







一般可以从以下几个方面进行优化
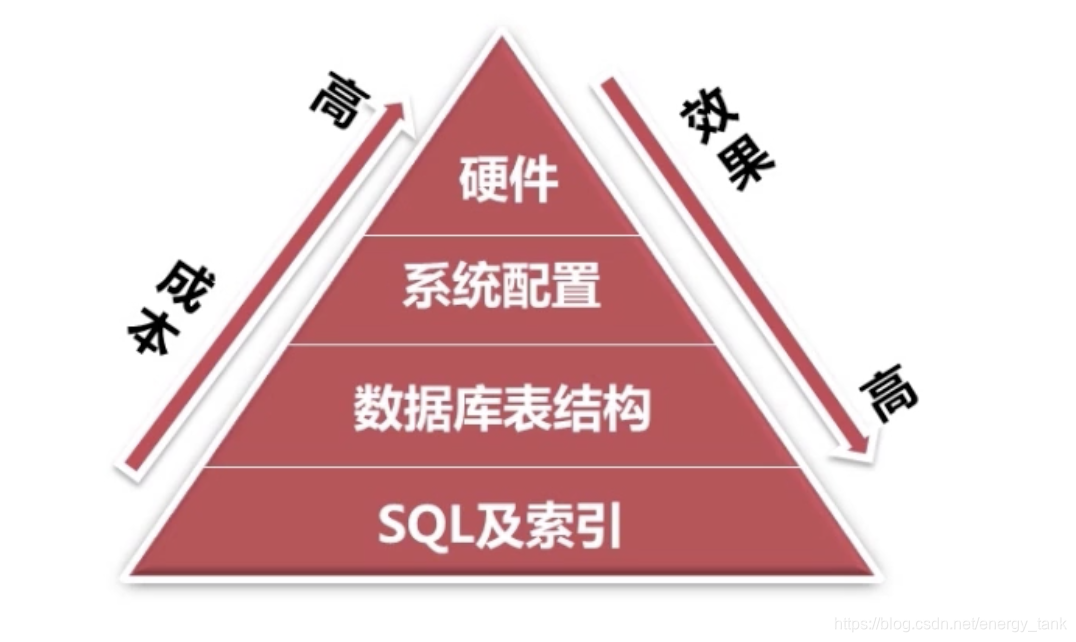
1)、sql及索引的优化是基石,是占比最大的一块,是日常开发中用到最多的优化点(要有一个结构良好的SQL,另外根据sql在表中建立些有效的索引[索引太多对我们写入操作也是
有一定的影响的,要适量要有效])。
2)、sql的优化是建立在数据库表结构建立合理性基础上优化的(一般根据数据范式设计一个简单明了的表结构,尽量减少冗余)。
3)、系统配置方面优化:一般本身系统也有一些限制,比如系统有些TCP,IP的限制,打开文件数的限制以及一些安全性的限制等,MySQL是基于文件,每查询一张表都要打开一
个文件,如果文件达到一定的限制,就会出现频繁出现IO的操作,所以一般也会对系统一些配置进行优化。
4)、硬件方面:选择适合数据的cpu,更快的IO以及更多的内存。(内存越大对数据库性能约好,CPU不一样,不是CPU越好就能达到所要的效果,一般mysql对CPU核数的数量有
一定限制,并不会用到太多的核数,比如有些查询只用单核)。
一、sql及索引的优化
分析:哪些查询是需要优化的,哪些查询是有效率问题的,在这个问题上mysql给出了日志的记录,也就是慢查询日志。
1、如何发现有问题的sql?使用mysql慢查询日志对sql进行监控:
-
show variables like 'slow_query_log';
-
set global show_query_long_file = ‘/var/log/mysql/mysql-slow.log’; (日志记录位置)
-
set global long_queries_not_using_indexes=on; (没有使用索引的sql记录到慢查询日志中)
-
set global long_query_time=1 (超过多少秒查询记录到慢查询日志中)
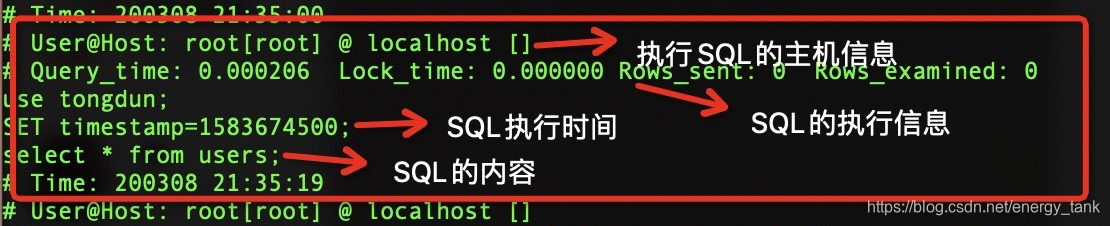
2、慢查询日志所包含的内容和结构:
3、常用的慢查询日志分析工具(在生产环境中每天会产生大量的日志,直接打开日志文件去分析,显然是不可能的,这时候需要用到分析工具):
-
mysqldumpslow ----MySql官方的分析工具(mysqldumpslow -h、mysqldumpslow -t 3 /var/log/mysql/mysql-slow.log | more)
-
pt-query-digest
输出到文件
pt-query-digest slow-log > slow_log.report
输出到数据库表
pt-query-digest slow-log -review \
h=127.0.0.1,D=test,p=root,p=3306,u=root,t=review \
--create-reviewtable \
--review-history t=hostname_slow
查询日志所包含的内容结构解析(pt-query-digest /var/log/mysql/mysql-slow.log | more):
主要分为三部分:
第一部分头部信息
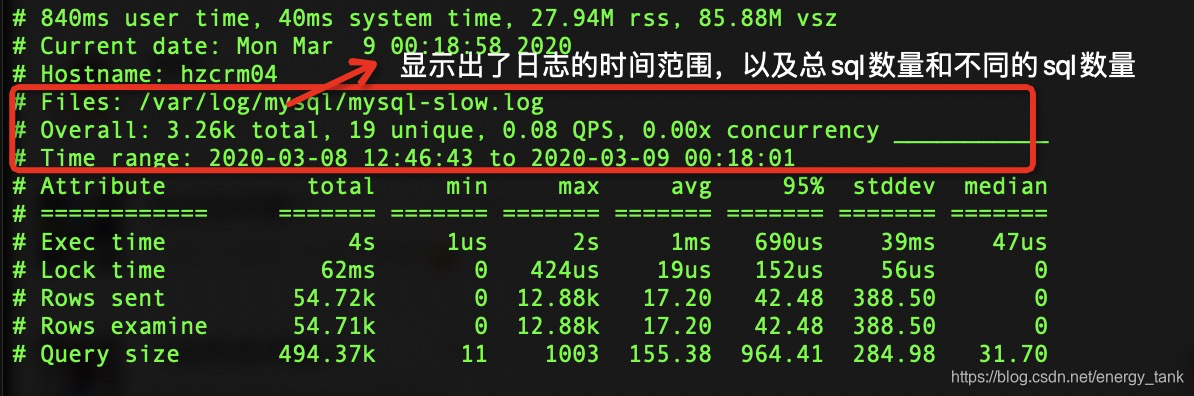
第二部分表和执行语句的统计

第三部分具体的sql
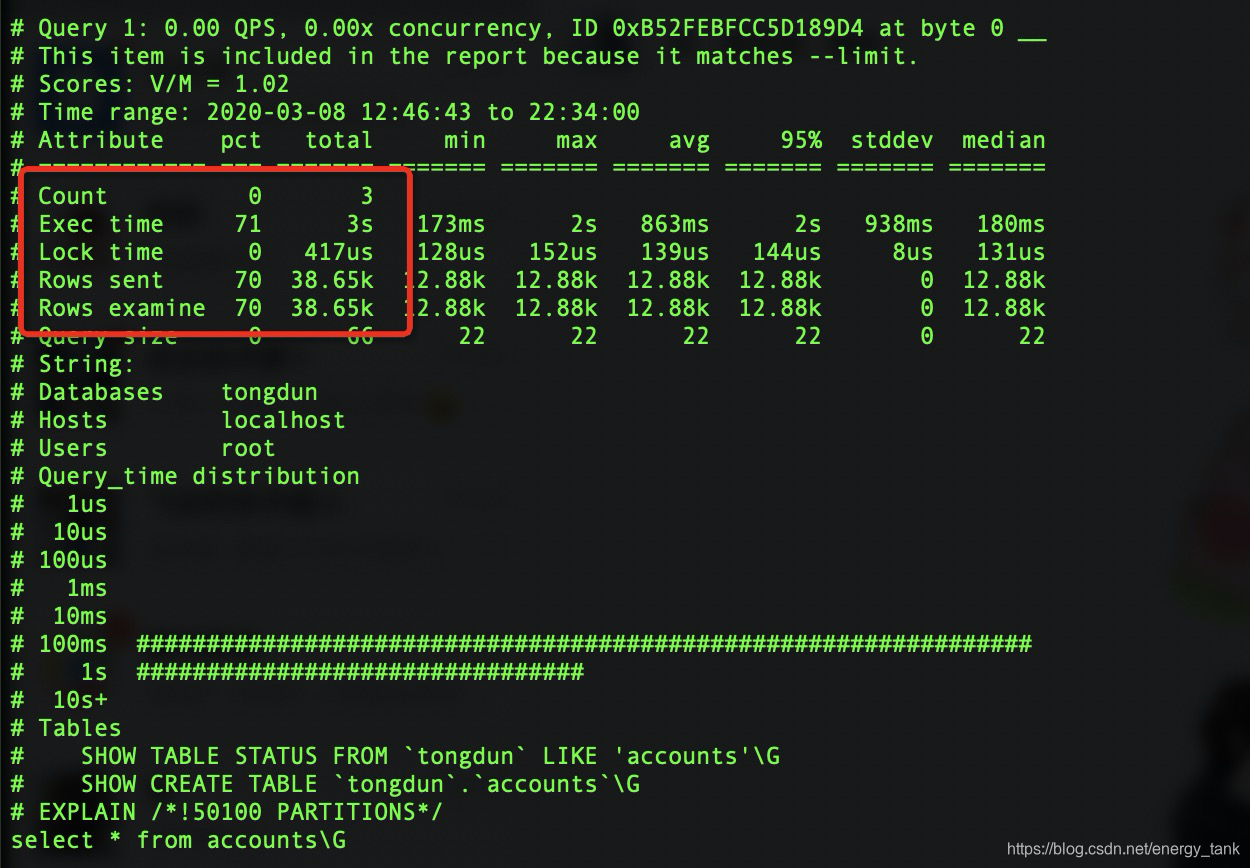
总结:通过pt-query-digest慢查询日志分析工具可以大大减小mysql慢查询日志操作分析时间,同时增加我们的工作效率,具体详细使用请查找相关官方文档。
4、如何通过慢查询日志发现有问题的Sql?
-
查询次数多且每次查询占用时间长的Sql
通常为pt-query-digest分析的前几个查询 -
IO大的sql(主要瓶颈)
通常为pt-query-digest分析中的Rows examine项(扫描行数越多IO消耗的越大) - 未命中索引的sql
pt-query-digest分析中Rows examine和Rows send的对比(扫描行数远远大于发送的行数,说明sql索引的命中率并不高)
5、如何分析Sql查询(使用explain查询SQL的执行计划)

explain返回各列的含义:
table:显示这一行的数据是关于那张表的。
type:重要的列,显示连接使用了何种类型,从最好到最差的连接类型为const(陈述查找一般对主键;唯一索引查找)、eq_reg(范围查找,一般主键唯一索引查找)、
ref(连接查找)、range(索引范围查找)、index(索引的扫描)和ALL(表扫描)。
possible_keys:显示可能应用在这张表中的索引,如果为空,没有可能的索引。
key:实际使用的索引,如果为null则没有使用索引
key_len:使用的索引的长度,在不损失精确性的情况下,长度越短越好。
ref:显示索引的哪一列被使用了,如果可能的话是一个常数。
rows:mysql认为必须检查的用来返回请求数据的行数。
Extra列需要注意的返回值:
Using filesort:看到这个的时候,查询就要优化了,mysql需要进行额外的步骤来发现如何对返回的行排序,它根据连接类型以及存储排序键值和匹配条件的全部行的行指针来排序全部行。
Using temporary:看到这个的时候,查询需要优化了,这里mysql需要创立一个临时表来存储结果,这通常发生在对不同的列集进行order by上而不是group by上。
6、实例:
Max和Count类的sql优化:
查询最后新增的客户的新增时间
select max(date_entered) from accounts;

在做业务报表中有时候会使用到这些函数,上图是列举的实例操作,从查询分析中可以看出该查询需要全表扫描,如果数据量大的情况下就会大量消耗IO操作,
降低服务器效率,从而导致性能下降,如果对date_entered字段加了索引,就不会全表扫描,因为索引是按顺序排列查找的,通过查询分析就能找到最后一个数值什么。
Limit查询优化:
Limit常用于分页处理,时常会伴随着order by从句使用,因此大多时候会使用Filesorts,这样会造成大量的IO问题
实例:
SELECT * from accounts order by date_modified LIMIT 50,5;
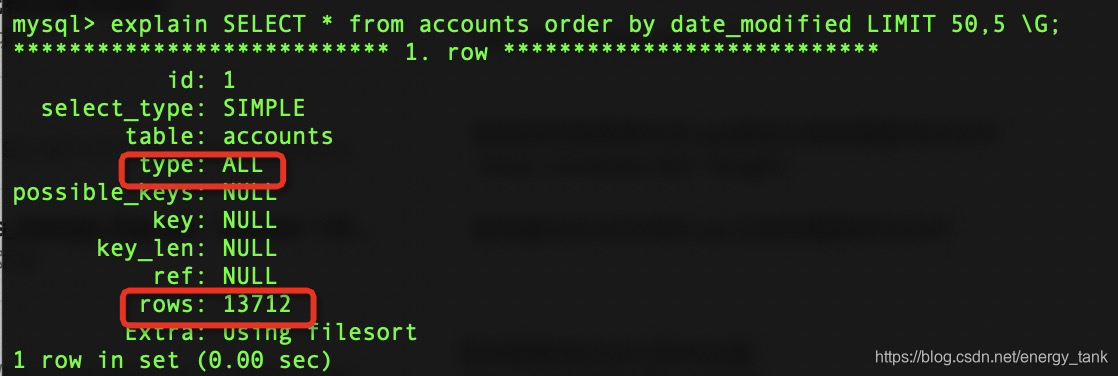
以上问题:使用文件扫描的操作,共扫描了13712行,会消耗大量的IO操作
优化步骤1:使用有索引的列或主键进行order by 操作(这个举例主键的方式)
SELECT * from accounts order by id LIMIT 50,5;
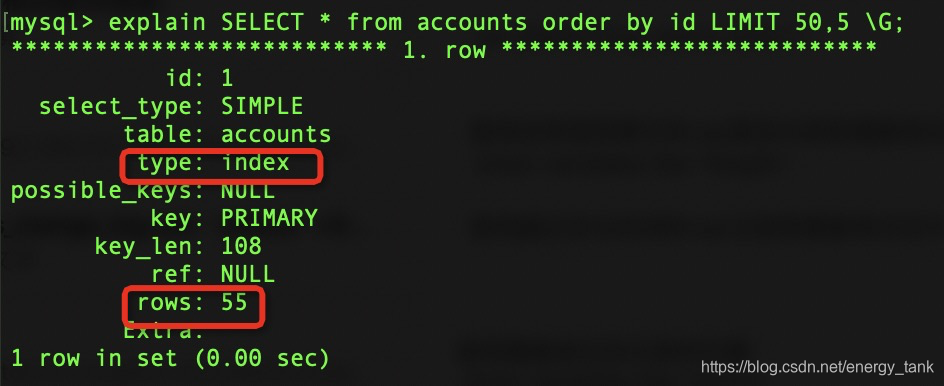
优化后:以上明显看出并没有有使用文件排序的方式查找,是根据主键索引进行排序的,扫描行数只有55行,但是还是有点问题,如果分页的话limit 50越往后翻页数值越大,这样也会大量去扫描行数,导致
分页越往后请求速度就越慢。
优化步骤2:
记录上次返回的主键,在下次查询时使用主键过滤
SELECT * from accounts where id>55 and id<=60 order by id LIMIT 1,5;
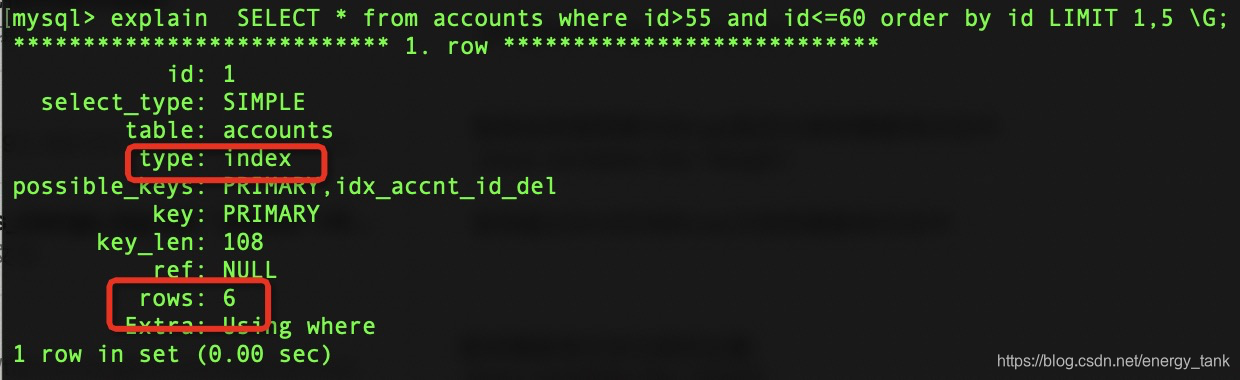
优化后:这时候limit 后面不管增加到多大始终只会扫描5行
7、如何选择合适的列建立索引
1、通常在where从句、order by从句、group by从句、on从句中出现的列。
还有可能在select从句中建立索引,当一个索引包含了查询中所有的列那么就称这个索引为覆盖索引,当我们查询的频率非常高并查询中所包含的列比较少,一般就会通过覆盖索引的方式对sql进行优化。
2、索引字段越小越好
因为在数据库中数据存储是页为单位,如果我们在一页中存储的数据越多,那么一次IO操作所获取的数据量也就越大,这样就要求了IO效率要更高些。
3、离散度大的列放到联合索引的前面
SELECT * from accounts where assigned_user_id='c4d662c9-bb91-c543-1d9d-586b466eb09b' and deleted=0;
是index(deleted,assigned_user_id)好?还是index(assigned_user_id,deleted)好? 那样那个字段的离散度更大,怎样判断那个字段离散度更大呢,如下:

很明显assigned_user_id离散度更大,所以使用index(assigned_user_id,deleted)
8、索引的维护以及优化-----重复以及冗余索引
重复索引是指相同的列以相同的顺序建立的同类型的索引,如下表中primary key和ID列上的索引就是重复索引

增加索引会有利于查询但会影响inster和update等写入的语句,有时候过多的索引不但影响我们的写入的效率同时也会影响查询,由于数据库在
选择查询分析的时候选择那个索引来进行查询,如果索引过多,分析的速度就越慢这样同样会减小查询的效率,所以不是索引越多越好,所以要分析去维护表中的索引。
如何查找重复以及冗余索引:
pt-duplicate-key-checker \ -uroot \ p '' \ -h 127.0.0.1


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









