






 文章介绍了MySQL读写分离的重要性,以及两种常见的实现方案:程序代码内部实现和基于中间代理层(如mysql-proxy和Amoeba)的实现。重点讲述了Amoeba的安装配置和读写分离、负载均衡的测试,展示了Amoeba如何在Java环境下工作,确保数据的安全性和并发处理能力。
文章介绍了MySQL读写分离的重要性,以及两种常见的实现方案:程序代码内部实现和基于中间代理层(如mysql-proxy和Amoeba)的实现。重点讲述了Amoeba的安装配置和读写分离、负载均衡的测试,展示了Amoeba如何在Java环境下工作,确保数据的安全性和并发处理能力。
一、概述
在实际的生产环境中,如果对数据库的读和写都在同一个数据库服务器中操作,无论是安全性,高可用还是并发等各个方面都不能完全满足实际需求的,因此一般来说都是通过主从复制的方式来同步数据,再通过读写分离来提供数据的高并发负载能力这样的方案来进行部署。
简单来说,读写分离就是只在主服务器上写,只在从服务器上读,基本的原理是让主数据库处理事务性查询,而从数据库处理select查询,数据库复制被用来把事务性查询导致的改变更新同步到集群中的从数据库。
二、目前最常见的MySQL读写分离方案有两种
1.基于程序代码内部实现
在代码中根据select,insert进行路由分类,这类方法也是目前大型生产环境应用最广泛的,优点是性能最好,因为在程序代码中实现,不需要增加额外的设备作为硬件开支,缺点是需要开发人员来实现,运维人员无从下手
2.基于中间代理层实现
代理一般位于客户端和数据库服务器之间,代理服务器接到客户端请求后通过判断转发到后端数据库,代表性程序:
(1)mysql-proxy为mysql开发早期开源项目,通过其自带的lua脚本进行SQL判断,虽然是mysql的官方产品,但是mysql官方不建议将其应用到生产环境。
(2)Amoeba(变形虫)该程序由java语言及逆行开发,阿里巴巴将其应用于生产环境,它不支持事物和存储过程。
Amoeba(变形虫)项目开源框架于2008年发布一款Amoeba for mysql软件,这个软件致力于mysql的分布式数据库前端代理层,主要为应用层访问mysql的时候充当SQL路由功能,并具有负载均衡,高可用性,SQL过滤,读写分离,可路由到相关的目标数据库,可并发请求多台数据库,通过Amoeba能够完成多数据源的高可用,负载均衡,数据切片的功能,目前Amoeba已经在很多企业的生产线上使用。
三、在主机Amoeba上安装java环境
因为Amoeba是基于jdk1.5版本开发的,所以官方推荐使用1.5或者1.6版本,高版本不建议使用。
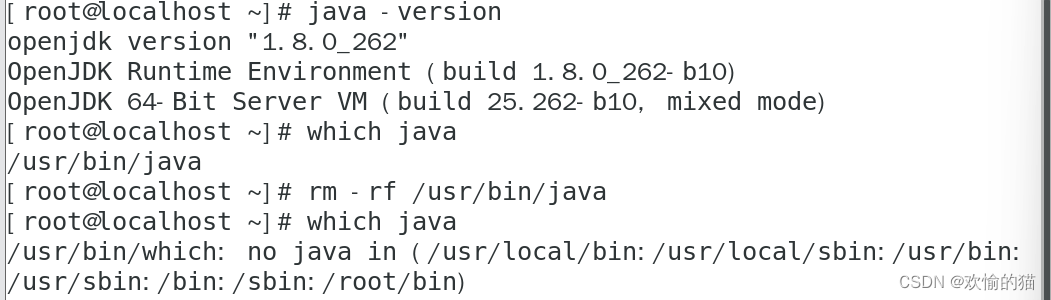
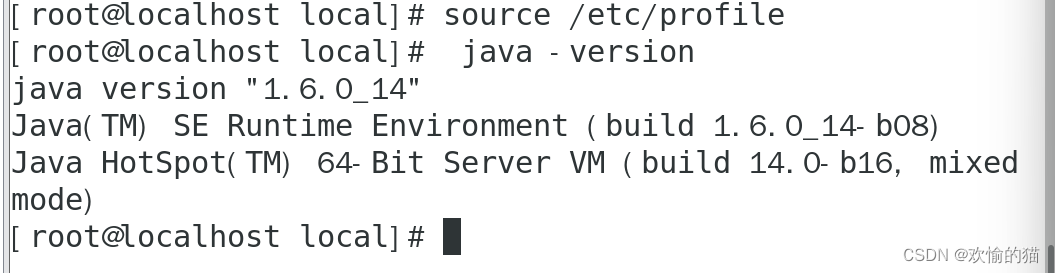
重新配置我们的Java环境,事先准备好的Java环境拖入终端,按照提示配置


2、安装并配置Amoeba
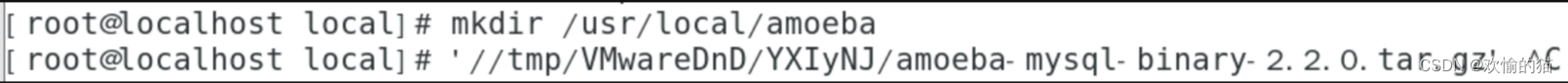
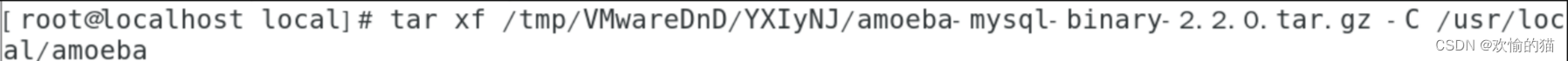
![]()
![]()

3、配置Amoeba读写分离,两个Slave读负载均衡
在Master、Slave1、Slave2服务器中配置Amoeba的访问授权
例如:
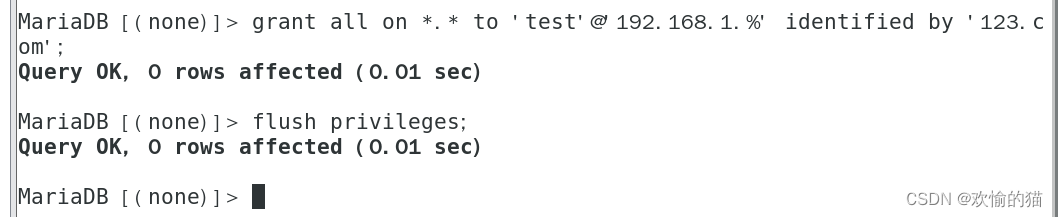
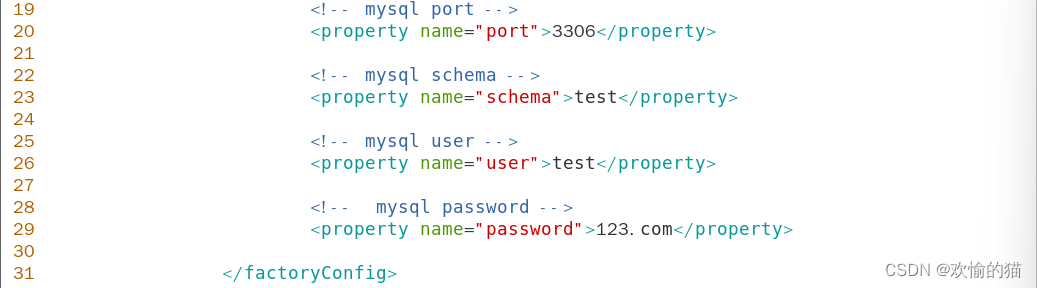
编辑amoeba.xml配置文件 vim /usr/local/amoeba/conf/amoeba.xml


编辑dbServer.xml配置文件 vim /usr/local/amoeba/conf/dbServers.xml
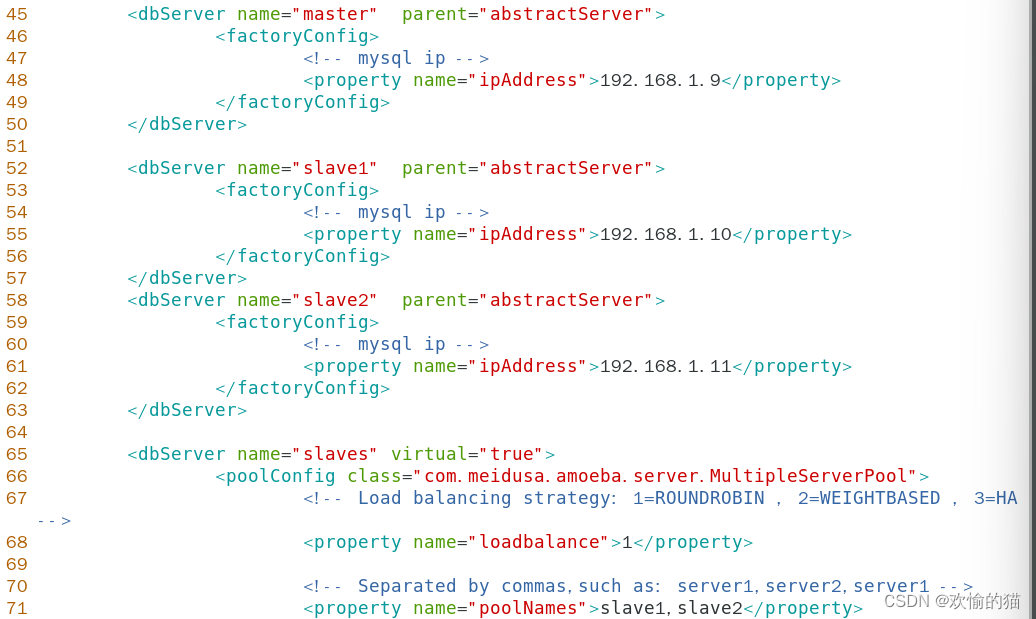
配置无误后,启动Amoeba软件,默认端口是TCP协议8066
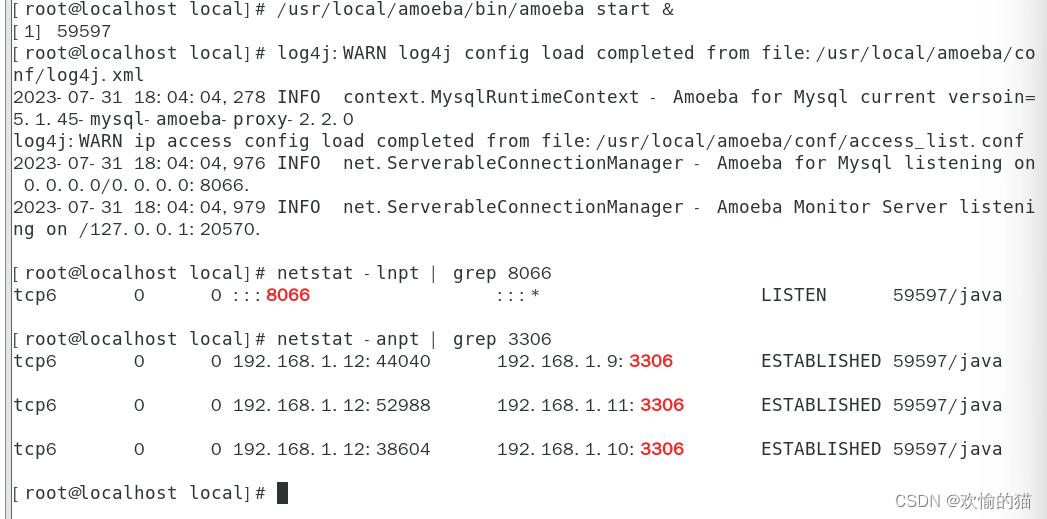 在Client上进行访问测试然后可以通过代理访问MySQL
在Client上进行访问测试然后可以通过代理访问MySQL
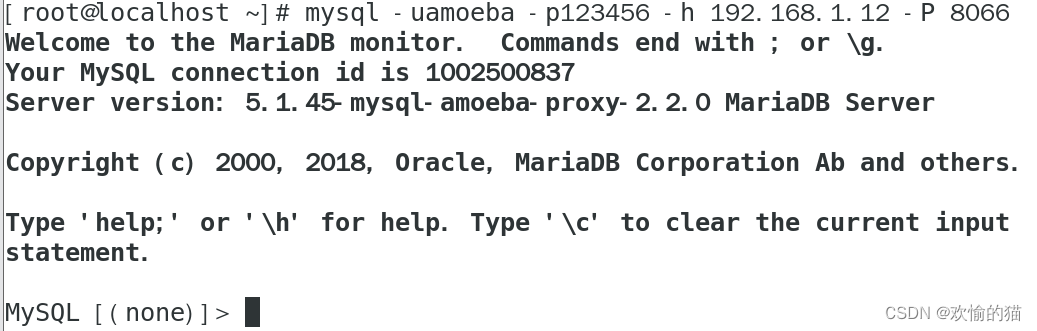
在MySQL主服务器上创建一个表,会自动同步到各个从服务器上,然后关掉各个服务器上的Slave功能,在分别插入语句测试。
主服务器
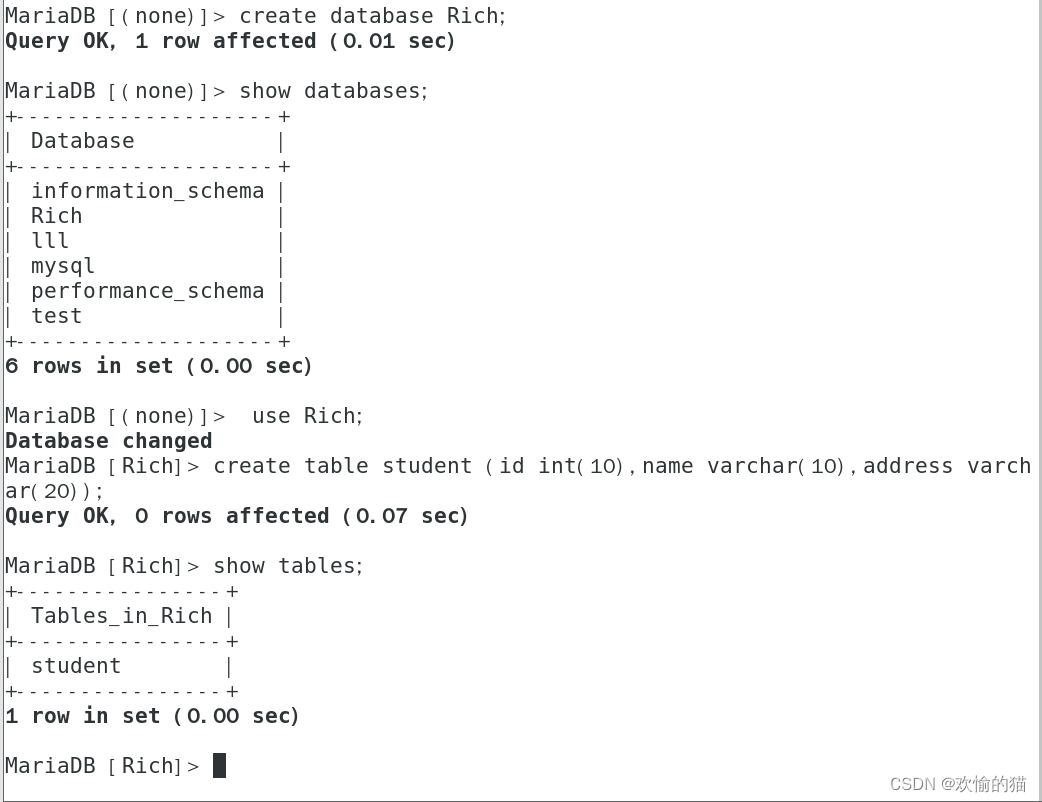
分别在两台从服务器上
Slave1
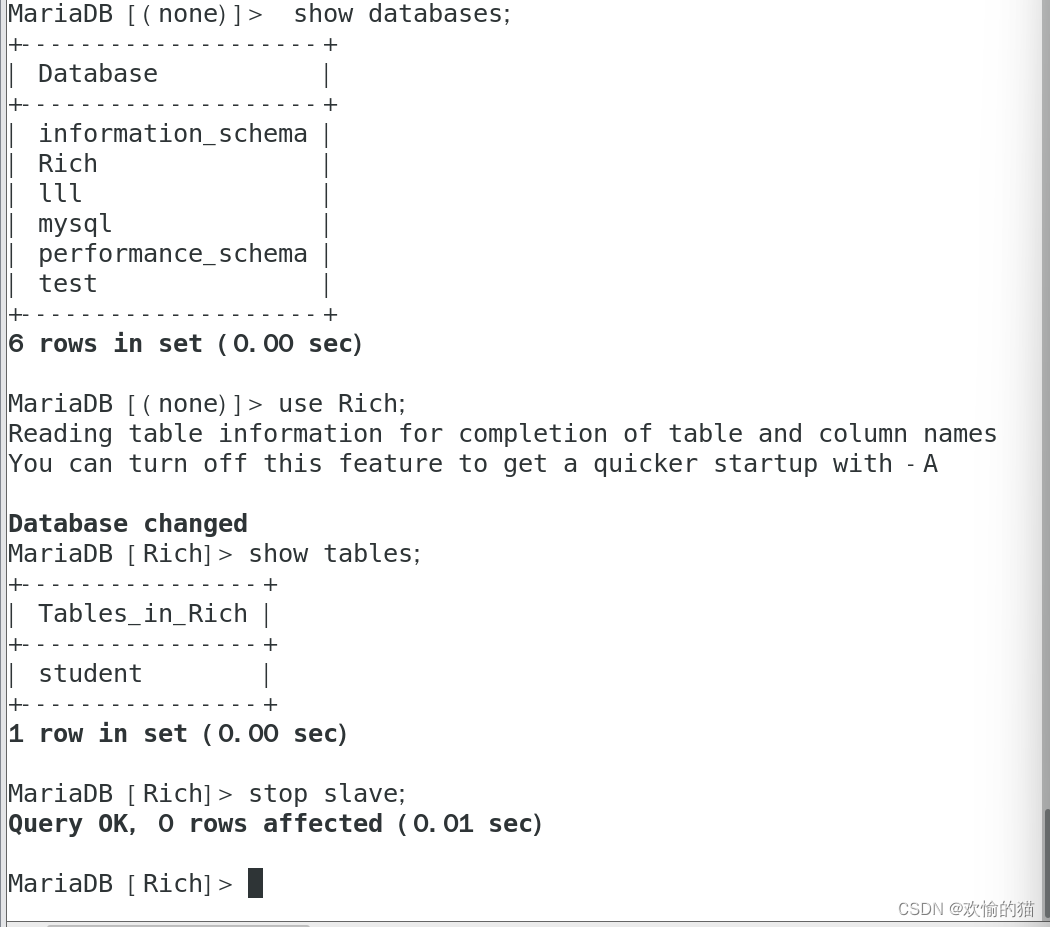
Slave2
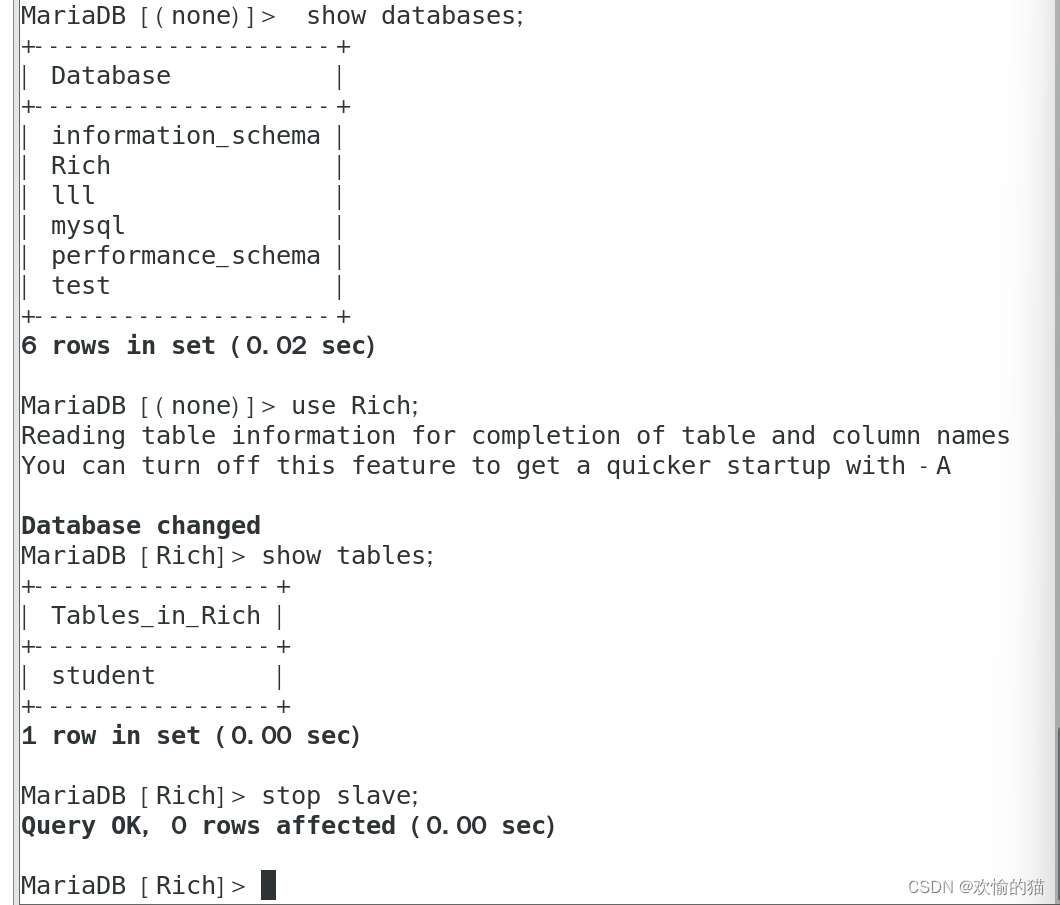
Master

Slave1

Slave2

操作测试:
在测试机上第1次查询结果

在测试机上第2次查询结果

在测试机上第3次查询结果

发现他是在slave1和slave2上轮流读取,这体现了负载均衡
测试写操作:
在Client上插入一条语句:
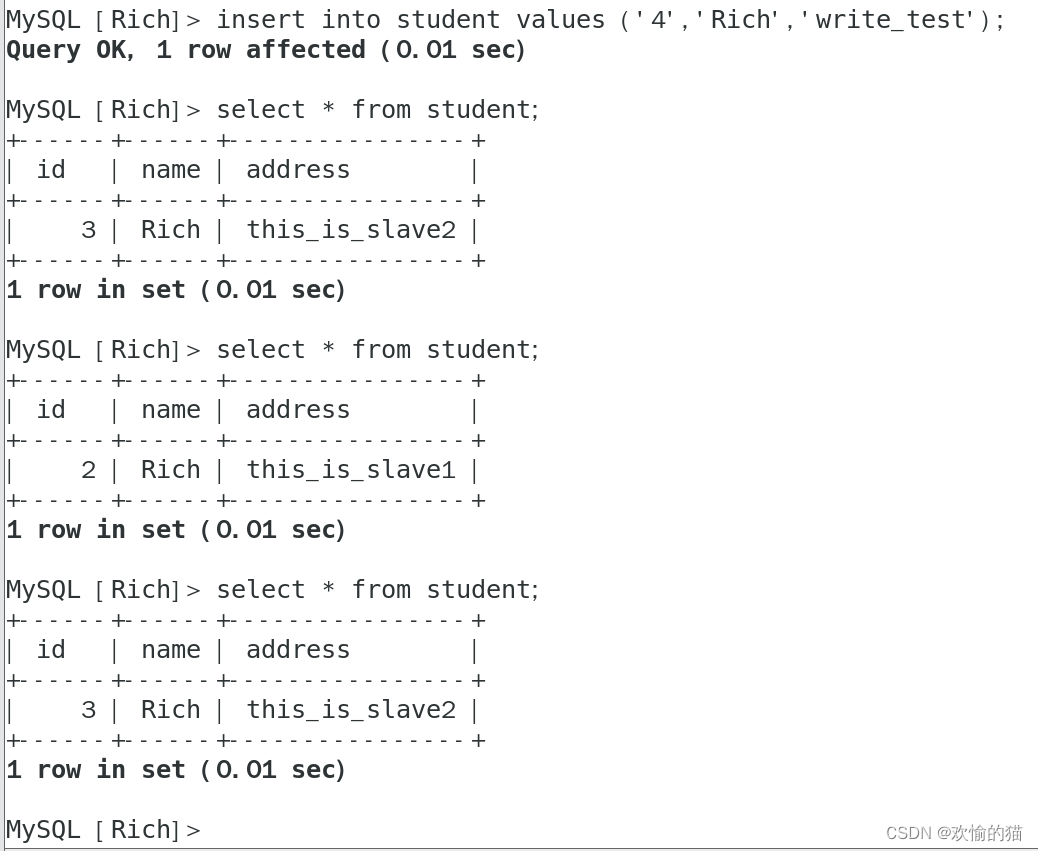
我们回到master上查看表student,发现客户机是写到了master上了。最终只有在Master上才能看到这条语句内容,说明写操作在master服务器上(体现了读写分离)
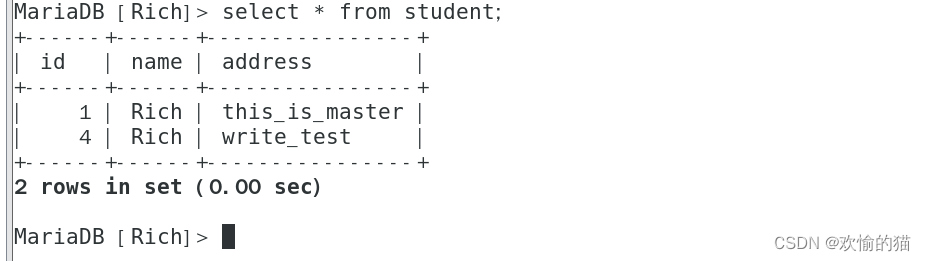
由此验证,已经实现了MySQL读写分离,目前所有的写操作都在Master主服务器上,用来避免数据的不同步,所有的读操作都平分给了Slave从服务器,用来分担数据库压力。
分别在两台从服务器上启用slave功能

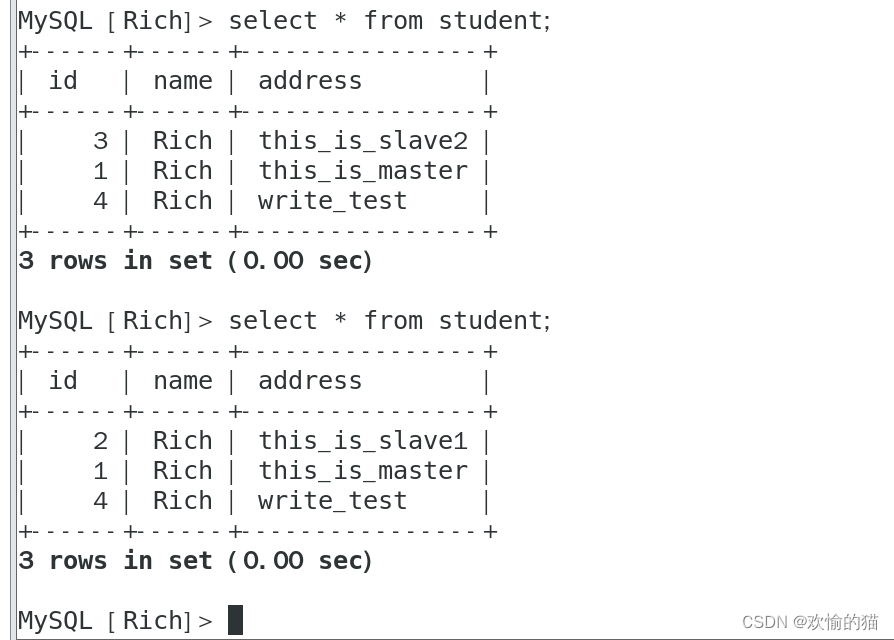
现在我们回到客户端查看表的内容,这次我们可以看到了master的全部内容但是slave1、slave2的内容还是轮流出现。又一次体现出了负载均衡。

















 4761
4761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









