



 本文介绍了K-means聚类算法的具体流程,包括其目的、应用和缺点。重点讨论了如何通过K-means++优化初始聚类中心,以提高算法性能。文章还提到K-means在社区检测、图像处理和城市规划等领域的实际应用。
本文介绍了K-means聚类算法的具体流程,包括其目的、应用和缺点。重点讨论了如何通过K-means++优化初始聚类中心,以提高算法性能。文章还提到K-means在社区检测、图像处理和城市规划等领域的实际应用。
目录
聚类模型(Clustering):
- 目的:聚类是一种无监督学习方法,其目的是将数据点分组,使得同一组内的数据点彼此相似,而不同组的数据点尽可能不相似。
- 应用:聚类用于探索性数据分析,如市场细分、社交网络分析、基因数据分析等。
- 例子:K-均值(K-means),DBSCAN,层次聚类(Hierarchical Clustering)等。
- 具体过程
-
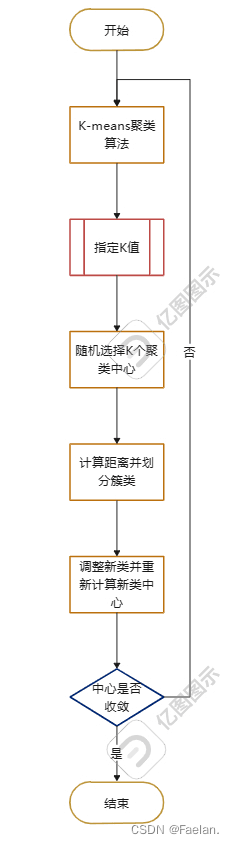

缺点:
- 要求用户必须事先给出要生成的簇的数目k
- 对初值敏感,受单一值影响大
- 对于孤立点数据敏感
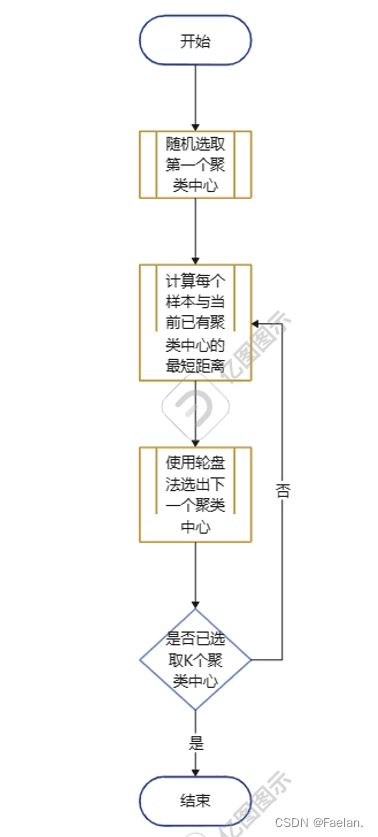
二、优化kmeans
采用K-means++算法
中心原则:初始的聚类中心之间的相互距离要尽可能的远。
三、总结
当数模比赛中出现类似社区检测,图像处理,城市规划,风险管理等情境,使用kmeans聚类方法


















 8964
8964




 到【灌水乐园】发言
到【灌水乐园】发言









