值我们要进行填充:

主要是Age、Embarked、Fare,Survived是我们要预测的,不用填。
1.1.1 Age填充
Age缺失263个,因此要填充263个。缺失量较大。不能用平均数、中位数、众数等直接填充,要利用算法进行预测。
这里选择采用随机森林算法。有关随机森林的知识,请参阅该网址。代码如下:
from sklearn.ensemble import RandomForestRegressor
age_df = all_data[['Age', 'Pclass','Sex','Title']]
age_df=pd.get_dummies(age_df)
known_age = age_df[age_df.Age.notnull()].as_matrix()
unknown_age = age_df[age_df.Age.isnull()].as_matrix()
y = known_age[:, 0]
X = known_age[:, 1:]
rfr = RandomForestRegressor(random_state=0, n_estimators=100, n_jobs=-1)
rfr.fit(X, y)
predictedAges = rfr.predict(unknown_age[:, 1::])
all_data.loc[ (all_data.Age.isnull()), 'Age' ] = predictedAges 首先要安装sklearn这个库,这个库里面集成了许多常用的机器学习算法,有了这个我们就可以当一个入门的调参工程师了。但是conda不能直接用conda install sklearn安装这个库,在源里面找不到,要用如下这条命令:
conda install -c anaconda scikit-learn才可以。
放假回家这移动网下点外网的东西简直欲仙欲死,恰逢国庆,飞机场又都被封,只能靠这辣鸡网度日了。
随机森林算法在这里我们是作为一个分类器使用的,既然是分类器,就有输入输出。输入由我们自己选定,这里选择了三个可用的特征:Sex、Pclass、Title。输出为Age。本质上就是用这三个输入来预测输出。
所以我们要先把所有数据中的这四个特征拿出来,保存在age_df这个矩阵中:
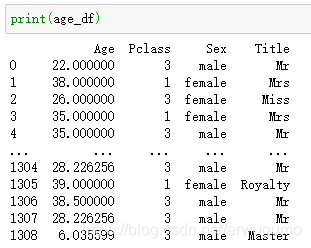
嗯,1309个数据全部导入。每个数据都有四个特征。
然后需要将上面这个矩阵向量化。如何向量化?就是将非数值的量转为数值量。比如说对于Sex,这一列是一个向量,每个向量元素有两个取值male和female,那么将其转换为数值量0和1,就变成两列:Sex_male和Sex_female。对于每个Sex的值,若是male,则新的Sex_male列对应的值为1,Sex_female的值为0。对于Title也一样,只不过要拓展成的列多一点。这样,一个元素的可能取值为n个值,就变成了n列向量,这n列向量的元素或者为0,或者为1。如下,是原矩阵经变换后得到的新矩阵:
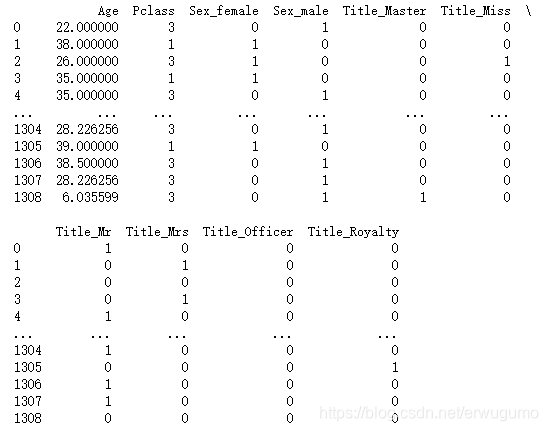
这个新矩阵的最大优点为所有元素均为数字,可以直接输入使用。
然后我们要将整个数据集分为两部分:第一部分的Age已知,第二部分的Age未知。即第一部分为训练集,第二部分为要预测的数据。怎么把这两部分分开呢?用的就是第四行和第五行的代码:
known_age = age_df[age_df.Age.notnull()].as_matrix()
unknown_age = age_df[age_df.Age.isnull()].as_matrix()我们知道,Age不存在的元素值为NaN,因此用notnull函数可以筛选出所有的Age已知的行,用isnull可以筛选出未知的行。注意无论是isnull还是notnull,返回的都是一个包含True和False对应的向量,然后用布尔下标的方法筛选出对应的行。这时返回的是一个DataFrame,我们要将这个DataFrame转换成一个数组,因此要调用as_matrix函数。如下图:
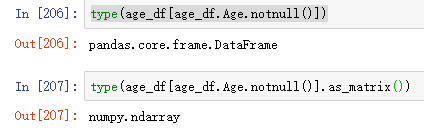
从DataFrame转换成了ndarray。
known_age的内容如下所示:

有点乱啊,不过可以看出来第一个是Age,然后是Pclass、Sex什么的。
这部分是训练集。训练集的输入和输出要分开。观察训练集known_age可知,训练集的输入为第二列及之后,输出应该为第一列。因此我们设置X为第二列及之后,y为第一列。
接下来是重头戏:随机森林的调用。sklearn库里面有两个随机森林,一个用于分类(RandomForestClassifier),一个用于回归(RandomForestRegressor),我们当然要用回归的随机森林了。
使用随机森林需要调用RandomForestRegressor函数,该函数的参数参见该网址。
我们调整了三个参数:
random_state=0:此参数让结果容易复现。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1306
1306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









