







 本文深入解析I/O概念及磁盘I/O、网络I/O的工作原理,详细阐述socket通信流程,包括socket创建、bind、listen、accept、connect、read与write等关键步骤及其阻塞特性。
本文深入解析I/O概念及磁盘I/O、网络I/O的工作原理,详细阐述socket通信流程,包括socket创建、bind、listen、accept、connect、read与write等关键步骤及其阻塞特性。
什么是I/O,I/O阻塞的原因?
到底啥是I/O
input /output,输入/输出,就是I/O
输入输出的到底是什么?
常见I/O又两种,一种是磁盘I/O,一种是网络I/O
磁盘I/O是指硬盘和内存之间的输入输出
例如我们读取本地文件的时候,将磁盘中的数据拷贝到内存中来,修改本地文件的时候,需要把修改了的数据在拷贝到磁盘中去,这就是磁盘I/O
网络I/O是指网卡和内存之间的输入输出
当网络上的数据到来时,网卡需要将数据拷贝到内存中。当要发送数据给网络上的其他人时,需要将数据从内存拷贝到网卡里。
看到这里有个问题,那为什么都要跟内存交互呢?
因为指令都是由CPU执行的,CPU与内存的交互速度要远远高于与外部设备的交互,如果没有内存,那么CPU直接和外部设备交互,也是I/O操作
总结:I/O 就是指内存与外部设备之间的交互(数据拷贝)。
好了,明确什么是 I/O 之后,让我们来揭一揭 socket 通信内幕
socket
socket那么要了解我们的网络模型
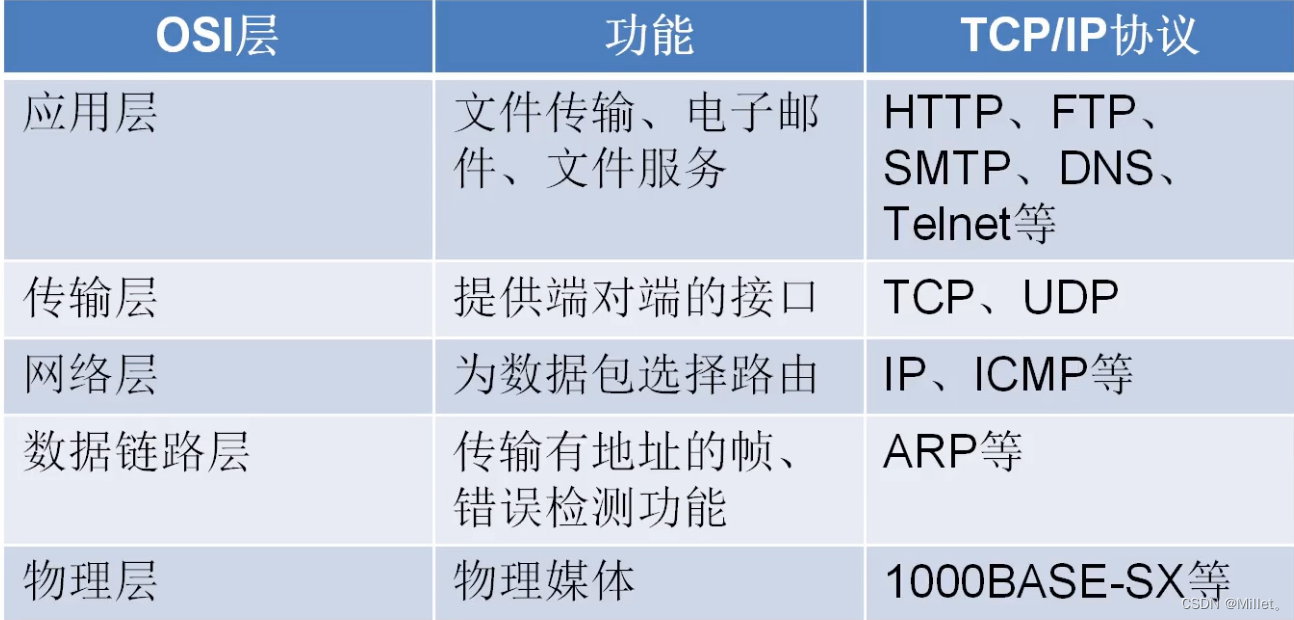
我们了解的多一些的都是应用层协议,例如HTTP、FTP、SMTP、DNS、Telnet等,实际上数据传输过程中,传输层都是TCP和UDP协议,提供端对端的接口,到网络层为数据包选择路由,如何发包,发到哪个设备,到数据链路层检错到物理层,实际是个拆包组包的过程,但是实际上顶层的应用层协议都是基于传输层协议实现的,那么有的一些需求应用层协议不足以满足,例如聊天工具,多人语音视频电话,这时候就需要直接和底层协议打交道,如何与TCP和UDP协议直接打交道呢,操作系统为我们提供了sockect,我们把socket理解成api,让我们能直接和传输层打交道
创建一个socket
首先我们要创建一个socket,以python为例
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
domain :这个参数用于选择通信的协议族,比如选择 IPv4 通信,还是 IPv6 通信等等;
type :选择套接字类型,可选字节流套接字、数据报套接字等等;
直接输入1次#,并按下space后,将生成1级标题。
输入2次#,并按下space后,将生成2级标题。
以此类推,我们支持6级标题。有助于使用TOC语法后生成一个完美的目录。
bind
现在我们已经创建了一个 socket,但现在还没有地址指向这个 socket。
众所周知,服务器应用需要指明 IP 和端口,这样客户端才好找上门来要服务。所以,此时我们需要指定一个地址和端口来与这个 socket 绑定一下。
server.bind(('0.0.0.0', 8000))
让客户端的请求都发送到我们服务端机器的8000端口上
listen
执行了 socket、bind 之后,此时的 socket 还处于 closed 的状态,也就是不对外监听的。然后,我们需要调用 listen 方法,让 socket 进入被动监听状态,这样的 socket 才能够监听到客户端的连接请求。
server.listen(backlog)
这个 backlog 我查阅资料的时候,看到了三种解释:
socket 有一个队列,同时存放已完成的连接和半连接。backlog 为这个队列的大小;
socket 有两个队列,分别为已完成的连接队列和半连接队列。backlog 为这个两个队列的大小之和;
socket 有两个队列,分别为已完成的连接队列和半连接队列。backlog 仅为已完成的连接队列大小。
解释下什么叫半连接
我们都知道 TCP 建立连接需要三次握手,当接收方收到请求方的建连请求后会返回 ack。此时,这个连接在接收方就处于半连接状态,当接收方再收到请求方的 ack 时,这个连接就处于已完成状态:
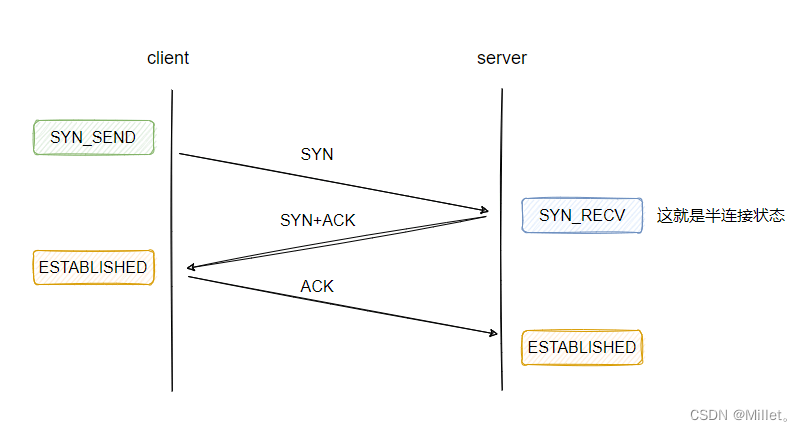
所以,上面讨论的就是这两种状态的连接的存放问题。
我查阅资料看到,基于 BSD 派生的系统的实现是使用的一个队列来同时存放这两种状态的连接, backlog 参数即为这个队列的大小。
而 Linux 则使用两个队列分别存储已完成连接和半连接,且 backlog 仅为已完成连接的队列大小
accept
现在,我们已经初始化好监听套接字了。此时会有客户端连上来,然后我们需要处理这些已经完成建连的连接。
从上面的分析我们可以得知,三次握手完成后的连接会被加入到已完成连接队列中去。
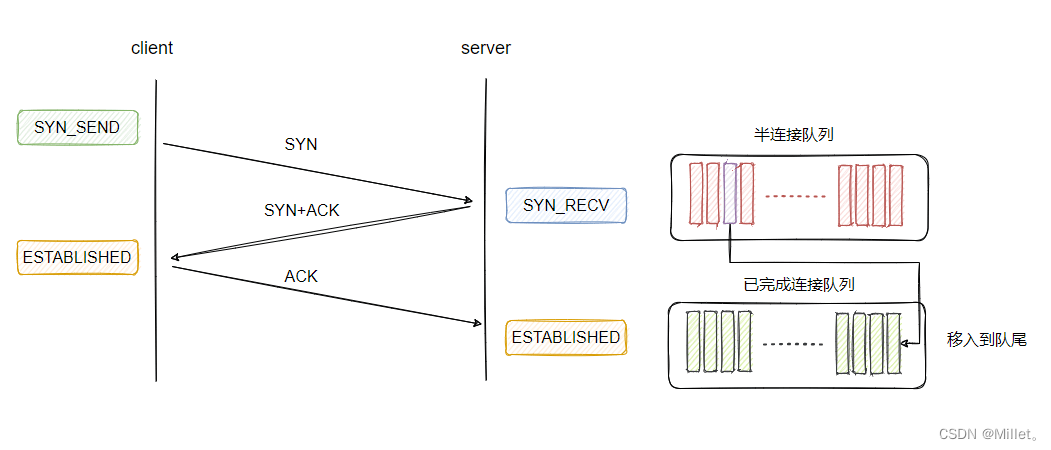
这时候,我们就需要从已完成连接队列中拿到连接进行处理,这个拿取动作就由 accpet 来完成。
sock, addr = server.accept()
def accept(self):
"""accept() -> (socket object, address info)
Wait for an incoming connection. Return a new socket
representing the connection, and the address of the client.
For IP sockets, the address info is a pair (hostaddr, port).
"""
fd, addr = self._accept()
sock = socket(self.family, self.type, self.proto, fileno=fd)
# Issue #7995: if no default timeout is set and the listening
# socket had a (non-zero) timeout, force the new socket in blocking
# mode to override platform-specific socket flags inheritance.
if getdefaulttimeout() is None and self.gettimeout():
sock.setblocking(True)
return sock, addr
这个方法返回的 int 值就是拿到的已完成连接的 socket 的文件描述符,之后操作这个 socket 就可以进行通信了。
如果已完成连接队列没有连接可以取,那么调用 accept 的线程会阻塞等待。
至此服务端的通信流程暂告一段落,我们再看看客户端的操作。
connect
客户端也需要创建一个 socket,也就是调用 socket(),这里就不赘述了,我们直接开始建连操作。
客户端需要与服务端建立连接,在 TCP 协议下开始经典的三次握手操作,再看一下上面画的图:
客户端创建完 socket 并调用 connect 之后,连接就处于 SYN_SEND 状态。当收到服务端的 SYN+ACK 之后,连接就变为 ESTABLISHED 状态,此时就代表三次握手完毕
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect(('127.0.0.1', 8000))
调用 connect 需要指定远程的地址和端口进行建连,三次握手完毕之后就可以开始通信了。
客户端这边不需要调用 bind 操作,默认会选择源 IP 和随机端口。
可以看到这里的两个阻塞点:
connect :需要阻塞等待三次握手的完成;
accept :需要等待可用的已完成的连接,如果已完成连接队列为空,则被阻塞。
read、write
连接建立成功之后,就能开始发送和接收消息了。我们来看一下:
read 为读数据,从服务端来看就是等待客户端的请求。如果客户端不发请求,那么调用 read 会处于阻塞等待状态,没有数据可以读,这个应该很好理解。
write 为写数据。一般而言服务端接受客户端的请求之后,会进行一些逻辑处理,然后再把结果返回给客户端,这个写入也可能会被阻塞。
这里可能有人就会问 read 读不到数据阻塞等待可以理解,write 为什么还要阻塞,有数据不就直接发了吗?
因为我们用的是 TCP 协议,TCP 协议需要保证数据可靠地、有序地传输,并且给予端与端之间的流量控制。
所以说发送不是直接发出去,它有个发送缓冲区,我们需要把数据先拷贝到 TCP 的发送缓冲区,由 TCP 自行控制发送的时间和逻辑,有可能还有重传什么的。
如果我们发的过快,导致接收方处理不过来,那么接收方就会通过 TCP 协议告知:别发了!忙不过来了。发送缓存区是有大小限制的,由于无法发送,还不断调用 write 那么缓存区就满了,满了就不允许你 write 了,所以 write 也会发生阻塞。
综上,read 和 write 都会发生阻塞。
为什么网络 I/O 会被阻塞?
因为和通信涉及到的 accept、connect、read、write 这几个方法都可能会发生阻塞。
阻塞会占用当前执行的线程,使之不能进行其他操作,并且频繁阻塞唤醒切换上下文也会导致性能的下降。
由于阻塞的缘故,起初的解决的方案就是建立多个线程。但是随着互联网的发展,用户激增连接数也随着激增,需要建立的线程数也随着一起增加,到后来就产生了 C10K 问题。
服务端顶不住了呀,咋办?
优化呗!
所以后来就弄了个非阻塞套接字,然后 I/O 多路复用、信号驱动 I/O、异步 I/O。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









