







 本文介绍了通过添加伪列和虚拟列,以及SQL改写来优化MySQL查询性能的案例。在面对无法通过索引优化的函数运算时,利用MySQL 5.7的虚拟列功能,模拟Oracle的函数索引,成功减少了查询时间。此外,针对复杂的SQL查询,通过等价改写和拆分查询,显著提升了查询效率,降低了死锁概率。
本文介绍了通过添加伪列和虚拟列,以及SQL改写来优化MySQL查询性能的案例。在面对无法通过索引优化的函数运算时,利用MySQL 5.7的虚拟列功能,模拟Oracle的函数索引,成功减少了查询时间。此外,针对复杂的SQL查询,通过等价改写和拆分查询,显著提升了查询效率,降低了死锁概率。
关注“数据和云”,精彩不容错过
本文是技术同仁 蔡亮 在日常工作中通过试验,总结出的一些技巧方案,供大家参考学习。在此,感谢蔡亮的供稿分享,希望大家也可以后续将学习工作中遇到的问题,解决方法分享给大家。
一.通过伪列、虚拟列实现SQL优化
慢 SQL 文本如下: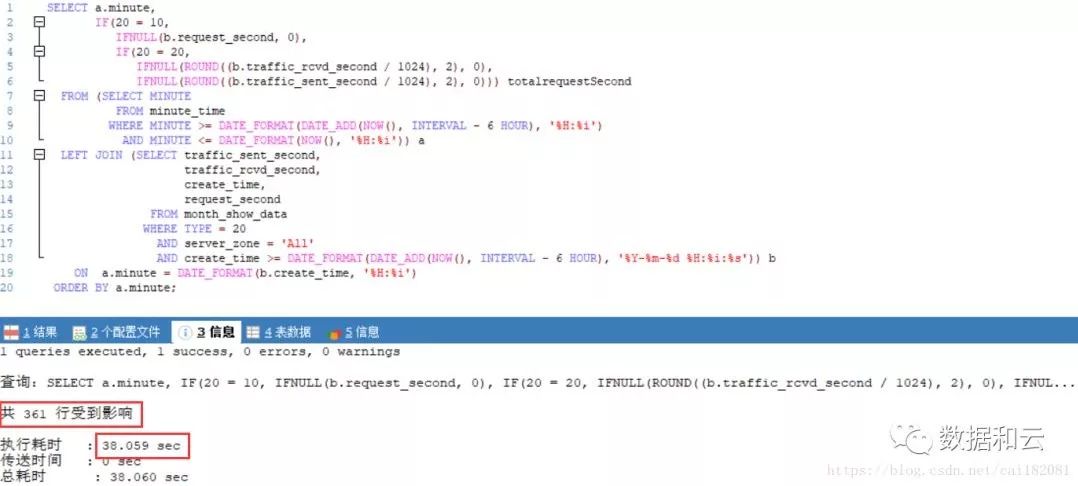
SQL 执行时长达 38S,获取 361 条数据结果返回。
SQL 执行计划如下: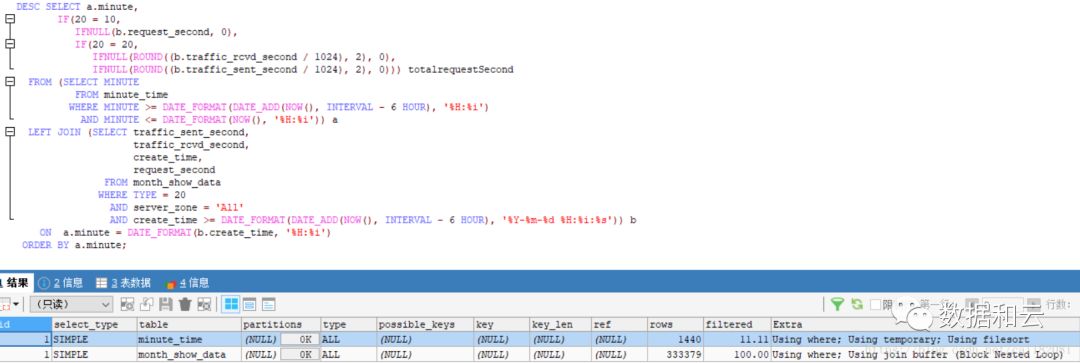
初步索引实现SQL优化
由执行计划可知,SQL 首先从 minute_time(minute_time 数据大概估算1440条)表中获取数据,然后嵌套驱动 month_show_data(month_show_data 数据大概估算333389条),两个表都是全表扫描!可以通过添加索引将 SQL 优化。
为两个表添加如下索引:
ALTER TABLE `minute_time` ADD INDEX `idx_minute`(`minute`);
ALTER TABLE `month_show_data` ADD INDEX `idx_sz_type_ct`(`server_zone`, `type`, `create_time`);
添加索引后,SQL 执行情况如下: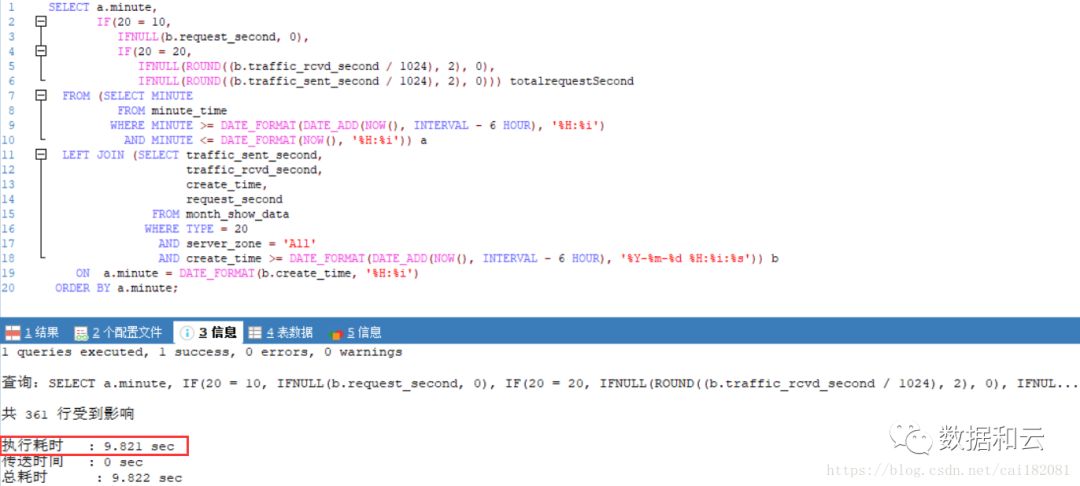
SQL 执行 10s 左右返回 361 条结果集。
添加索引后的执行计划如下: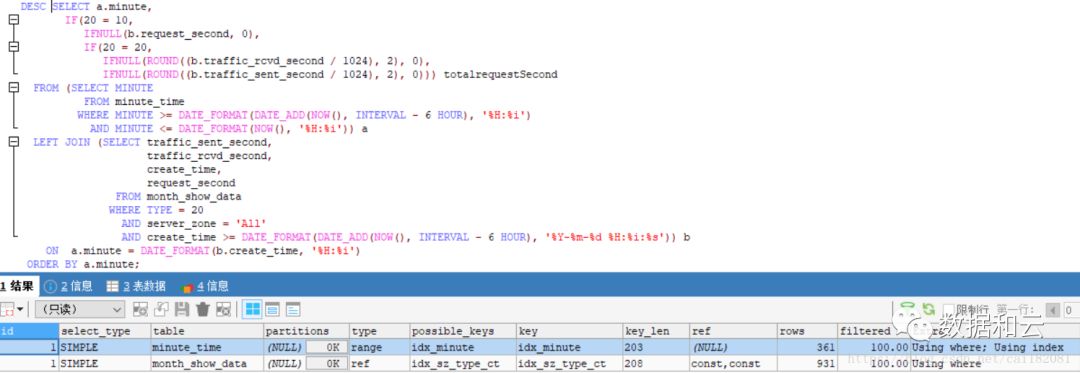
由执行计划可知,SQL 通过索引 idx_minute 先从 minute_time 中过滤出 361 条数据结果集,然后与通过索引 idx_sz_type_ct 从 month_show_data 中过滤出 931 条数据结果集相关联!
虽然 SQL 已经得到优化,但 SQL 长达 10s 的执行时间,对业务来说无法接受,随着数据量的增加,SQL 执行时间也会越来越慢。
虚拟列实现SQL优化
分析 SQL 可知,SQL 的性能瓶颈在于 a.minute = DATE_FORMAT(b.create_time, '%H:%i') 两表之间的关联关系,SQL 无法通过表之间的关联关系直接驱动 month_show_data 直接返回数据。并且 MySQL 不支持函数索引。无法通过创建函数索引来优化该 SQL。
这时候 SQL 如何在不改变业务的需求下继续深入优化呢?
MySQL 5.7 增加了虚拟列的新功能,可以类似的实现 Oracle 函数索引。由此思路,month_show_data 增加虚拟列 vr_time,并添加虚拟列索引 idx_vr_time。
ALTER TABLE `month_show_data` ADD vr_time VARCHAR(10) AS (DATE_FORMAT(create_time, '%H:%i')) STORED, ADD KEY idx_vr_time (vr_time);
并将 SQL 改写为: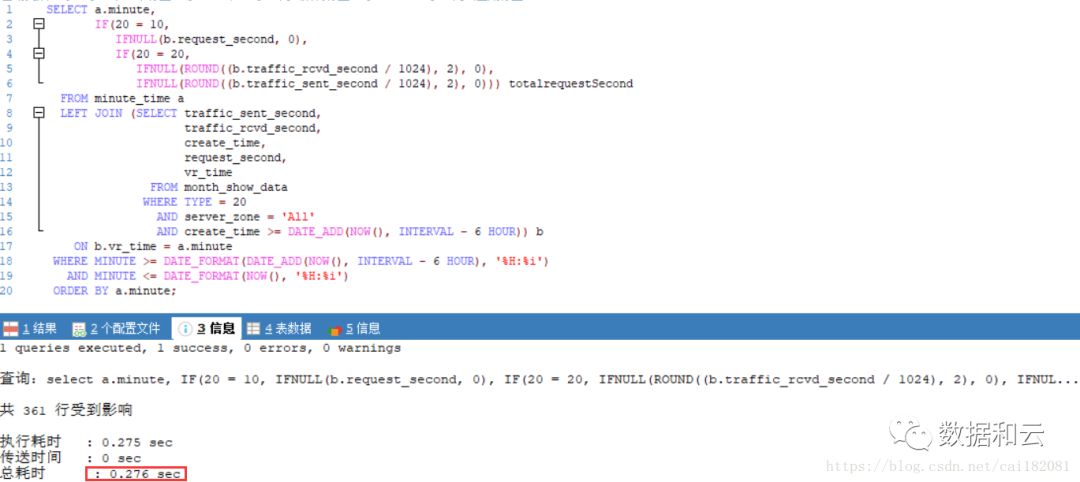
再次执行,0.27s 左右即可返回所需的数据。
执行计划如下: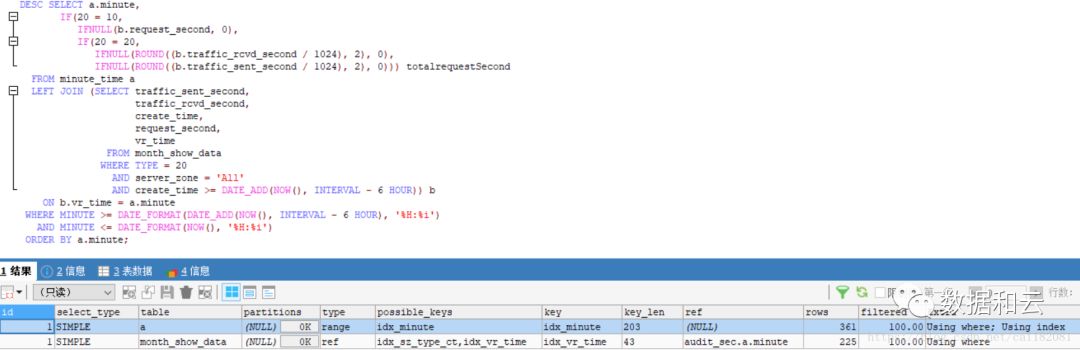
此 SQL 的优化是否就这样结束了呢?明显不是。
伪列实现SQL优化
由数据量、表之间的关联关系及返回的结果集推断可知,只有在 minute_time 和 month_show_data 分别过滤后,再对符合条件的结果集进行关联才是最优的执行计划,而由前面的分析可知,执行计划并没有按照我们想象中方式的实现关联。伪列的引入,可以强制 SQL 改变表之间的关联顺序,获得想要的执行计划。将 SQL 改写成如下方式: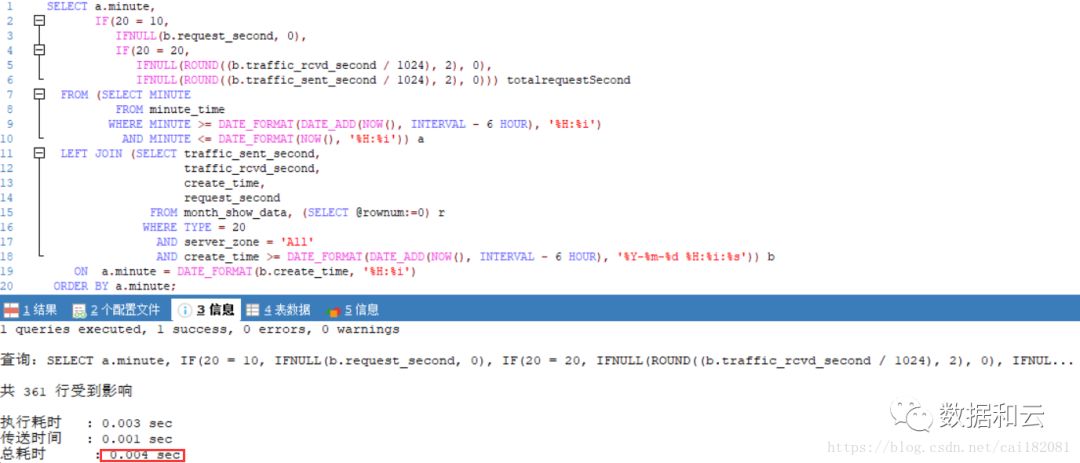
SQL 在 0.004s 之后即返回查询结果。
执行计划如下: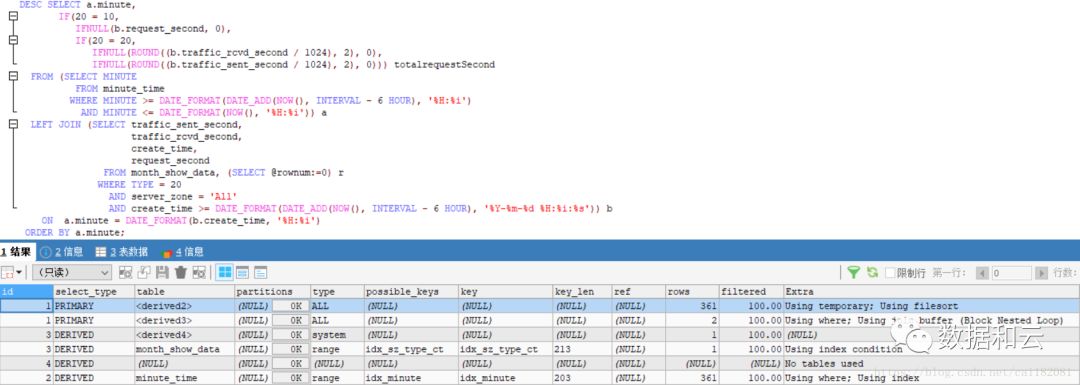
分析执行计划可知,SQL 先取得 DERIVED3 结果集(即 month_show_data 表符合条件的结果集),然后取得 DERIVED2 结果集(即 minute_time 表符合条件的结果集),最后以 DERIVED2 嵌套关联 DER
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2185
2185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









