




下边看起来就高端一点
数据处理,慢条斯理
grep命令:筛选数据
grep 是Globally search a Regular Experssion and Print
意思是全局搜索一个正则表达式,并且打印
换个意思就是在文件中查找关键字并查找关键字所在行
grep的简单用法
grep命令的最基本用法
grep text file
text 代表要搜索的文本,file 代表共搜索的文件
例如
grep path /etc/profile
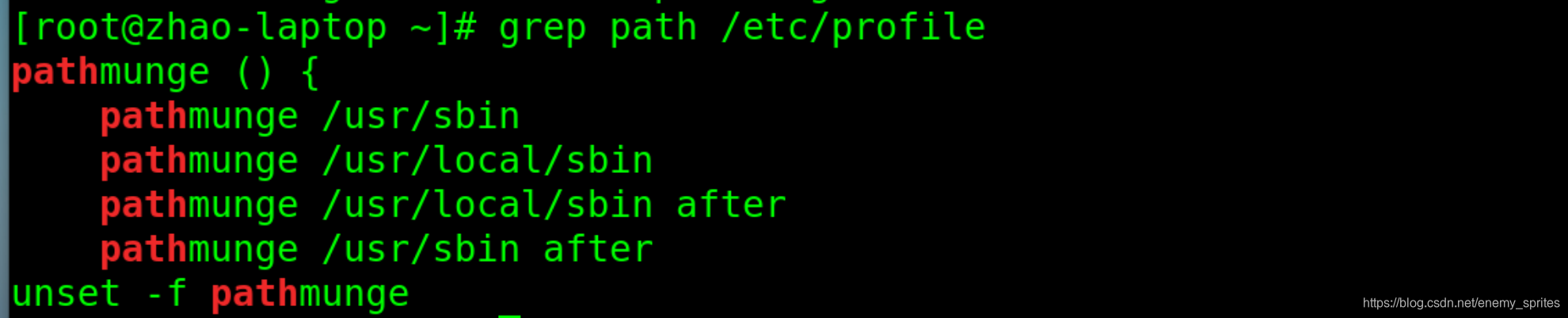 列出了在etc下的profile文件中所有包含path的行,并且用颜色标记出来
列出了在etc下的profile文件中所有包含path的行,并且用颜色标记出来
grep更像一个过滤器,筛选出你要找的对象,
如果查找的文本是带有空格的文本,那就要用引号括起来
grep 'hello world' file
-i 参数:忽略大小写
默认情况下,grep命令是区分大小写的
也就是说搜索的文本严格的按着大小写来搜索
比如我搜索的文本是text
就不会搜出 Text ,teXt等文本
我们可以给grep加上-i参数,让他变得忽略大小写
grep -i path /etc/profile
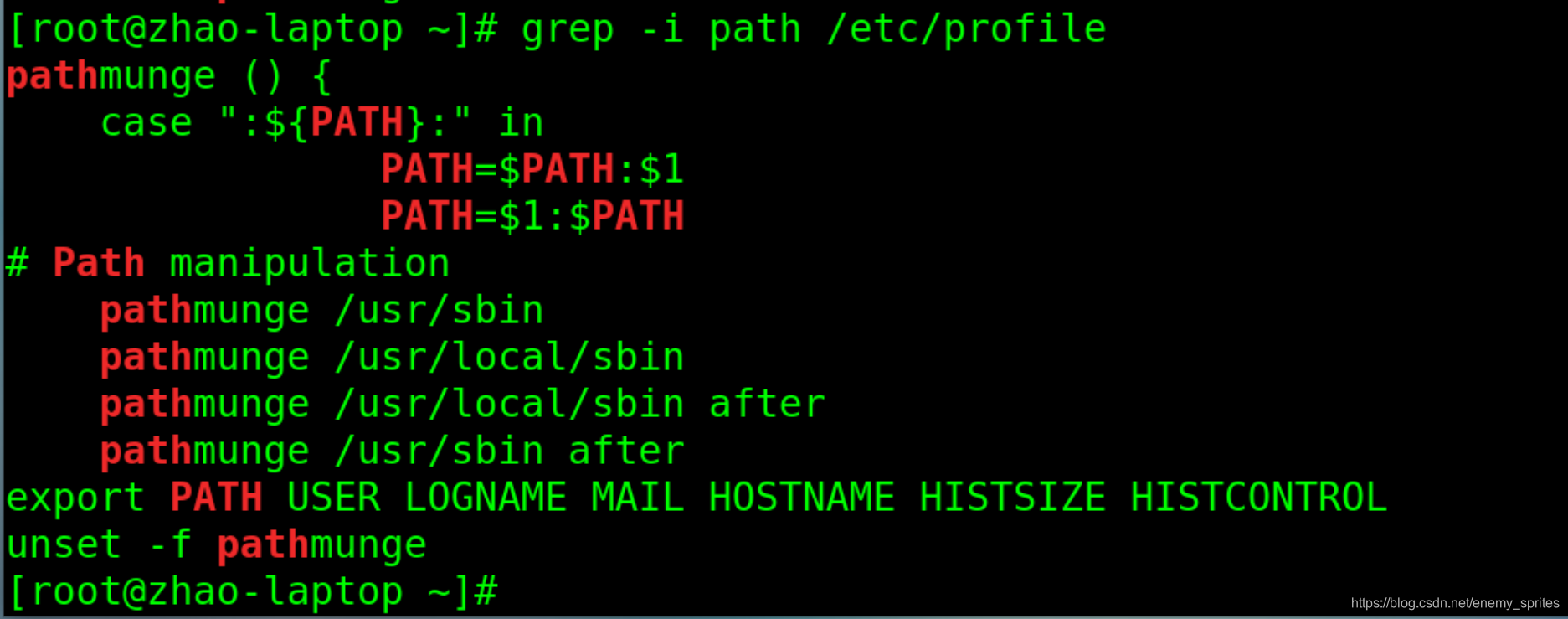 可以发现 搜索的结果增多了 ,因为忽略的大小写,PATH也会搜索出来
可以发现 搜索的结果增多了 ,因为忽略的大小写,PATH也会搜索出来
-n参数:显示行号
-n参数就是显示搜索文本所在的行号
grep -n path /etc/profile
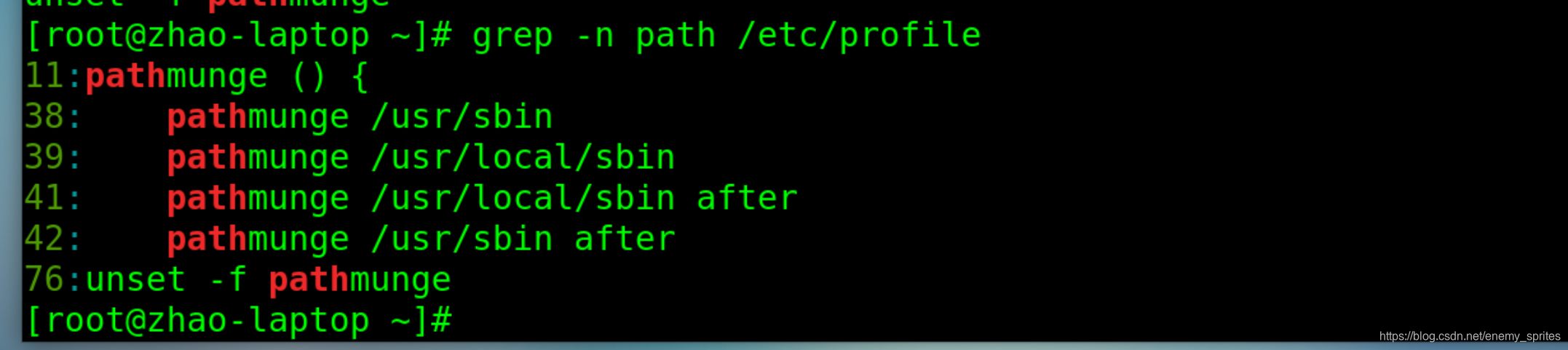
-v参数:只显示文本不在的行
v是invert的缩写,表示 颠倒,倒置
grep -v path /etc/profile
-r参数:在所有子目录和文件中查找
r是英语 recursive的缩写 表示 递归
如果是-r参数,那最后的一个参数file就要换成目录了,在所有子文件和目录中查找文本
grep -r "Hello World" folder/
意思是在folder目录的所有子目录和子文件中查找Hello World这个文本
rgrep 相当于grep -r
grep的高级用法:配合正则表达式
正则表达式使用单个字符串
来描述、匹配一系列符合某个句法规则的字符串

-E参数:使用正则表达式
E是extended regular expression的第一个字母
表示扩展的正则表达式
grep -E Path /etc/profile
 这也没什么不同的嘛
这也没什么不同的嘛
下来接着看
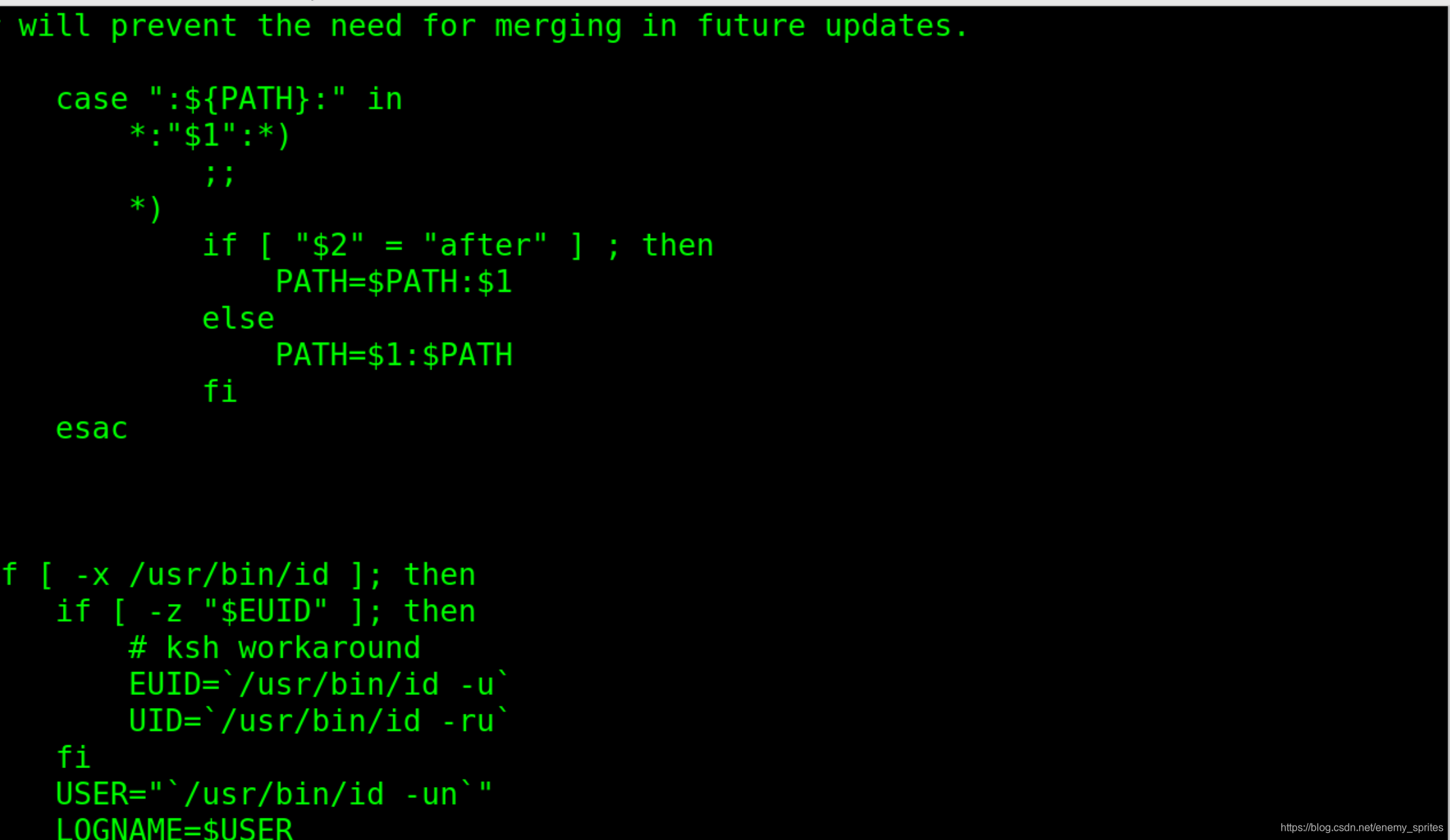
grep -E ^path /etc/profile
 这里用到了^号,表示匹配行首(匹配输入字符串的开始位置)
这里用到了^号,表示匹配行首(匹配输入字符串的开始位置)
^后边出现的字符需要出现在一行的开始
所以出现了上图中包含path并以path开始的这一行
在举一人例子:
grep -E [Pp]ath /etc/porfile
 这里用到了 [ ]:其作用是将[ ]的字符任取其一,
这里用到了 [ ]:其作用是将[ ]的字符任取其一,
[Pp]ath的意思,就是既可以为path,也可以为Path
在比如
由于搜索包含0-4的任意数字的行
grep -E [0-4] /etc/profile
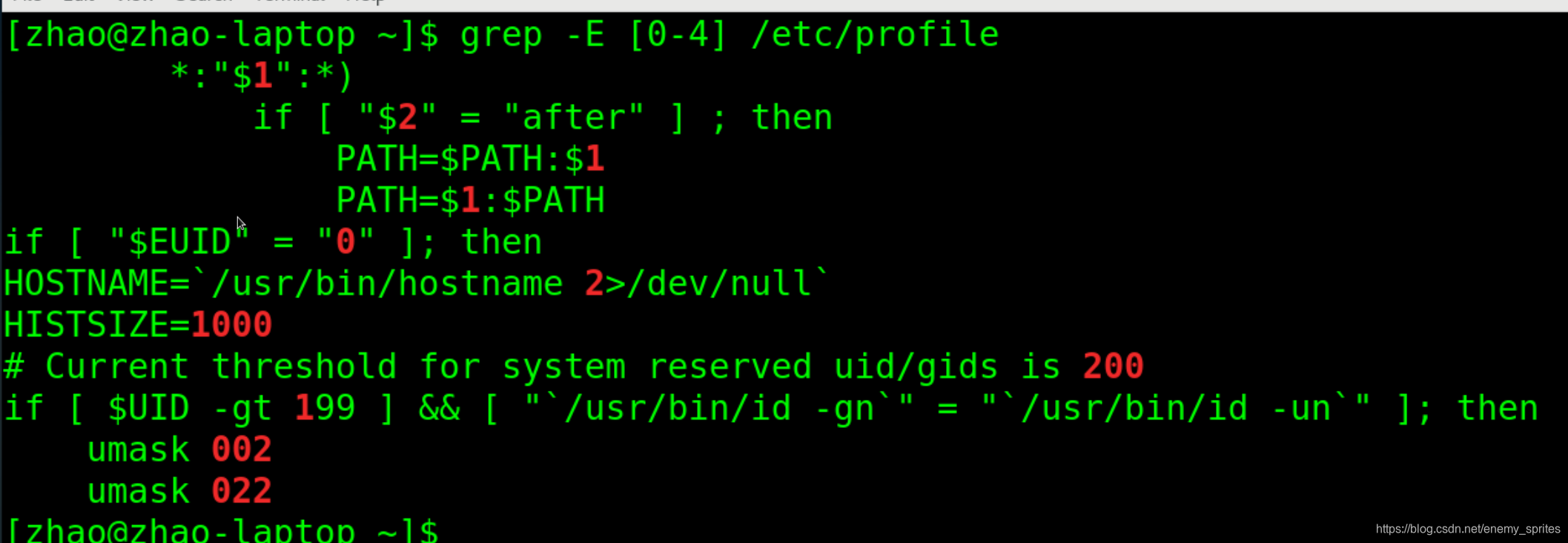
其实在CentOS和Ubuntu这样的Linux发行版中,
不加-E参数也是可以的,正则表达式始终激活的
有的Unix发行版系统可能不加-E参数就不能搜索正则表达式
sort命令:为文件排序
sort命令对文件的行进行排序
Sorting(排序)算法
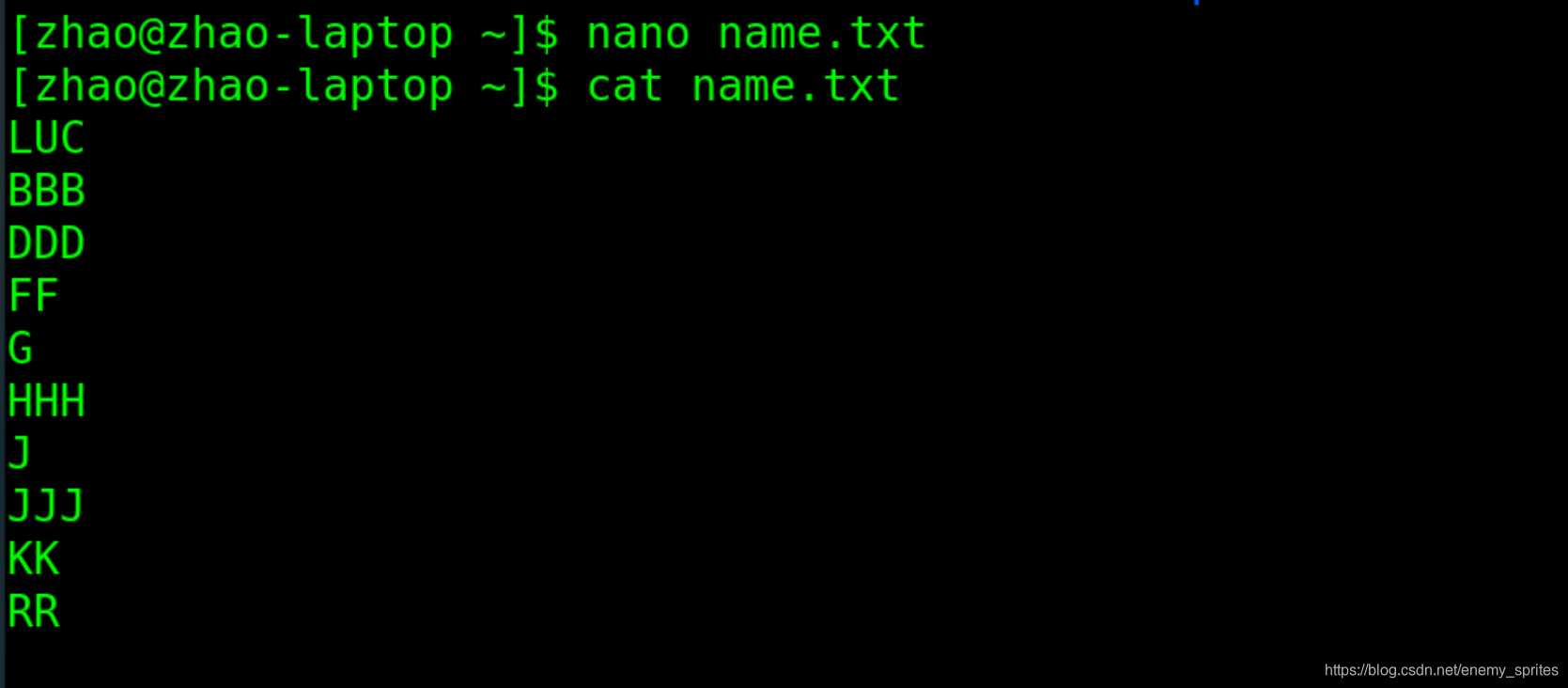
 首先我见一个文件,写一些内容用于排序,开始是这样的内容显示
首先我见一个文件,写一些内容用于排序,开始是这样的内容显示
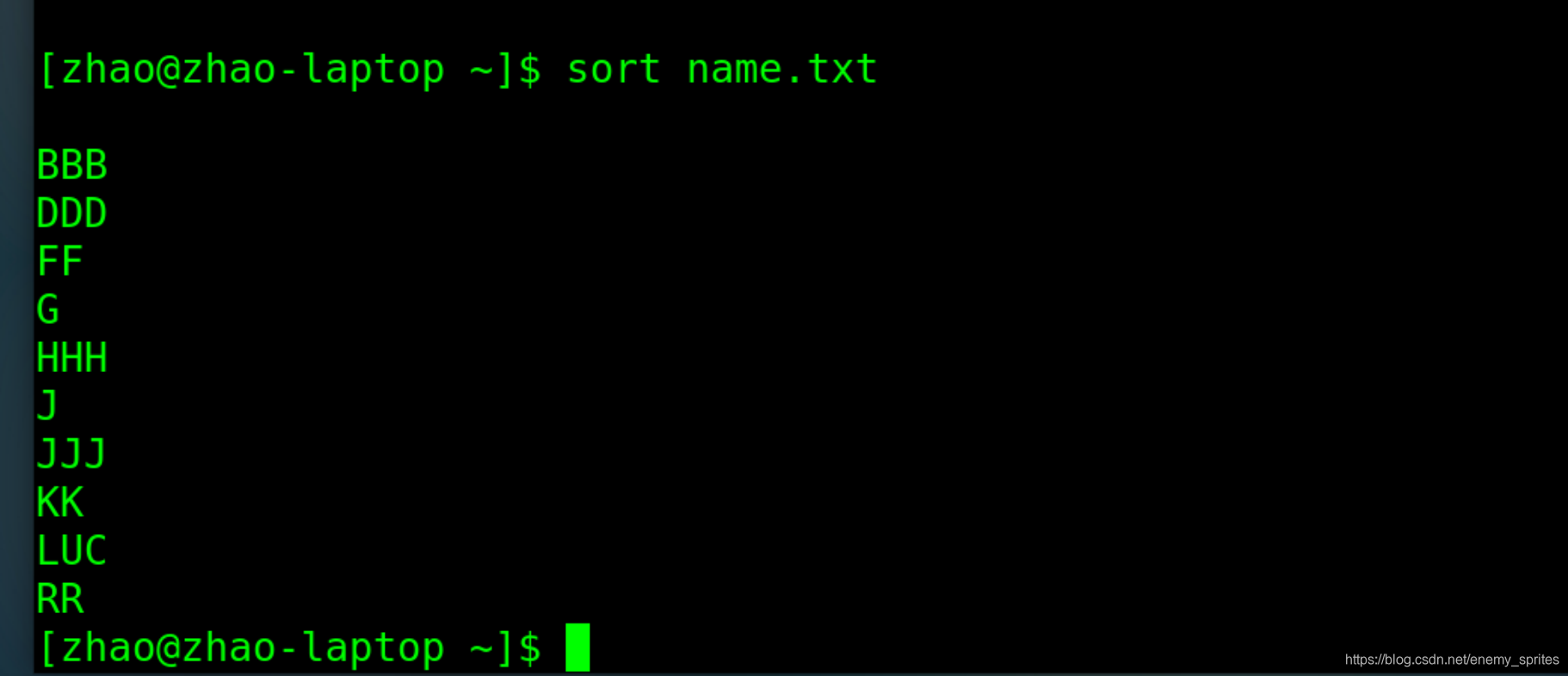
 使用sort name.txt排序后,按照首字母英文字母进行排列
使用sort name.txt排序后,按照首字母英文字母进行排列
但是在cat 一下name.txt 你会发现内容顺序没有变,也就是说单独运行sort只会讲排序的内容显示在终端上,并不会改变文件内容,那如果想要将排序后的内容写入新文件呢?
-o参数:将排序后的内容写入新文件
o是output的首字母,表示 输出
就是将排序结果输出到文件中
sort -o name_sorted.txt name.txt
cat name_sorted.txt
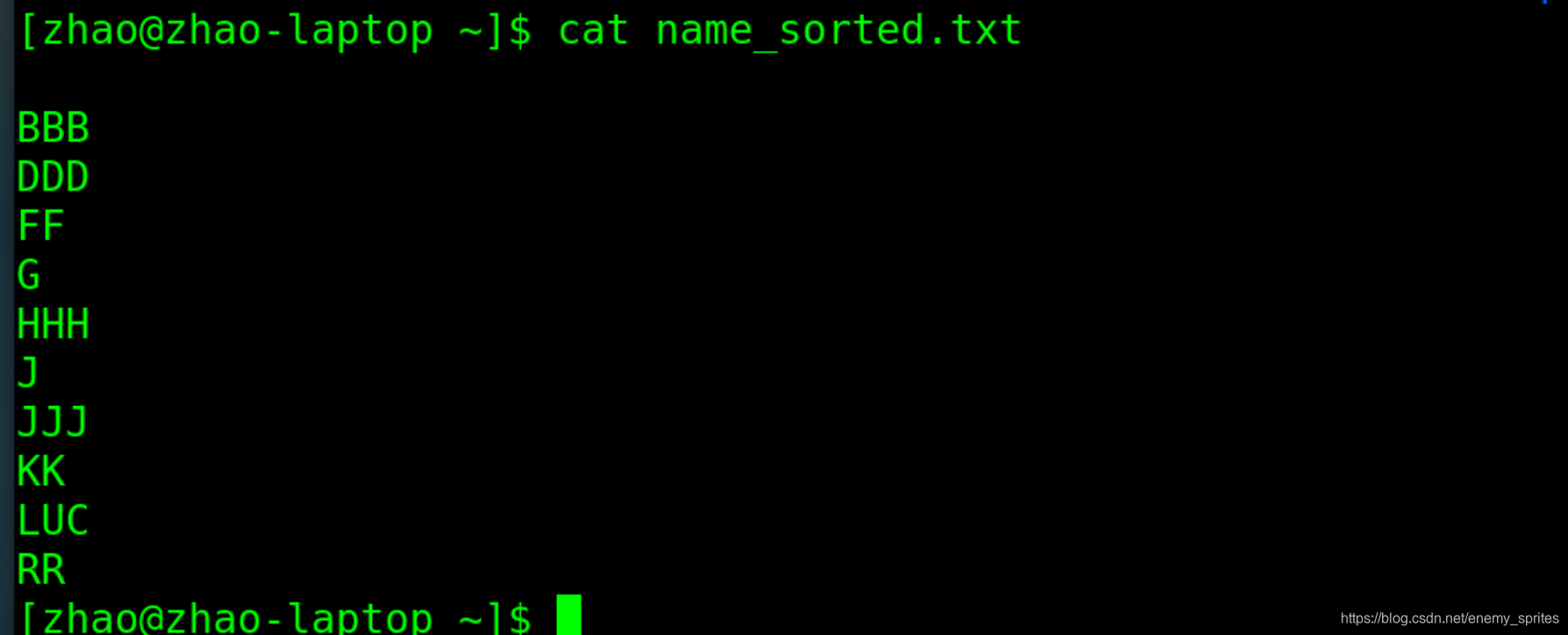 发现新文件里写入了排序成功的内容
发现新文件里写入了排序成功的内容
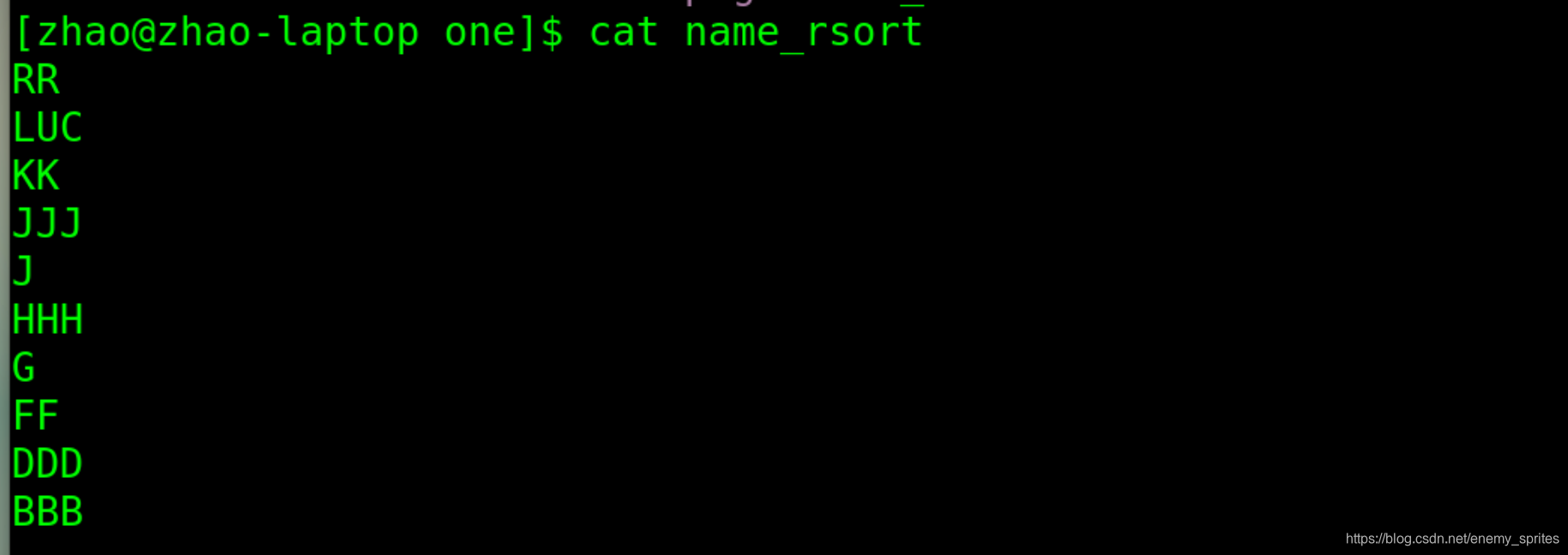
-r 参数:倒叙排列
r是reverse的缩写,是 相反 反面 的意思
与普通仅用sort正好是相反的
sort -r name.txt

-R参数:随机排序
R是英语random的首字母,表示 随机性 任意的
-R参数比较无厘头,因为他会让sort命令排序变为随机
就是任意排序,每次都不一样
sort -R name.txt
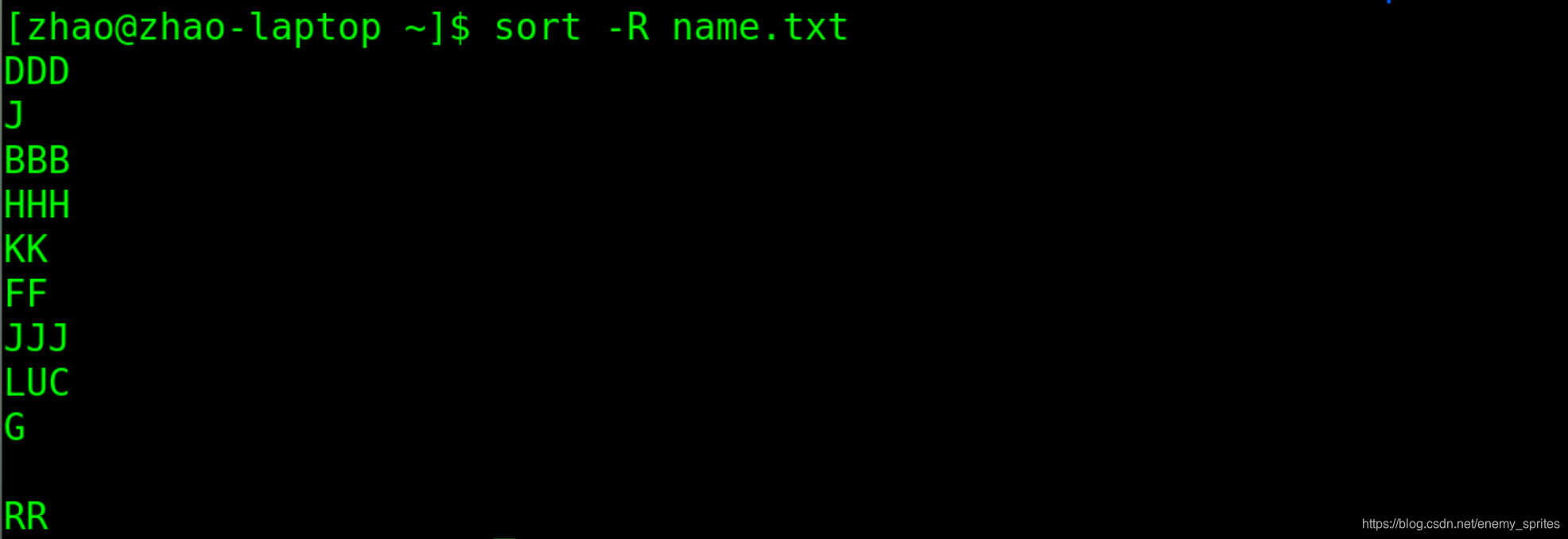
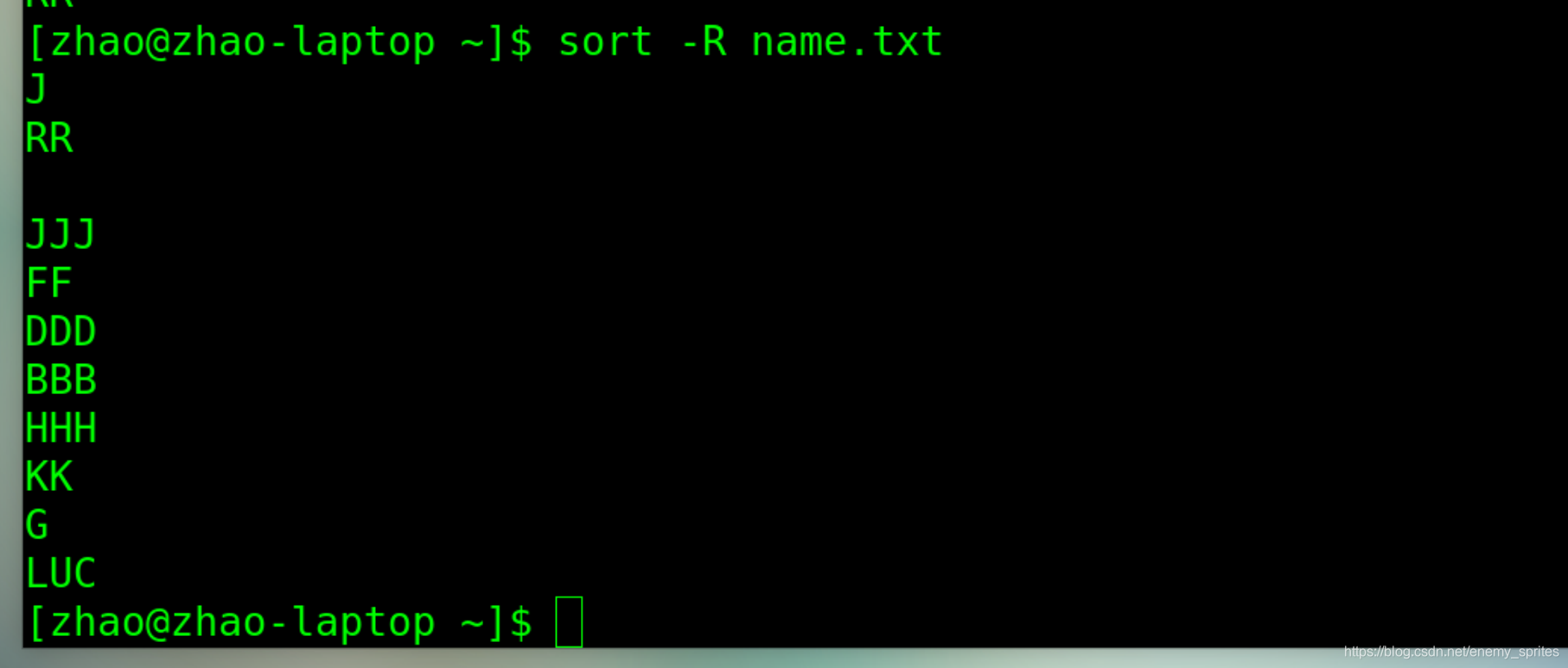
两次使用-R参数对name.txt文件进行排序,排序结果是随机不同的
-n 参数:对数字排序
默认的,仅用sort命令的时候,是不区分字符是否是数字的
会把这些数字看成字符串,安装1-9的顺序排列
例如138会排在25前边,因为1排在2前边
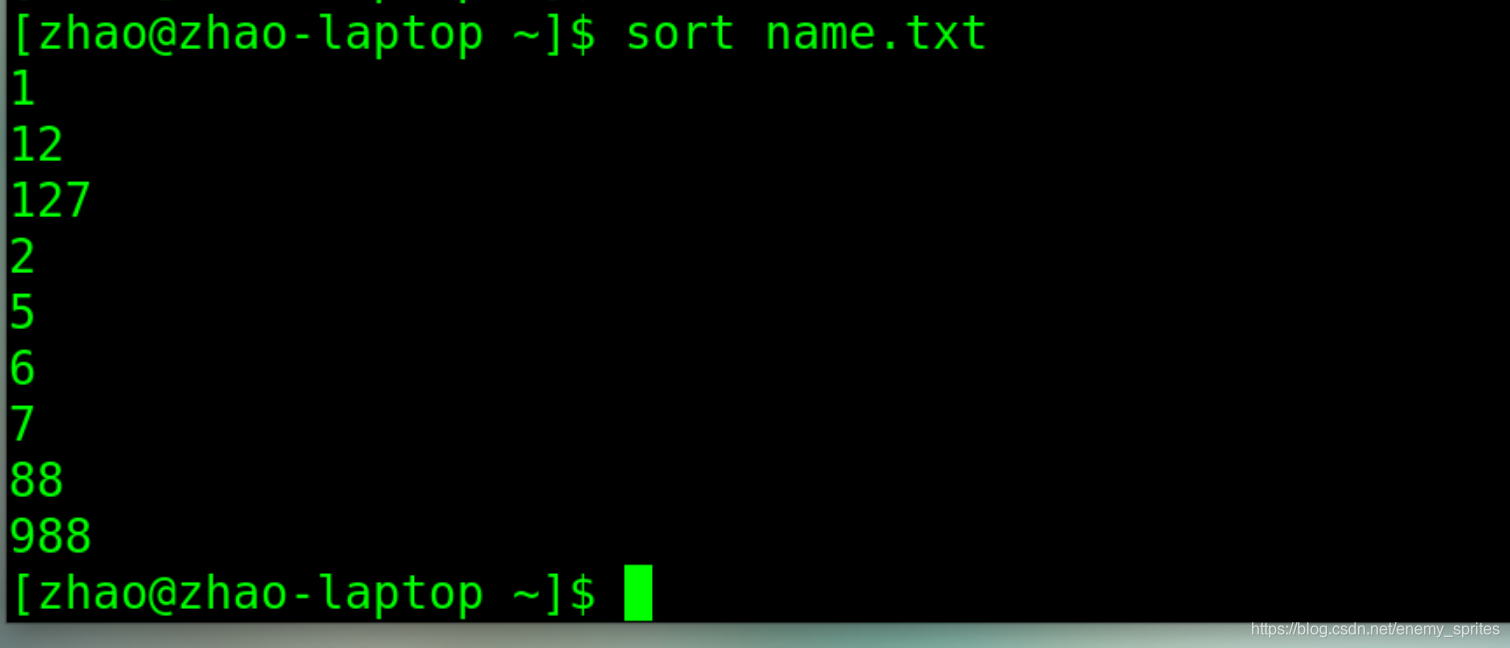
那么怎么办呢
那就使用-n参数
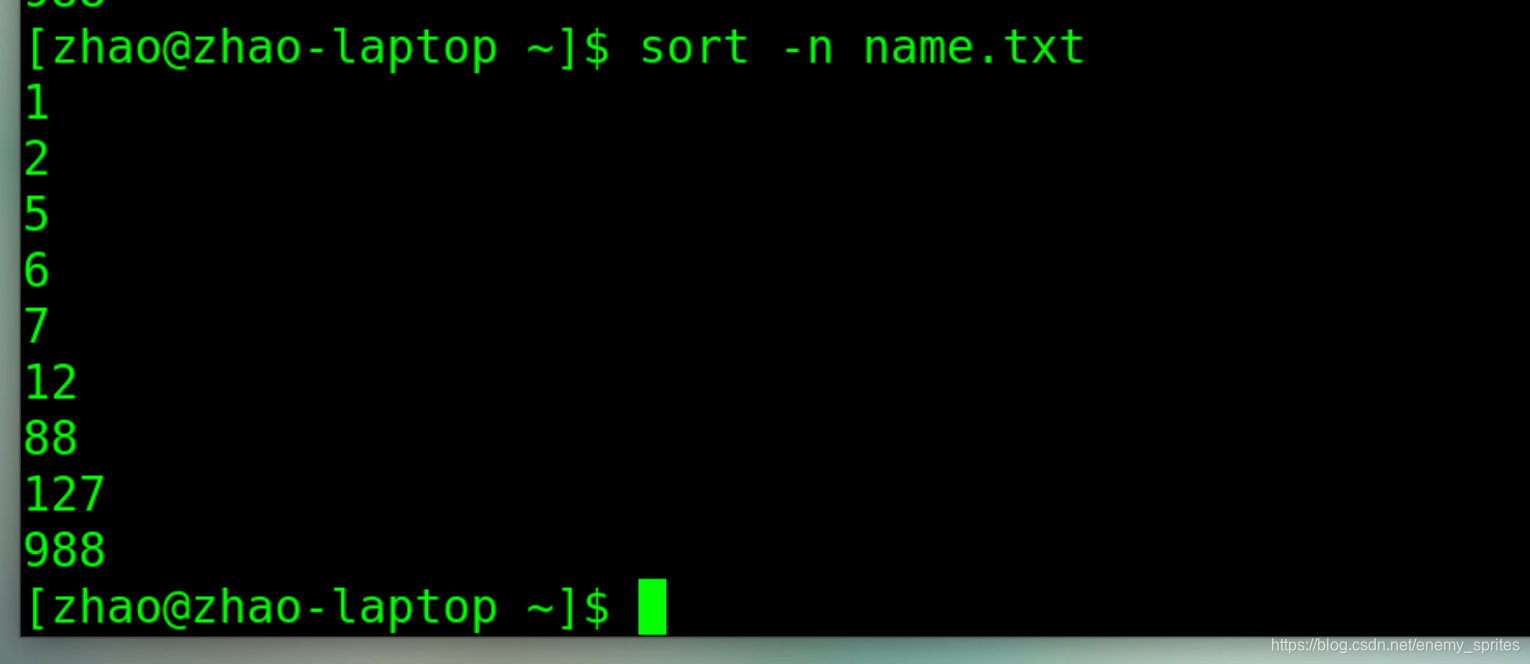
给你想要的
wc命令:文件统计
wc呢,是word count的缩写 word是 单词 的意思 count是计数的意思,不是公共厕所的意思,当然你也可以这么记,去公厕就能统计文件
看上去wc命令是统计单词数目,但是wc的功能不仅仅如此
wc命令还可以统计行数,字符数,字节数等
wc name.txt
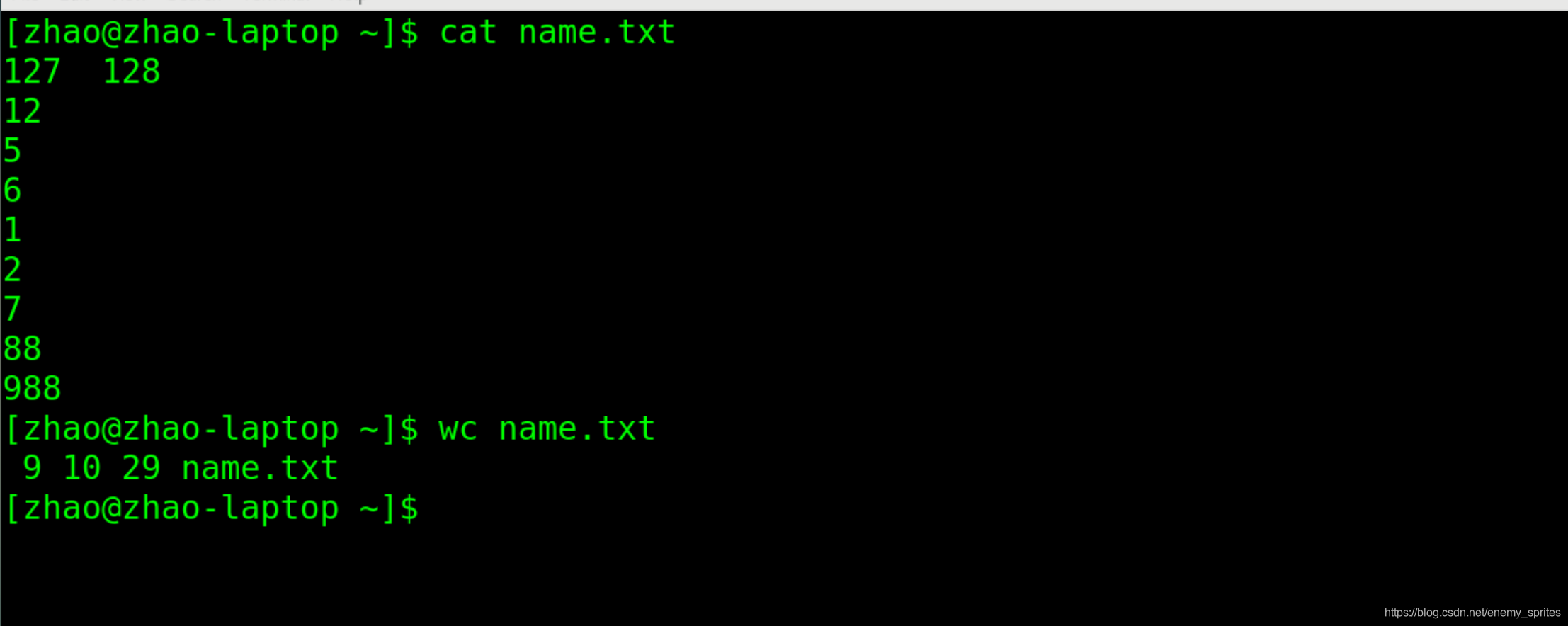
后边的文件名大家都能明白,但是前三个是什么呢?
第一个9:是行数(newline counts) 计数行
第二个10:是单词数(word counts)计数单词数
第三个29:是字节数(byte counts)计数字节数
我们来开一些man手册,
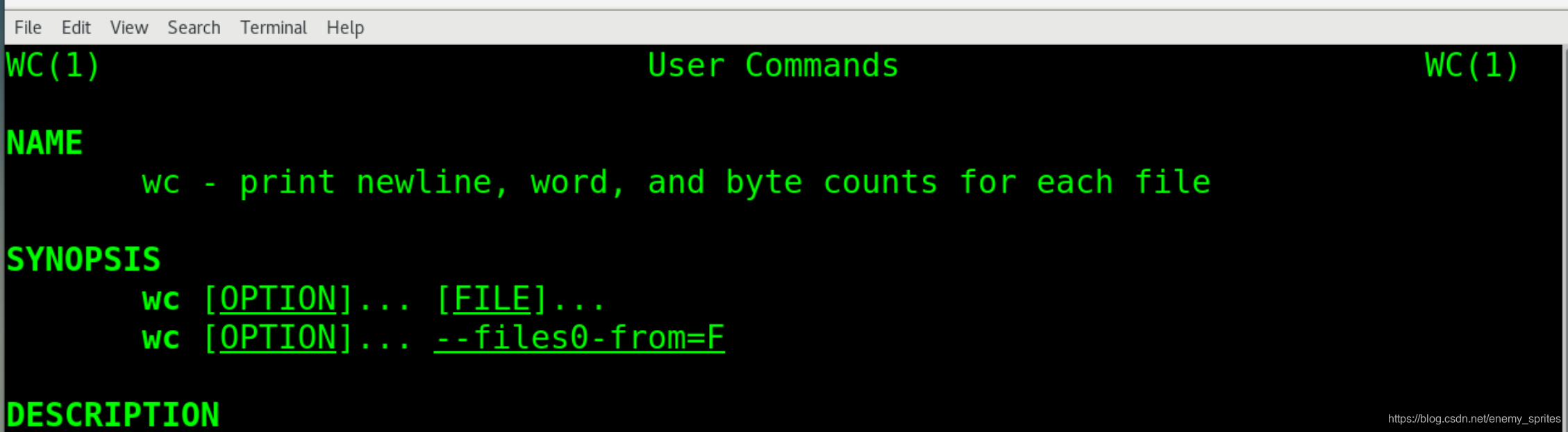
打印每个文件的行数,单词数,字节数
还可以差多个文件
wc name_sorted_txt name.txt
之前排序的两个文件

-l参数:统计行数
为了只统计行数,我们加入-l参数
wc -l name.txt
只统计name.txt 中的文本行数
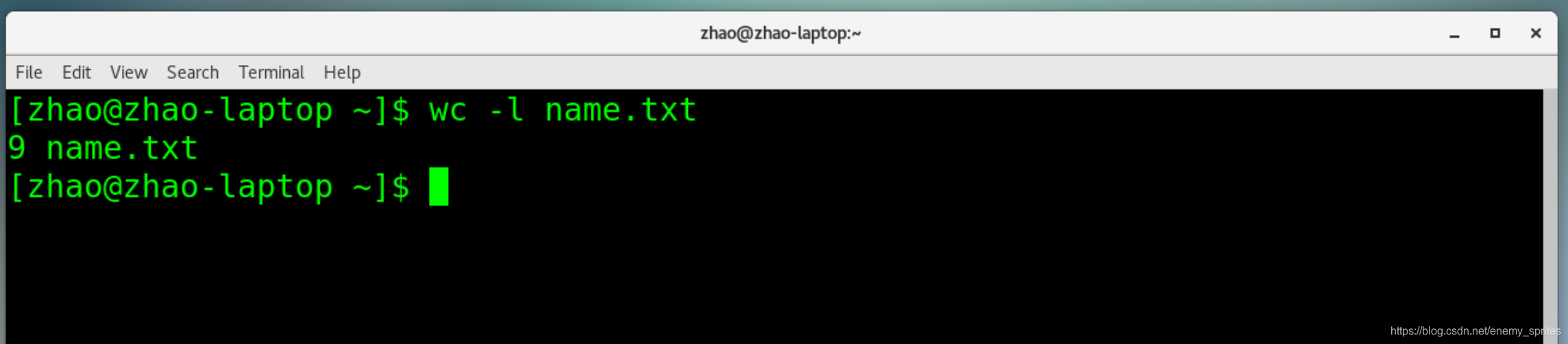
里边就9行,没毛病
-w参数:统计单词数
如果想只统计单词数,那么
wc -w name.txt
 -w参数用于统计用空格隔开的字符串数目
-w参数用于统计用空格隔开的字符串数目
-c参数:统计字节数
c 英语characer的缩写,字节
wc -c name.txt
 统计了包含换行符的所有字符数
统计了包含换行符的所有字符数
-m参数:统计字符数
wc -m name.txt

-uniq命令:删除文件中重复的内容
uniq是英语unique的缩写,表示 独一无二 的
我们创建一个文件来使用
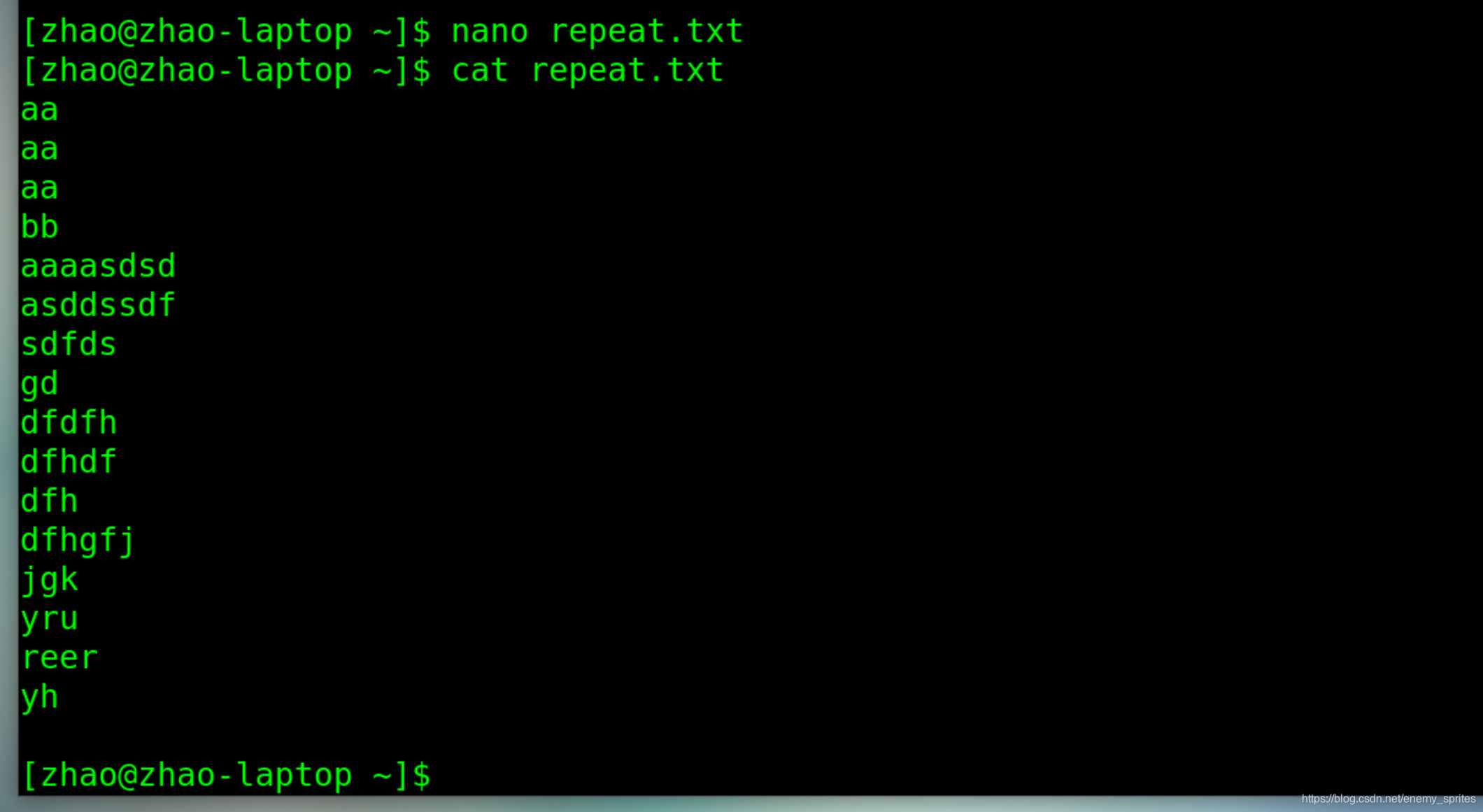
可见上图有三个aaa
uniq命令有点 呆 ,只能将连续的重复行变为一行
unqi repeat.txt
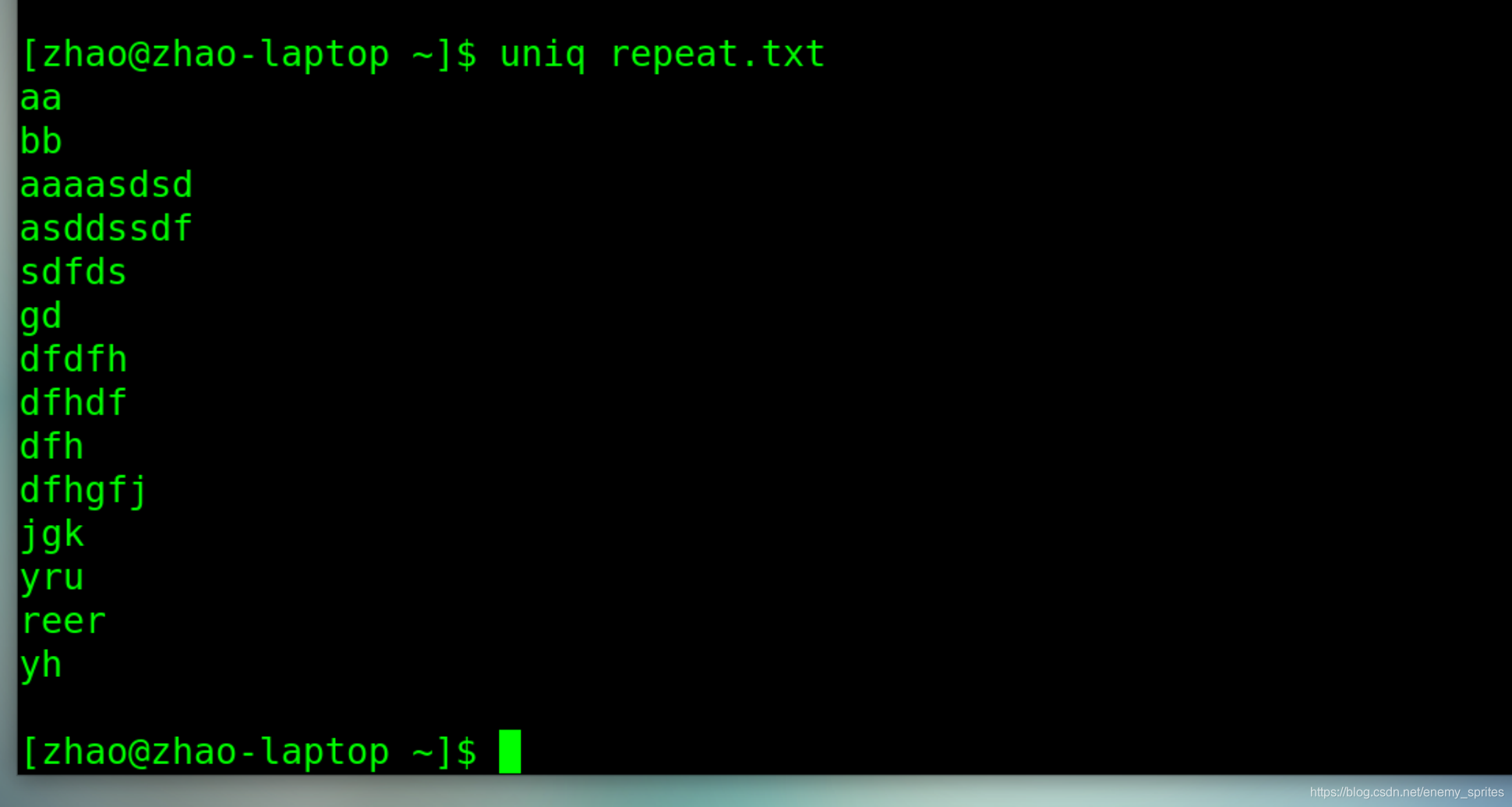
三个连续的aaa变为了一个
和sort命令一致,uniq只是把修改的修改打印出来,并不能改变源文件
但是sort处理后的文件名在前参数,uniq在后参数
uniq repeat.txt unique.txt
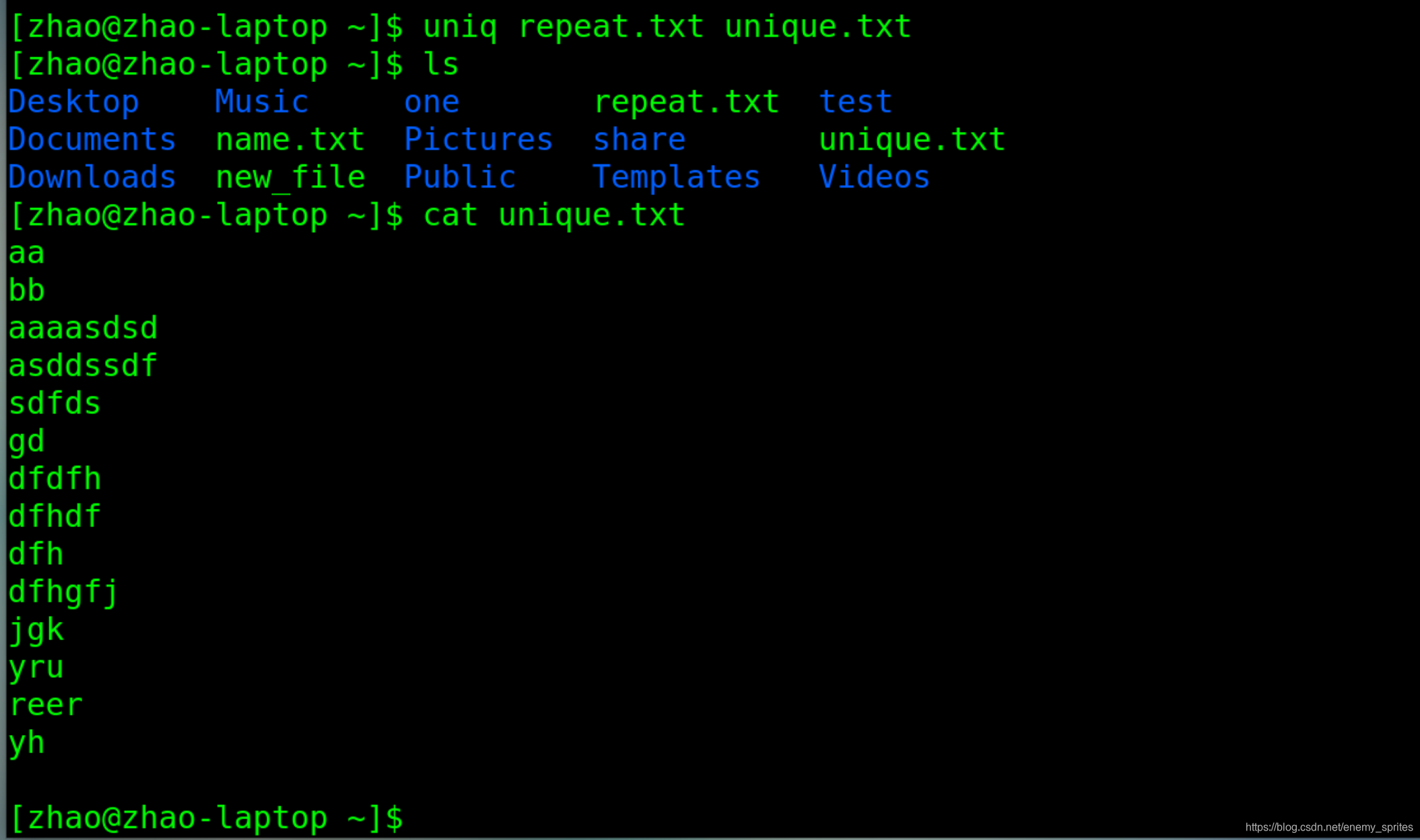
-c参数:用于统计重复的行数
c是count的缩写,表示统计计数
uniq -c repeart.txt
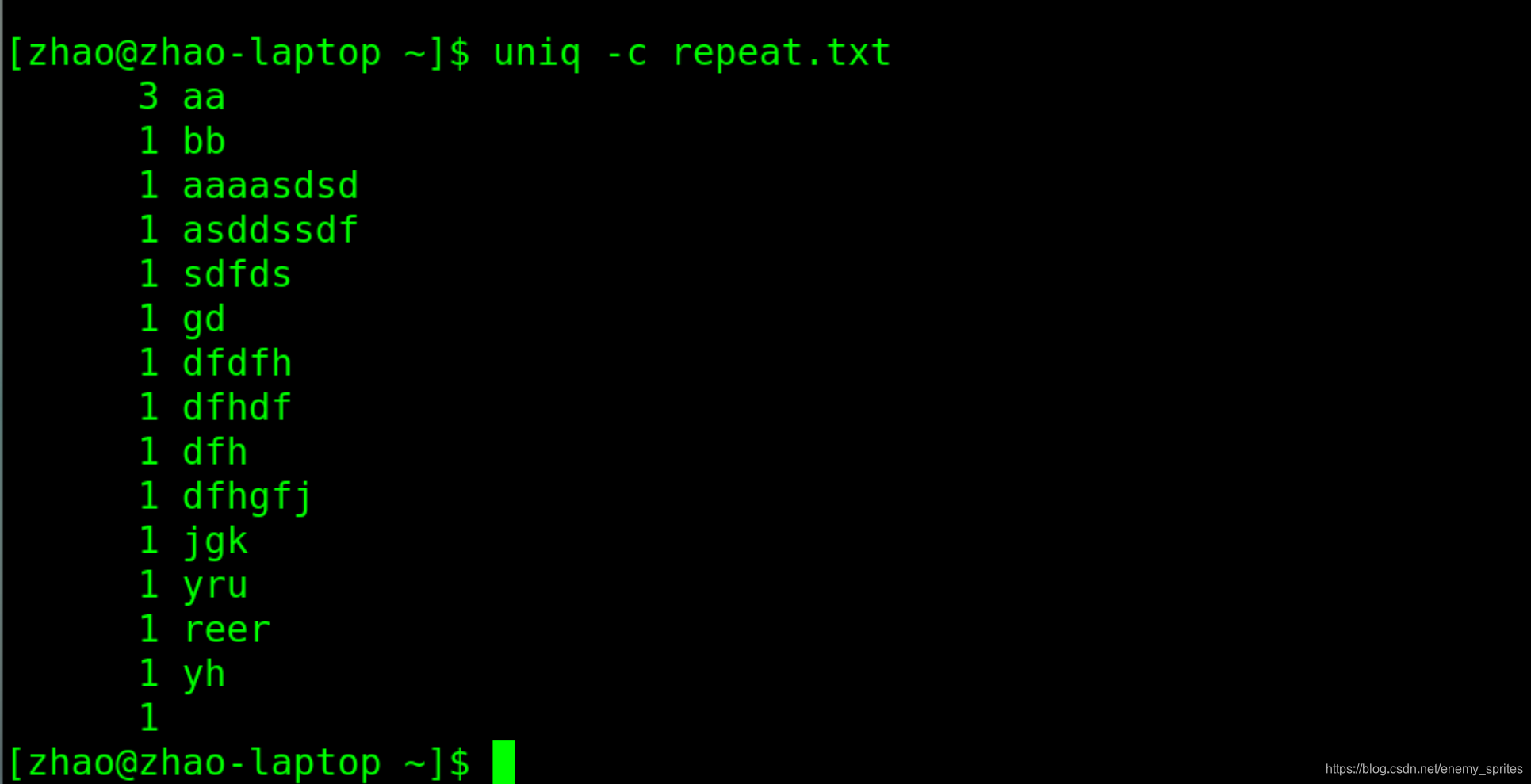
-d参数:只统计重复行的值
d是duplicated的缩写,表示 重复的
uniq -d repeat.txt

cut命令:剪切文件的一部分内容
cut是英语 剪切 的意思
cut命令用于对文件的每一行进行处理
-c参数:根据字符数来剪切
c是character的缩写,表示 字符
如果我们想要name.txt 的每一行只保留第二到第四个字符
cut -c 2-4 repeat.txt
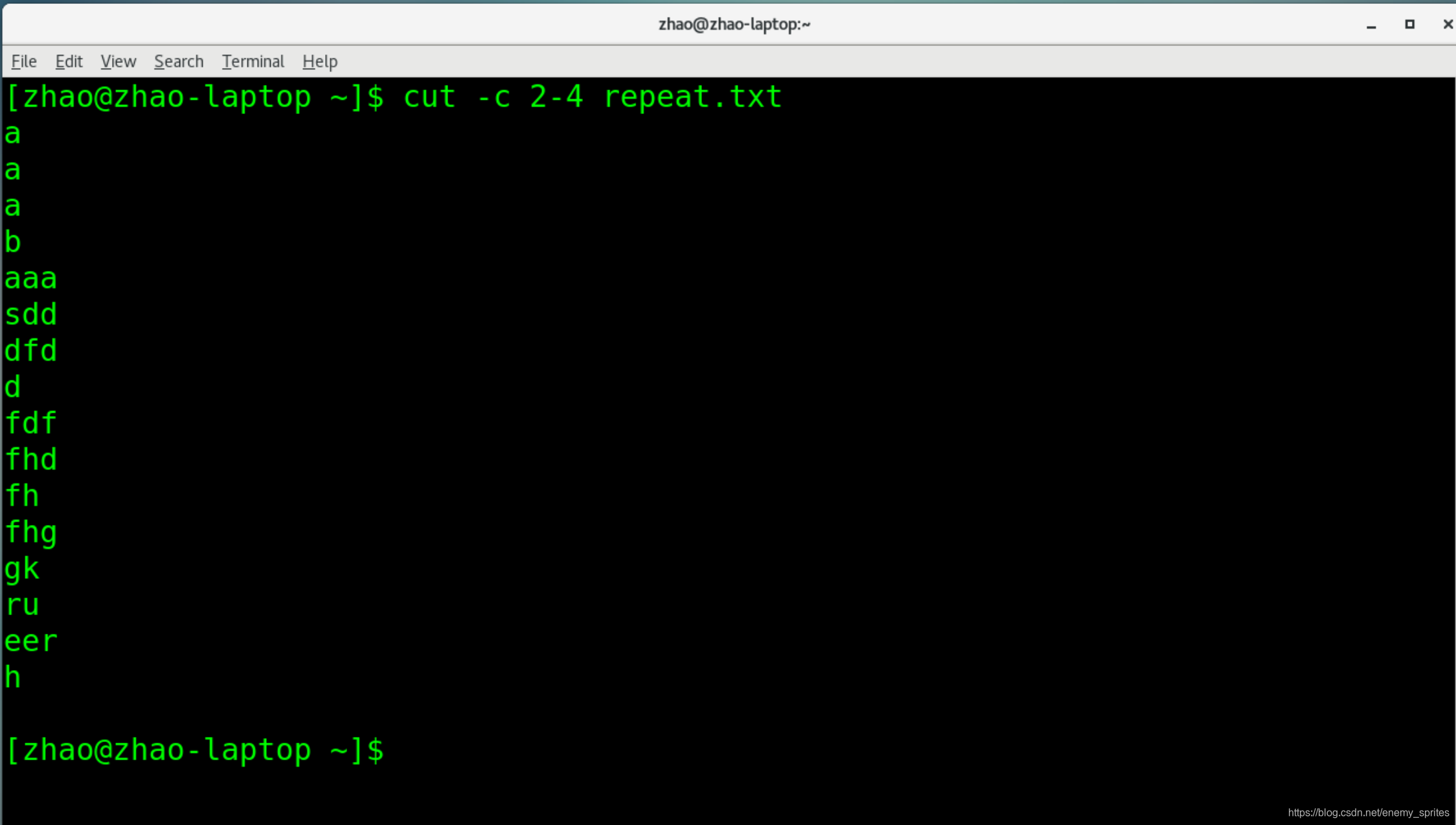
总结
grep工具应该是最常见的在文件中查找关键字的工具了
grep命令可以通过正则表达式来查找关键字
一般正则表达式会比较难记,但是很强大
我们可以调用egrep,其等价于grep -E
使用-i参数: 使grep方法大小写不敏感
使用-n参数:显示行号
使用-v参数:不显示关键字所在的行
使用-r参数:在其所有子目录或文件下查找
sort命令用于为文件中的行 按字母顺序排序
使用-n参数可以按照数字排序
使用-r参数倒叙
使用-R参数随机排序
使用-o参数将修改后的内容写入一个新文件
wc命令用于对文件的统计
使用-l参数 :统计行数
使用-w参数:统计单词数
使用-c参数 :统计字节数
使用-m参数:统计字符数
uniq命令:去重
使用-c参数:用于统计重复的行数
使用-d参数:只统计重复的行的值
cut命令:剪切文件的部分内容
使用-c参数,根据子读书来剪切
















 2527
2527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









